A题和B题我们小组都做了,最终A题二等奖,B题一等奖。总结写在最前面,泰迪杯技能赛不像数学建模比赛,所有的问题具有引导性,但一天完成建模和论文也不是一件容易的事,如果想要通过Python实现分析,需要对pandas,numpy,matplotlib,pyecharts等相关的库非常熟悉,以下是我们小组对于B题的部分代码实现。
任务一 数据探索与清洗
分别对短期客户产品购买数据“short-customer-data.csv”(简称短期数据)和长期客户资源信息数据的训练集“long-customer-train.csv”(简称长期数据)进行数据探索与清洗。
任务 1.1 数据探索与预处理
(1) 探索短期数据各指标数据的缺失值和“user_id”列重复值,删除缺失值、重复值所在行数据。请在报告中给出处理过程及必要结果,完整的结果保存到文件“result1_1.xlsx”中。
import pandas as pd
import numpy as np #导入相关的库
df1_1 = pd.read_csv("short-customer-data.csv")
df1_1["user_id"].duplicated().sum() #统计重复次数
df1_1 = df1_1.drop_duplicates(subset="user_id", keep='last', ignore_index=True) #假设客户产品购买与最后一次活动有关,保留最后一次user_id出现的数据
df1_1.isnull().sum() #统计缺失值
df1_1 = df1_1.dropna() #删除缺失值
df1_1.to_excel("result1_1.xlsx")
(2) 长期数据中的客户年龄“Age”列存在数值为-1、0 和“-”的异常值,删除存在该情况的行数据;“Age”列存在空格和“岁”等异常字符,删除这些异常字符但须保留年龄数值,将处理后的数值存于“Age”列。请在报告中给出处理过程及必要结果,完整的结果保存到文件“result1_2.xlsx”中。
df1_2 = pd.read_csv("long-customer-train.csv")
for i in range(len(df1_2)):
df1_2["Age"][i] = df1_2["Age"][i][:2] #保留年龄数值
dic1_2 = dict(df1_2["Age"].value_counts()) #统计各年龄出现的次数保存为字典
import operator
sorted(dic1_2.items(),key=operator.itemgetter(0)) #依据键的大小排序

df1_2 = df1_2[df1_2["Age"]>="18"] #删除-1,0,“-”的异常值只需筛选出>=18的数据即可
df1_2.to_excel("result1_2.xlsx")
任务 1.2 对短期数据中的字符型数据进行特征编码,如将信用违约情况{‘否’,‘是’}编码为{0,1}。请在报告中给出处理思路、过程及必要结果,完整的结果保存到文件“result1_3.xlsx”中。
df1_2["y"] = df1_2["y"].map({"yes":1, "no":0})
同样可以用LabelEncoder,pandas内置factorize函数等编码,但因为我们不太了解对应关系,所以这里我们采用map映射函数,以标签“y”为例,不再重复其他特征的编码。
任务 2 产品营销数据可视化分析
任务 2.1 计算短期数据所有指标之间的相关性,绘制相关系数热力图,并在报告中对结果进行必要分析。
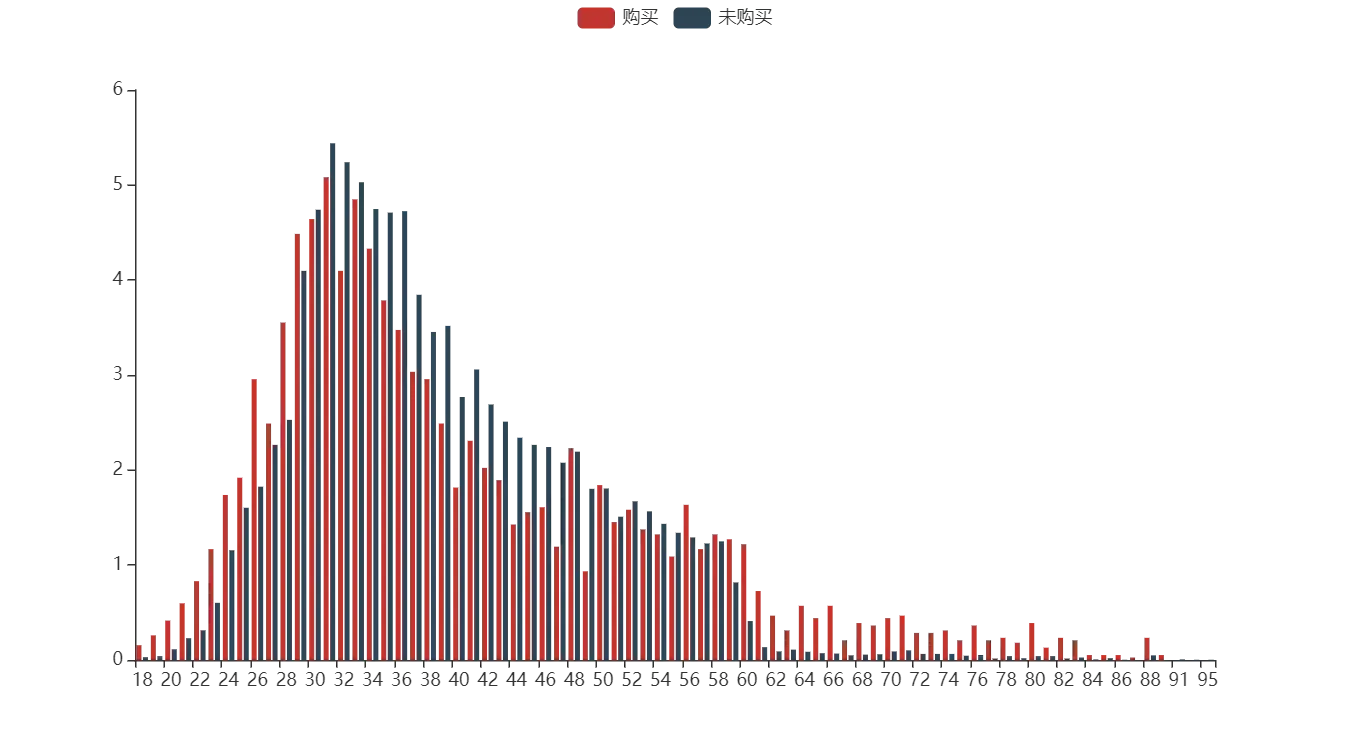
任务 2.2 在同一画布中,绘制反映两种产品购买结果下不同年龄客户量占比的分组柱状图,x 轴为年龄,y 轴为占比数值,并在报告中对结果进行必要分析。
df2_2 = df1_2
#对是否购买产品分别处理
df2_2_01 = df2_2[df2_2["y"] == 0]#未购买
df2_2_02 = df2_2[df2_2["y"] == 1]#购买
dic2_2_01 = dict(df2_2_01["age"].value_counts()) #统计各年龄出现的次数并保存为字典
for i in dic2_2_01.keys():
dic2_2_01[i] = dic2_2_01[i]/len(df2_2_01)*100 #计算百分比
dic2_2_02 = dict(df2_2_02["age"].value_counts()) #统计各年龄出现的次数并保存为字典
for i in dic2_2_02.keys():
dic2_2_02[i] = dic2_2_02[i]/len(df2_2_02)*100 #计算百分比
x2_2 = list(set(dic2_2_01.keys()) | set(dic2_2_02.keys())) #取年龄的并集作为柱状图的x轴
for i in x2_2:
dic2_2_01[i] = dic2_2_01.get(i,0)
dic2_2_02[i] = dic2_2_02.get(i,0)
#假如购买产品的客户年龄中没有95岁的,将其百分比置为0
dic2_2_01 = dict(sorted(dic2_2_01.items(),key=operator.itemgetter(0)))
dic2_2_02 = dict(sorted(dic2_2_02.items(),key=operator.itemgetter(0)))
#按照年龄排序以对应x轴
#pyecharts绘图
from pyecharts.charts import Bar
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType
from pyecharts import options as opts
c = (
Bar()
.add_xaxis(x2_2)
.add_yaxis("购买", list(dic2_2_02.values()))
.add_yaxis("未购买", list(dic2_2_01.values()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts={}
)
)
c.render_notebook()
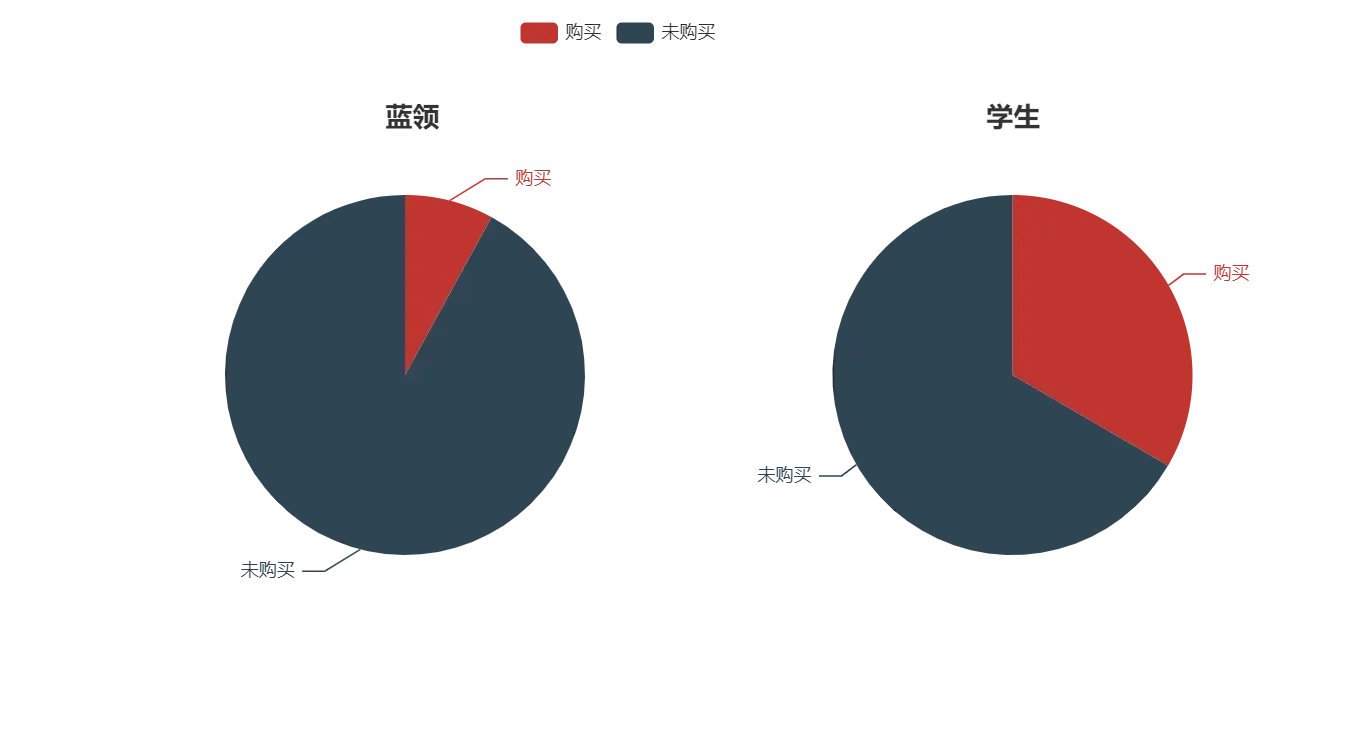
任务 2.3 在同一画布中,绘制蓝领(blue-collar)与学生(student)的产品购买情况饼图,并设定饼图的标签,显示产品购买情况的占比。
任务 2.4 以产品购买结果为 x 轴、拜访客户的通话时长为 y 轴,绘制拜访客户的通话时长箱线图,并在报告中对结果进行必要分析。
import matplotlib.pyplot as plt
import seaborn as sns
#使图片清清晰
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
#显示中文字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.figure(figsize = (4,5))
sns.boxplot(x = df2_2["y"], y=df2_2["duration"],width = 0.4)
plt.savefig("pic2_4.png",dpi = 1000)

任务 3 客户流失因素可视化分析
整体与任务2.2思路相同,这里展示仅展示绘图结果
任务 3.1 在同一画布中,绘制反映两种流失情况下不同年龄客户量占比的折线图,x 轴为年龄,y 轴为占比数值。

任务 3.2 在同一画布中,绘制反映两种流失情况下客户信用资格与年龄分布的散点图,x 轴为年龄,y 轴为信用资格。

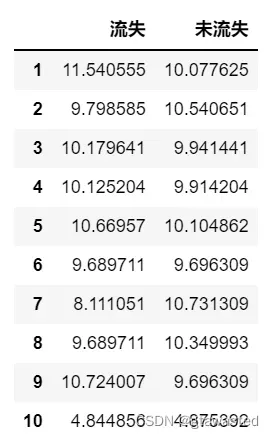
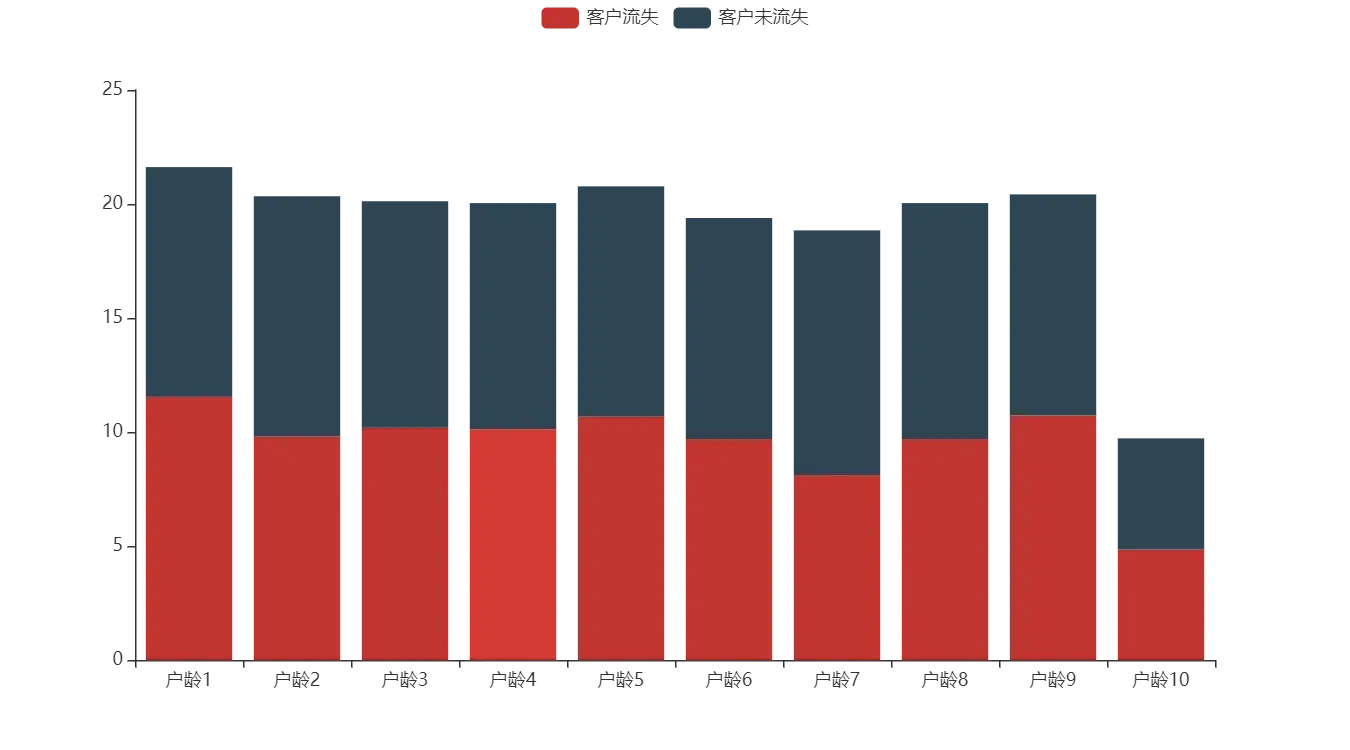
任务 3.3 构造包含各账号户龄在不同流失情况下的客户量占比透视表(详见表 4),并在同一画布中绘制反映两种流失情况的客户各账号户龄占比量的堆叠柱状图,x 轴为客户的户龄,y 轴为占比量。
任务 3.4 新老客户各资产阶段的客户流失情况分析。
(1) 按照表 5 和表 6 对账号户龄和客户金融资产进行划分,并分别进行特征编码作为新的客户特征,其中客户状态存于“Status”列,资产阶段存于“AssetStage”列,编码结果保存到文件“result3.xlsx”中。
df3_4 = df1_2.copy()
df3_4["Status"] = "新客户" #初始化
index_stable = (df3_4["Tenure"]> 3) &(df3_4["Tenure"]<=6) #按照要求创建索引
index_old = df3_4["Tenure"]>6
df3_4["Status"][index_stable] = "稳定客户"
df3_4["Status"][index_old] = "老客户"
df3_4["AssetStage"] = "低资产" #初始化
index_midlow = (df3_4["Balance"]>50000) &(df3_4["Balance"]<=90000)
index_midup = (df3_4["Balance"]>90000) &(df3_4["Balance"]<=120000)
index_high = (df3_4["Balance"]>120000)
df3_4["AssetStage"][index_midlow] = "中下资产"
df3_4["AssetStage"][index_midup] = "中上资产"
df3_4["AssetStage"][index_high] = "高资产"
df3_4.to_excel("result3.xlsx")
(2) 统计新、老客户在各资产阶段中流失的客户量,在同一画布中绘制热力图,热力图颜色的最大和最小取值设为 1300 和 100,并在报告中对结果进行必要分析。
df3_4_01 = df3_4[df3_4["Exited"] == 1]
df3_4_02 = pd.crosstab(df3_4_01['AssetStage'],df3_4_01["Status"],margins=True,margins_name='总和').iloc[:-1,:-1] #制作列联表
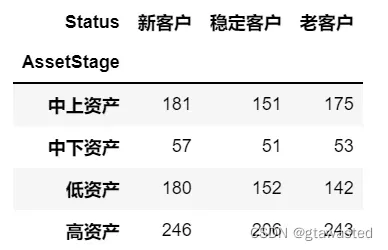
import seaborn as sns
f, ax = plt.subplots(figsize=(6, 6))
sns.heatmap(df3_4_02,cmap="YlGnBu",annot=True,fmt='.0f',square = True,vmin = 100,vmax = 1300)
plt.savefig("pic3_4.png",dpi = 1000)

任务 4 特征构建
基于长期数据提取影响客户流失的因素,构建与银行客户长期忠诚度相关的特征,将结果保存到文件“result4.xlsx”中。
(1) 根据表 7,构建新老客户活跃程度的特征,并将结果存于“IsActiveStatus”列。
df4_1 = df3_4
df4_1["IsActiveStatus"] = 0 #初始化
index_new1 = (df4_1["Status"] == "新客户") & (df4_1["IsActiveMember"] == 1)
index_stable1 = (df4_1["Status"] == "稳定客户") & (df4_1["IsActiveMember"] == 1)
index_stable0 = (df4_1["Status"] == "稳定客户") & (df4_1["IsActiveMember"] == 0)
index_old1 = (df4_1["Status"] == "老客户") & (df4_1["IsActiveMember"] == 1)
index_old0 = (df4_1["Status"] == "老客户") & (df4_1["IsActiveMember"] == 0)
df4_1["IsActiveStatus"][index_new1] = 3
df4_1["IsActiveStatus"][index_stable1] = 4
df4_1["IsActiveStatus"][index_stable0] = 1
df4_1["IsActiveStatus"][index_old1] = 5
df4_1["IsActiveStatus"][index_old0] = 2
(2) 根据表 8,构建不同金融资产客户活跃程度的特征,并将结果存于“IsActiveAssetStage”列。
(3) 根据表 9,构建不同金融资产信用卡持有状态的特征,并将结果存于“CrCardAssetStage”列。
任务 5 银行客户长期忠诚度预测建模
长期数据存在“Exited”特征分布不均衡、各项数值分布跨度大等现象。体现为:未流失客户量是已流失客户量的 3 倍以上;客户信用资格最大数值达到 25万,而客户活动状态则为 0 和 1 等。考虑上述现象,对银行客户长忠诚度进行预测。
(1) 选取适当的客户特征,建立客户长期忠诚度预测模型。客户特征可以从客户信用资格、性别、年龄、户龄金融资产、客户购买产品数量、持有信用卡状态、活动状态和个人年收入等指标中直接选取,也可以参照任务 4 构建。在报告中给出特征选取的依据、建立预测模型的思路和过程。
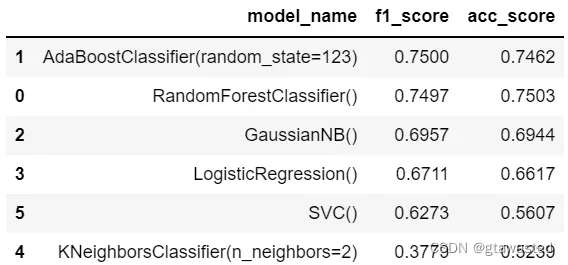
(2) 使用混淆矩阵、F1 Score 等方法对预测模型进行评估,在报告中给出评估的方法和结果。
(3) 对“long-customer-test.csv”测试数据进行预测,将全部预测结果以表 10形式保存为文件“result5.xlsx”,其中 0 表示客户没有流失,1 表示客户流失。并将表 11 中的 5 个客户 ID 的预测结果在报告中列出。
data = df4_1.iloc[:,1:-5]
#绘制特征CreditScore值分布的箱线图
plt.figure(figsize = (4,5))
sns.boxplot(y=data["CreditScore"],width = 0.4)
plt.savefig("pic5_1.png",dpi = 1000)

#删除异常值
def three_sigma(x): #传入某变量
mean_value = x.mean() #计算该变量的均值
std_value = x.std() #计算该变量的标准差
rule = (mean_value - 3 * std_value > x) | (x.mean() + 3 * x.std() < x) #处于(mean-3std,mean+3std)区间外的数据为异常值
index = np.arange(x.shape[0])[rule]#获取异常值的行位置索引
index=list(index)
return index
index_drop = three_sigma(data["CreditScore"])
data = data.drop(index_drop)

#导入相关的库
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.metrics import f1_score
#测试集
X = data.drop(columns = "Exited")
y = data["Exited"]
#正负样本比例为4:1,下采样
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=123)
X_resampled, y_resampled = rus.fit_resample(X, y)
#划分比例为4:1的训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=123)
df5 = []
def ModelAssess(model):
## 创建保存模型信息的list
model_list = []
model.fit(X_train,y_train)
## 模型预测
pred = model.predict(X_test)
pred = pred.astype(np.int64)
f_score = round(f1_score(y_test,pred),4)
acc_score = round(accuracy_score(pred,y_test),4)
model_list.append(str(model))
model_list.append(f_score)
model_list.append(acc_score)
df5.append(model_list)
return f_score,acc_score
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=100)
ModelAssess(rfc)
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(random_state=123)
ModelAssess(ada)
from sklearn.naive_bayes import GaussianNB
nb_clf=GaussianNB()
ModelAssess(nb_clf)
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
ModelAssess(lgr)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 2)
ModelAssess(knn)
from sklearn.svm import SVC
svm = SVC(kernel = 'rbf')
ModelAssess(svm)
df5 = pd.DataFrame(df5,columns=['modle_name','f1_score','acc_score'])
df5.sort_values('f1_score',ascending=False)
文章出处登录后可见!