什么是强化学习? (主要强化学习概念)
4.主要的强化学习概念
强化学习与的概念没有太大区别,但具有以下特点:
- 无法预先知道完整的状态转移概率和补偿函数
- 状态集(几乎)是无限的
在前面介绍的中,状态是不连续的(离散的)。然而,应用强化学习的大多数问题都是连续的,具有非常多的可能状态。例如,两个错误配置的空间是
。
4.1 基于模型与无模型(Model-based vs. Model-free)
强化学习无法预知状态转移概率和补偿函数。在MDP中,此状态转移概率和补偿函数称为模型(model)。
如果MDP可以确定状态转移概率和补偿函数,则称为基于模型。如果状态、行为空间较小,并且预先知道状态转移概率和补偿函数。因此,基于model可以解决的问题是有限的。MDP和动态编程相当于基于模型的。
无模型的强化学习称为model-free。现实中的大多数问题都很难用MDP解决,因此最近受到关注的大多数强化学习方法都可以称为model-free。
补偿功能
状态转换函数
4.2 预测(prediction)和控制(control)
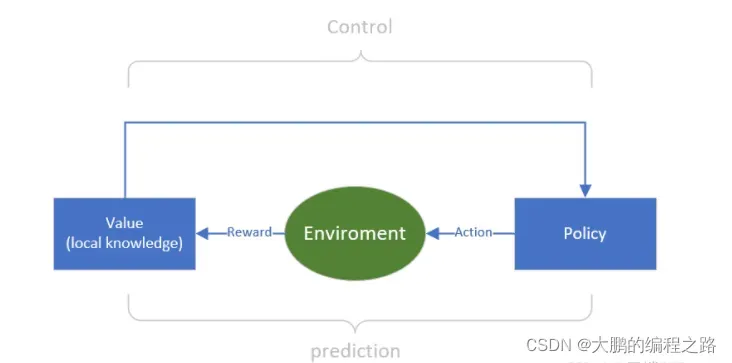
强化学习无法预测模型,所以可以预测状态值函数的值。然后以越来越精确的方式控制其预测。重复这些预测和控制可以说是强化学习。
预测是Agent根据给定的策略,通过与环境的沟通学习状态价值函数。由于强化学习无法确定所有状态的价值,因此对其进行采样。代理将通过体验这些示例来学习环境。控制是根据您通过预测学习的价值函数来学习策略。
预测方法包括蒙特卡罗预测和时间差预测。控制的典型方法是SARSA和Q-learning。
4.3 On-policy vs. Off-policy
on-policy: 生成样本的policy(value function)跟网络更新参数时使用的policy(value function)相同。典型为SARAS算法,基于当前的policy直接执行一次动作选择,然后用这个样本更新当前的policy,因此生成样本的policy和学习时的policy相同,算法为on-policy算法。
off-policy: 生成样本的policy(value function)跟网络更新参数时使用的policy(value function)不同。典型为Q-learning算法,计算下一状态的预期收益时使用了max操作,直接选择最优动作,而当前policy并不一定能选择到最优动作,因此这里生成样本的policy和学习时的policy不同,为off-policy算法。
On-policy意味着强化学习,例如决定行为的策略(policy)和要学习的策略。相反,Off-Policy的方法不同于您所使用的策略和您所学习的策略。
On-policy强化学习是一种积累了大量经验的学习,但如果更新了策略,这些经验将无法用于学习。因此,从数据效率的角度来看,Off-Policy是一个不错的选择。
4.4 主要的强化学习技术
主要的强化学习技术有蒙特卡洛学习((Monte-Carlo learning, MC)、时间差分学习(temporal-difference learning, TD)、Q-learning、策略梯度(policy gradient, PG)、Actor-Critic(AC), A2C(advantage actor-critic), A3C(asynchronous advantage actor-critic) 。
4.4.1 蒙特卡洛学习((Monte-Carlo learning, MC)
让我们从预测和控制的角度来看看蒙特卡洛学习。在 Monte-Carlo 预测中,通过采样学习状态值函数。 经过足够多的情节后,状态值函数将更接近正确答案。
我们将通过采样状态的经验获得的增益定义如下: 状态值可以再次表示为获得的奖励如下:
看这个公式,我们通过添加旧状态值函数和新获得的奖励之间的差来更新状态值函数。这里,旧状态值函数与新获得的奖励之间的差异称为误差。
乘以这个错误
跟深度学习一样,学习率
蒙特卡洛预测中使用的总获得奖励
蒙特卡洛控制使用状态-动作值函数而不是状态值函数。 这样可以以一定的概率选择和探索状态-动作价值函数值高的动作。
4.4.2 时间差分学习(temporal-difference learning, TD)
时差学习也可以在预测和控制方面进行研究。
在 Monte Carlo 预测中,状态值函数直到结束才能更新。 因此,存在难以进行实时进行学习的缺点。 时差预测 (TD) 允许您在每个时间步更新值函数。
时差预测更新值函数如下:与蒙特卡罗预测不同,我们在每个时间步
更新价值函数。这样,在episode中,当前状态的值函数用下一个状态的值函数更新,所以
可以说是使用bootstrap。事实上,即使在动态规划中,值函数也会在每个时间步进行更新。因此,可以说DP也使用了bootstrap。
bootstrap 是一种将当前状态的价值函数的值预测为下一个状态的价值函数的值的方法。
在 时间差分学习中,控制具有不同的名称,具体取决于它是在on-policy还是off-policy外。 On-policy 时间差分控制称为 state-action-reward-state-action (SARSA),off-policy 时间差分控制称为 Q-learning。
4.4.2.1 SARSA
对于一个 on-policy 方法,需要针对当前的行为策略以及所有的状态
和行为
估计行为值函数
,SARSA 是因为一个样本由当前状态、动作、奖励、下一个状态和下一个动作组成。这可以通过使用和TD 方法相同的方法来实现。现在考虑状态行为对之间的转移,同时学习状态行为对的值。TD方法下对应行为值函数的算法如下
4.4.2.1 Q-learning
Q-learning是一种off-policy 的 TD 控制算法。Q-learning将已经学习到的行为值函数接用来近似最优行为值函数
,而与当前遵循的策略无关。
上式更新一个状态-行为对,更新后的值从行为节点导出,选择下一个状态的可能行为中对应行为值函数最大的节点
4.4.3 策略梯度(policy gradient, PG)
策略梯度可以被认为是分类问题的强化学习。这一切都是为了决定在什么条件下哪个动作是最好的。策略梯度使用人工神经网络对任何状态下行为的概率值进行建模。
在在 Q-learning 中,您学习函数并采取具有高
值的动作。 在策略梯度中,您学习一个动作的概率。 在策略梯度中,损失函数可以写成:
其中是考虑长期奖励在状态
中执行动作
的价值。 策略斜率可以通过多种方式定义损失函数。 我们接下来将讨论的 Actor-Critic、A2C 和 A3C 可以看作是策略梯度方法的变体。
4.4.4 Actor-Critic(AC)
AC算法框架被广泛应用于实际强化学习算法中,该框架集成了值函数估计算法和策略搜索算法,是解决实际问题时最常考虑的框架。大家众所周知的alphago便用了AC框架。
Q-learning或策略梯度是使用单个神经网络的强化学习方法。 Actor-Critic 可以看作是 Q 学习和策略梯度的混合强化学习模型。
Actors 使用策略梯度模型来确定要采取的行动,Critic 使用 Q-learning 模型来批评所采取的行动。 这避免了单个模型常见的高方差问题。如下为Actor-Critic结构示意图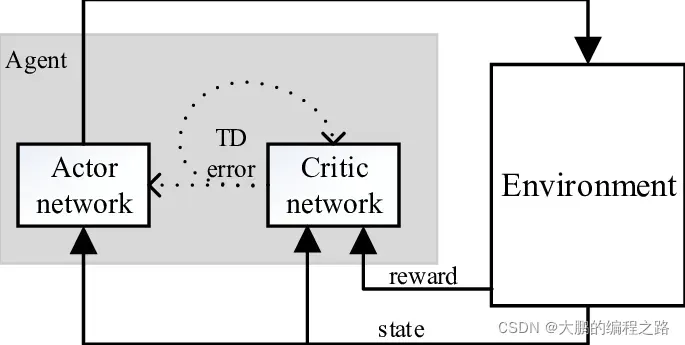
通过这种方式,Actor-Critic 通过在 Actor 和 Critic 之间共享一个神经网络来执行强化学习。 损失函数可以表示为
4.4.5 A2C(advantage actor-critic)
A2C 是在 Actor-Critic 方法中使用预期输出作为优势的方法。 优势是状态-动作值减去状态值。使用 Advantage 的损失函数更改为:
A2C 将批评者视为优势。 这将使您不仅可以了解行为在哪个状态下有多好,还可以了解它如何变得更好。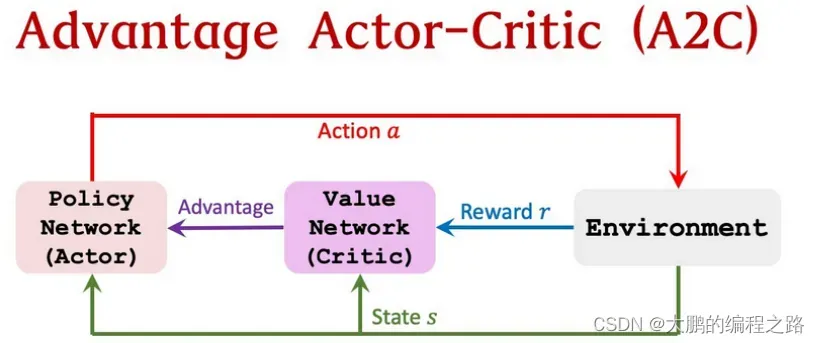
4.4.6 A3C(asynchronous advantage actor-critic)
A3C 是 Google DeepMind 公布的具有代表性的强化学习方法之一。 A3C与A2C类似,但顾名思义,是在A2C中加入了异步概念的方法。
在 A3C 中,代理同时在多个环境中执行动作并训练神经网络。 之所以称为异步,是因为它同时在多个环境中训练神经网络。
在多个环境中执行动作并获得奖励,并异步更新神经网络。通过这种方式,多个智能体在个体环境中独立地产生行为、奖励和批评,以执行强化学习。这使您可以通过更广泛的经验快速有效地学习。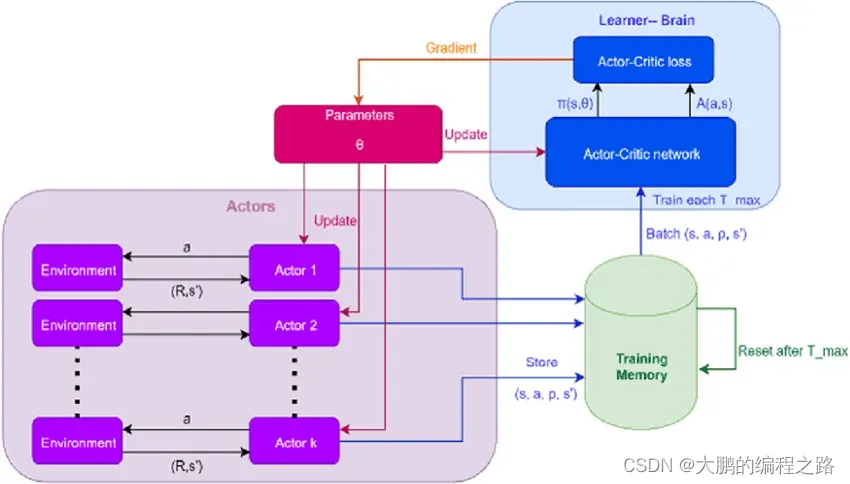
4.4.7小结
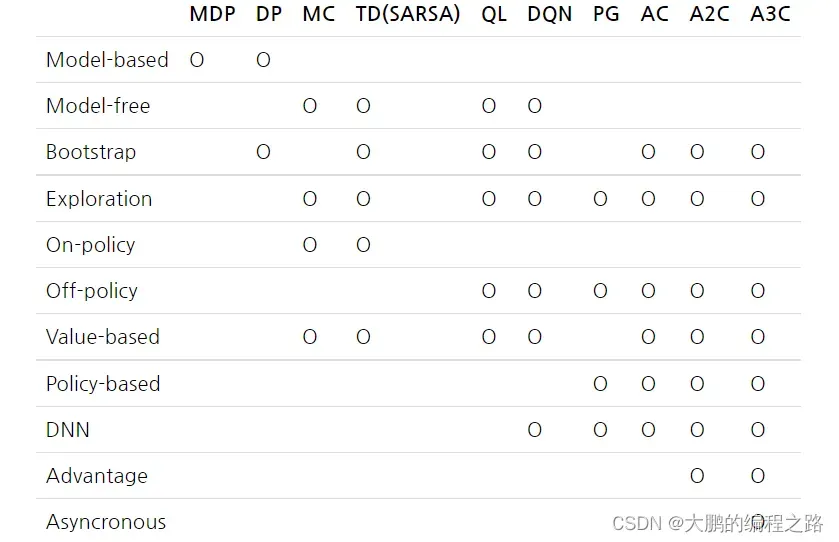
到目前为止,马尔可夫决策过程(MDP)、动态规划(DP)、蒙特卡洛学习(MC)、时差学习(TD)、时差学习(TD)、Q-学习(QL)、DQN、策略梯度(PG ),Actor – 介绍了了 Critic (AC)、A2C 和 A3C。 下表显示了这些强化学习技术的强化学习特征。
文章出处登录后可见!