前言
在做深度学习的时候,我们几乎总是会遇到这样一个问题:神经网络模型训练的时候,性能不高?
今天,这篇文章提供了一些在训练过程中提高模型性能的想法或方法。
首先,我们需要知道,影响神经网络模型性能的因素有哪些?
有数据、有模型框架本身、有训练时的超参数(学习率learn rate、批处理大小batch size,训练的轮数epoch)
而所有这些因素,都会影响我们模型的表现
我们了解了背景,让我们看看下面!下面是一些神经网络模型性能优化方法的总结!
1. 改模型框架
**这是终极方法! **当我们使用各种方法都无法提高模型的性能时,可以推测应该是模型本身有问题,所以这个时候换个模型!
2.数据处理
正确划分数据集;
充分利用数据集资源;
规范化数据(消除数据规模差异对模型训练的影响)
…
3.超参数对模型训练的影响
我们一般将数据集分为训练集、验证集和测试集。
训练集和验证集一般都有标注,测试集一般标注,但是我们可能看不到。比如我们在搞一些深度学习竞赛的时候,我们训练模型,选择最好的模型提交。然后比赛平台将通过他们预留的测试集查看我们提交的模型的性能。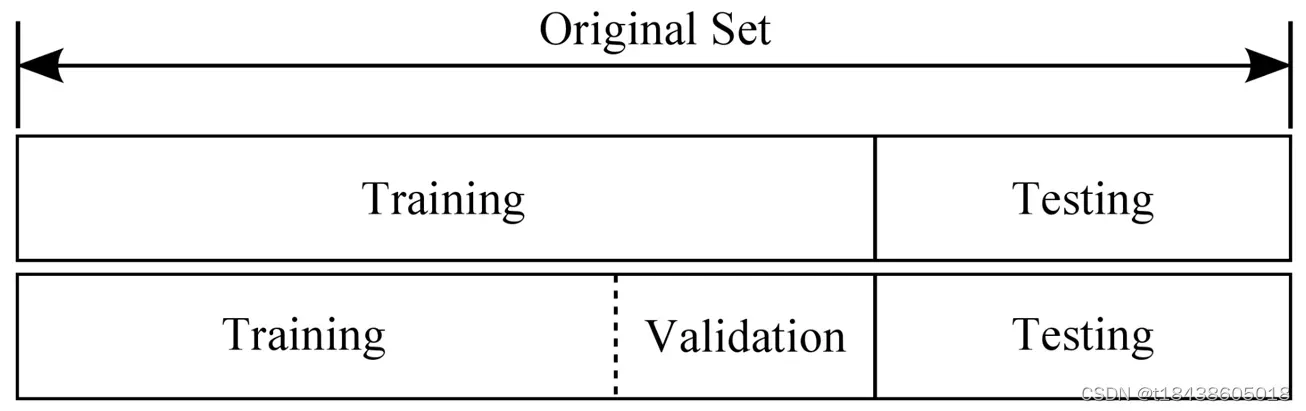

我们分析模型的表现,一般看模型在训练集和验证集上的表现。
最常见的是四条曲线:train loss、valid loss和 train accuracy、valid accuracy
比如我们通过观察train loss和valid loss,可以分析出目前模型的一些状态(欠学习或者过拟合):
a. 如果模型在训练集和验证集上的loss随epoch在一直减少,说明模型还没有收敛,处于欠学习的状态,此时需要继续训练模型,让模型收敛(可以改learn rate、batch size、epoch等超参数)。
b. 如果是下图所示,随着epoch的增大,训练集上loss减小,但验证集上loss先减小后增大。这时,对这些轮训练来说,模型在拐点处(先减小后增大的那个点)性能最佳。选择拐点出的模型作为最优模型。
验证集上loss先减小,后增大。出现这种现象,一般说是模型过拟合了。
Early stopping是一种用于在过度拟合发生之前终止训练的技术。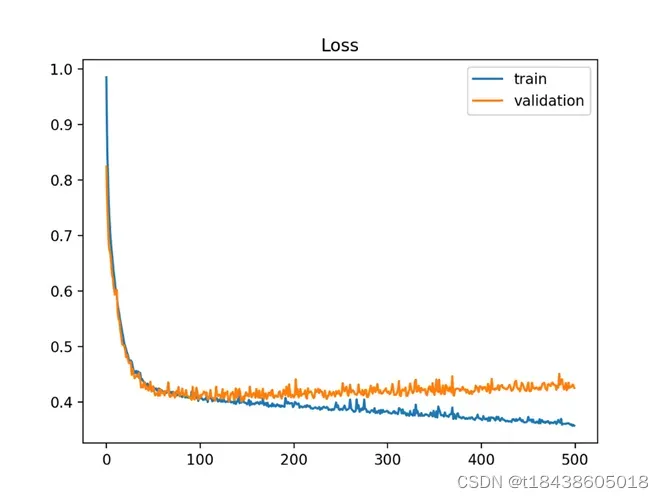
3.1 学习率对模型训练时的影响
模型训练时,首先要经过前向传播,然后计算梯度,再进行反向传播。
学习率越大,模型训练越快。学习越小,模型训练越慢。(如果不清楚,请看下bp反向传播算法推导)
但是,大的学习率和快速的模型训练并不一定意味着模型具有高性能。
如果学习率设置比较大,有可能使得模型跳出了极值点。如下图,一下从a跳到了b,跳过了极值点,而这些极值点有可能是使得模型性能最优的点。
而且还可能由b再跳向c,造成模型的曲线就跌宕的比较厉害。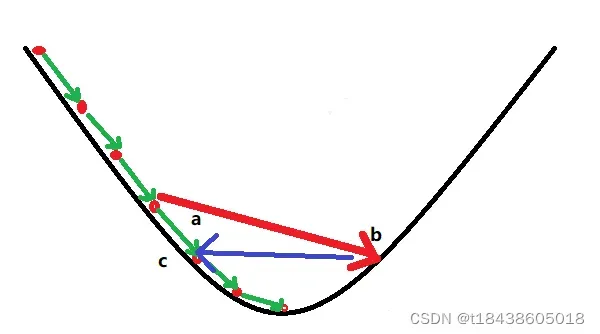
所以,选用合适的学习率也是比较重要的,大家在训练时,可以把学习率设置不同的梯度,比如0.01,0.001,0.0001来看模型的性能。
还有一些优化器。SGD不可以自动调整学习率,Adam优化器可以自动调整学习率。
但无论如何,这些优化器的本质是基于梯度的。一些优化器很好,可能是因为它们可以使梯度下降工作并找到更好的极值点。
3.2 批处理大小对模型训练时的影响
要搞懂,为啥深度学习要用到批处理,一定阅读笔者的神经网络训练中batch的作用(从更高角度理解)
看完之前的博文,我们应该可以得出结论:
batch size过小,训练慢,同时梯度震荡严重,不利于收敛;
batch size过大,训练快,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
批处理大小一般设置成4,8,16,32,64,128……
根据数据集的大小合理设置batch size。
3.3 epoch对模型训练时的影响
如果模型欠学习,增大epoch;
如果模型过拟合,可以采用早停止(Early stopping),避免过度训练模型。
但是在早停中,这一轮模型仅仅意味着它是这几轮训练中更好的模型。
这并不意味着它是最好的模型。
因为此时,梯度下降可能会因为其他超参数的设置等原因而效果不佳。在这种情况下,就会出现过拟合,使得这一轮模型的表现优于其他轮。
3.4 如何判断模型收敛
模型训练的参数直接影响模型的准确性和模型收敛时间。
当模型收敛时,选择的模型是更好的模型。
如何判断模型的收敛性?
- 两次迭代之间的误差loss已经已经很小,可设定一个阈值,当小于这个阈值后,认为模型收敛;
- 两次迭代之间的权重变化很小,可以设置一个阈值。当小于这个阈值时,认为模型收敛;
一般来说,当我们训练并停止移动时,模型可以认为是收敛的。 (但可能是因为梯度不起作用,导致模型收敛)
3.5 模型过拟合时怎么办?
请参考:【机器学习】模型过拟合的处理方法
文章出处登录后可见!