LSTM来源
因为论文里面用到了LSTM网络,又不想看代码,遂记录一下LSTM网络的原理吧。下一篇研究一下GRU(LSTM网络的变体)
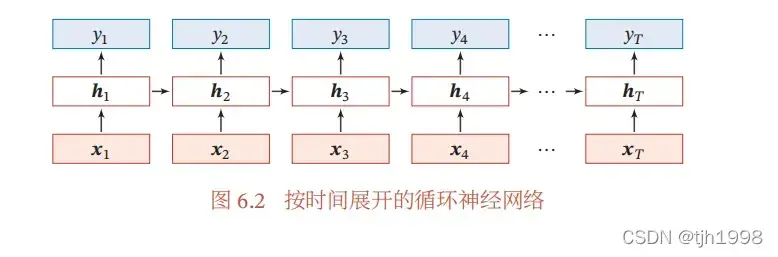
LSTM起源于RNN,RNN(recurrent nenural network),RNN神经网络的结构如下图所示:
其中代表的是t时刻网络的输入(input),
代表的是隐藏层(Hidden layer)的状态,当前
的输出不仅和当前时刻的输入(input)
有关,还和之前的输出
有关,因此简单的循环网络在t时刻的更新公式如下所示:
其中为隐藏层(Hidden layer)的净输入(input),f是非线性激活函数(Activation Function)。
由于RNN保留了时间序列的上下文信息,所以可以通过过去的信号数据来推测当前信号的数据,理论上RNN可以保留之前所有时刻的信息。然而实际的使用过程中,由于当前的时刻的t输出可能依赖(dependency)于k时刻的输入(input),随着时间间隔的增大,梯度(gradient)会出现爆炸和消失的情况,因此,RNN神经网络很难建立长距离的依赖(dependency)关系,即(long-term-dependencies),为了改善这个问题,从而提出了基于门控(gated)的循环神经网络(RNN网络):长短期记忆(Long-Short Term Memory(LSTM))网络(long short-term memery network)LSTM
LSTM网络公式解释
首先需要知道,在LSTM网络中增加了一个internal-state,其实就是cell-state.如下图所示,其内部增加了3个门控(gated)开关,分别是遗忘门(forget gate)
,输入(input)门
,输出门
。
数字电路中,开关有0和1两种状态,而LSTM网络中引入了门控(gated)机制,它的取值为0~1之间,用来控制传输数据的多少。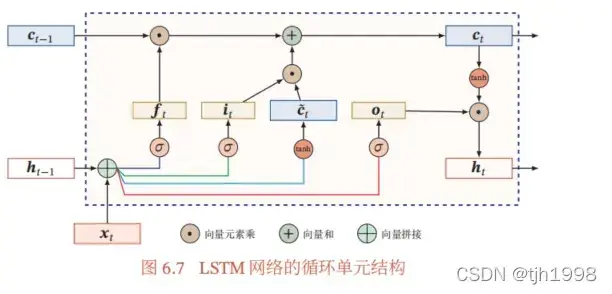
:遗忘门(forget gate),用于控制前一时刻的内部状态需要遗忘多少信息。
:输入(input)门,用于控制当前时刻需要为候选状态
保存多少信息。这里的候选状态
是根据上一时刻的输出
和本次的输入(input)
计算得出的。
:输出门,顾名思义,在当前内部状态
下,可以输出多少信息到外部状态
。
需要注意一下这里的其实就是RNN中的
。而LSTM中的
就是RNN中的
。
我们来看看上面三个门是如何计算的。
遗忘门(forget gate)的计算
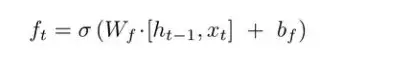
遗忘门(forget gate)的结构中包含一个sigmod神经网络层(参数为,
)。
将上一时刻的输出和当前时刻的输入(input)拼接之后送入到sigmod网络层中,最终输出,注意
是一个0~1的数值。
输入(input)门的计算
它与遗忘门(forget gate)相同,但给定的权重参数不同。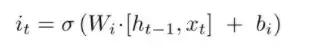
输出门的计算
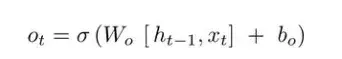
内部状态的计算
内部状态存储到当前时刻的历史信息
,因为它需要确定需要丢弃多少先前的信息。而
,因为它需要确定新输入(input)的信息需要保留多少。
得到了之后,就可以把它传递给t+1时刻的LSTM网络中啦!
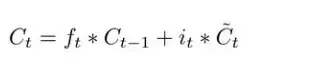
候选状态的计算公式如下:注意这里是通过一个tanh神经网络层
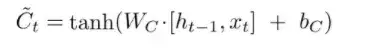
输出计算
万事俱备,只欠产出!当前时刻输出的计算公式如下:
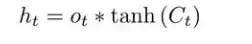
需要注意的是这里的tanh是一个函数,不是一个神经网络层,上面候选状态的计算过程中tanh是一个神经网络层。
将当前时刻的内部状态通过一个tanh函数,之后和遗忘门(forget gate)的数值
进行相乘,即可以得到当前时刻的输出,与此同时它也将作为下一时刻的输入(input)信号。
总结
1.计算3个门控(gated)的值:取值为0-1之间。
2.遗忘门(forget gate)乘以上一时刻内部状态的加上输入(input)门乘以当前时刻的候选状态
得到当前时刻的内部状态
3.当前的时刻输出:输出门和经过非线性变变化之后的c_t相乘。
LSTM中使用门控(gated)状态来控制传输状态,RNN网络中,和
之间的变化通常很大,而传递下来的
却改变的比较慢,所以我们认为RNN是一种short-term_memory。因为每个时刻的
都是不一样的。而LSTM中,通过记忆单元c可以捕捉某个关键信息,而且可以有能力将此关键信息保存一定的时间间隔。
外表
下一节将研究LSTM变体:GRU。
原理听起来比较简单,不过自己实现的时候还需要考虑LSTM的参数学习,如何训练上述公式中提到的参数,也是一大块知识要去啃呀。书中提到了BPTT:即随时间反向传播(Back propagation)算法。有兴趣的同学可以看一看嗷。
相关书籍:
神经网络与深度学习(Deep learning) – 邱希鹏
文章出处登录后可见!