代码地址:dongbo811/AFFormer (github.com)
文章地址
摘要
现有的语义分割工作主要集中在设计有效的解码器上;然而,整体结构引入的计算负载长期被忽视,阻碍了其在资源受限硬件上的应用。本文提出了一种专门用于语义分割的无头轻量级架构,命名为自适应频率Transformer( AFFormer )。AFFormer采用并行架构,利用原型表示作为特定的可学习的局部描述,替代解码器并在高分辨率特征上保留丰富的图像语义。虽然移除解码器压缩了大部分计算量,但并行结构的精度仍然受到低计算资源的限制。因此,我们使用异构算子(CNN和Vision Transformer)进行像素嵌入和原型表示,以进一步节省计算成本。而且,从空间域的角度对视觉转换器的复杂度进行线性化处理非常困难。由于语义分割对频率信息非常敏感,我们构造了一个具有复杂度为O(n)的自适应频率滤波器的轻量级原型学习块,以代替复杂度为O(n2)标准的自注意力。在广泛使用的数据集上的大量实验表明,AFFormer在仅保留3M个参数的情况下获得了较高的准确率。在ADE20K数据集上,AFFormer达到了41.8 mIoU和4.6 GFLOPs,比Segformer提高了4.4 mIoU,GFLOPs减少了45%。在Cityscapes数据集上,AFFormer取得了78.7 mIoU和34.4 GFLOPs,比Segformer提高了2.5 mIoU,GFLOPs减少了72.5 %。
引言
背景
(1)之前的语义分割方法重点研究利用分类网络作为骨架提取多尺度特征,并设计复杂的解码器头建立多尺度特征之间的联系。然而,这些改进是以较大的模型尺寸和较高的计算成本为代价的。
(2)现有的Transformer方法通过减少token数量或滑动窗口来缓解计算复杂度高和内存耗费大的问题,但它们在计算复杂度上的降低有限,甚至在分割任务中牺牲全局或局部语义。语义分割作为一个基础研究领域,有着广泛的应用场景,需要处理各种分辨率的图像。
根据以上两个情况,文章提出两个问题:
- 语义分割能否像图像分类一样简单?
- 是否能够设计一个高效轻量的Transformer网络用于超低计算场景下的语义分割?
文章的工作
针对以上两个问题,文章提出了一种无头的轻量级语义分割特定架构,命名为Adaptive Frequency Transformer(AFFormer)。它的特点有:
(1)受ViT保持单一高分辨率特征图保持细节和金字塔结构的性质降低了探索语义的分辨率,减少了计算成本的观点的启发,AFFormer采用并行架构,将原型表示作为特定的可学习的局部描述,替代解码器并在高分辨率特征上保留丰富的图像语义。
(2)文章对像素嵌入特征和局部描述特征使用异构算子以节省更多的计算成本。基于Transformer的原型学习(PL)模块用于学习原型表示,而基于卷积的pixel descriptor(PD)模块将像素嵌入特征和学习到的原型表示作为输入,将其转换回全像素嵌入空间以保留高分辨率语义。(pixel descriptor应该和上采样差不多)
(3)文章发现语义分割对频率信息也非常敏感。因此构造了复杂度为O(n)的轻量级自适应频率滤波器作为原型学习,代替复杂度为O(n2)的标准的自注意力。该模块的核心由频率相似度核、动态低通和高通滤波器组成,分别从强调重要频率成分和动态过滤频率的角度捕捉有利于语义分割的频率信息。
(4)文章在高低频提取和增强模块中共享权重,进一步降低计算成本。文章还在前馈网络( FFN )层嵌入了一个简化的深度卷积层来增强融合效果,减小了两个矩阵变换的大小。
(5)在并行异构架构和自适应频率滤波器的帮助下,我们只使用一个卷积层作为单尺度特征的分类层(CLS),实现了最好的性能,并使语义分割与图像分类一样简单。
实验说明:
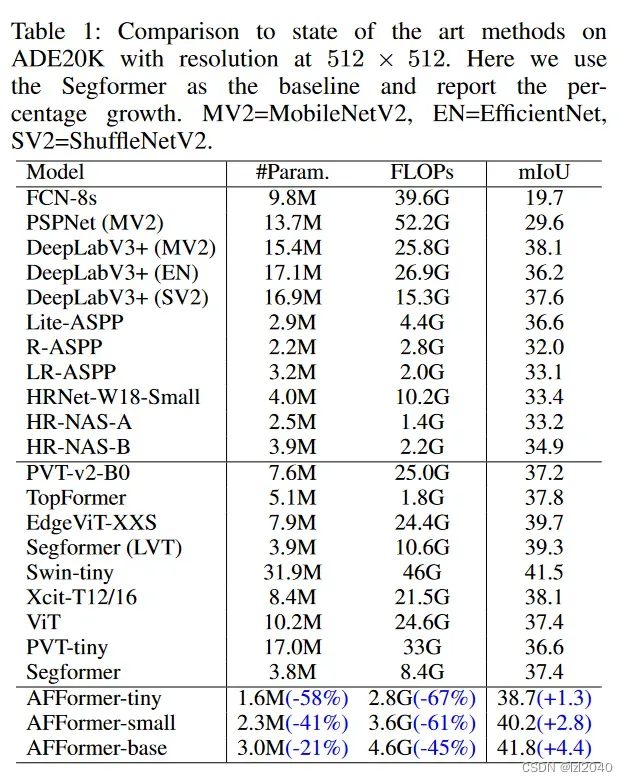
在仅使用3M参数的情况下,AFFormer明显优于当前最先进的轻量化方法。在ADE20K上,AFFormer以4.6个GFLOP实现了41.8 mIoU,比Segformer多4.4 mIoU,同时降低了45 %的GFLOP。在Cityscapes上,AFFormer获得78.7 mIoU和34.4 GFLOPs,比Segformer高2.5 mIoU,GFLOPs少72.5 %。
方法
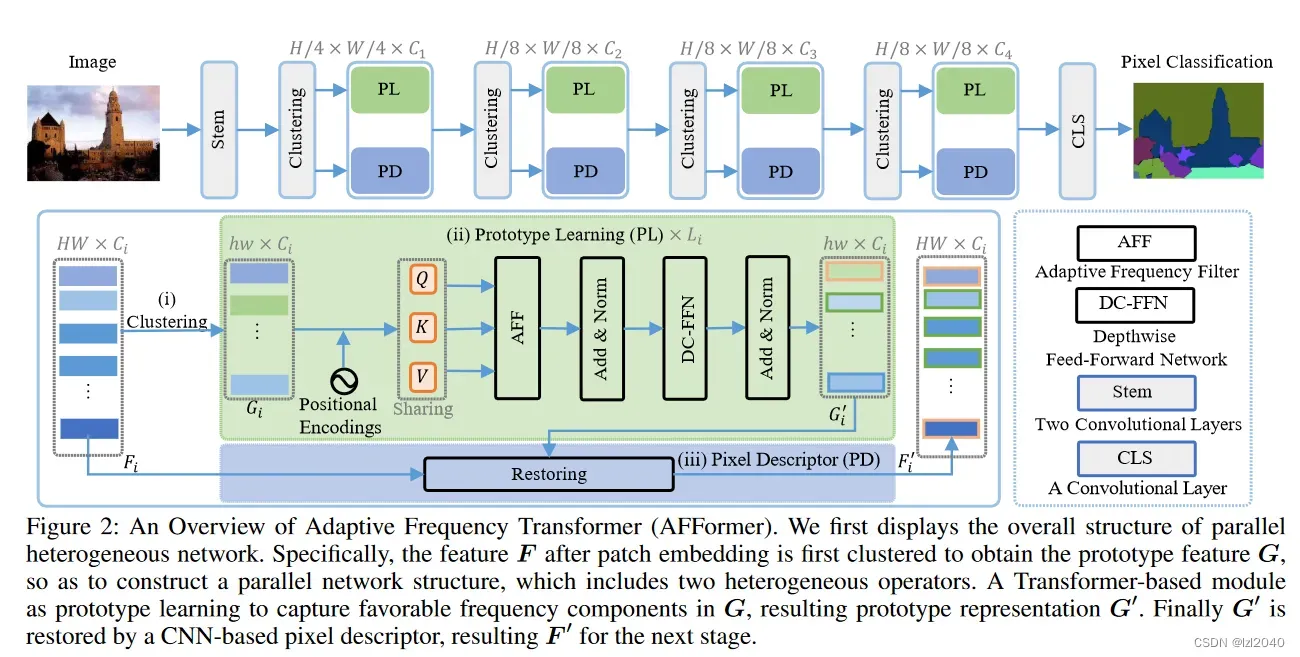
Parallel Heterogeneous Architecture
语义解码器将编码器得到的图像语义传播到每个像素,恢复下采样中丢失的细节。一个直接的选择是在高分辨率特征中提取图像语义,但它引入了巨大的计算量,特别是对于视觉Transformer。相比之下,我们提出了一种新颖的策略来描述具有原型语义的像素语义信息。
对于每个阶段,首先初始化一个grid G作为图像的一个原型,G中的每个点作为局部聚类中心,初始状态只包含周围区域的信息。对于每个特定的像素,由于周围像素的语义并不一致,因此每个聚类中心之间存在重叠语义。在其对应的区域α^2内对聚类中心进行加权初始化,每个聚类中心的初始化表示为:
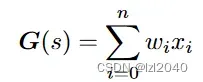
其中n = α × α, wi表示xi的权重,α设置为3。我们的目的是更新网格G中的每个聚类中心s,而不是直接更新特征F,且h * w远远小于H * W。
在此部分,文章使用Transformer模块作为原型学习来更新每个聚类中心,总共包含L层,更新后的中心记为G′(s)。对于每个更新后的聚类中心,我们通过一个pixel descriptor进行恢复。令F’i表示恢复的特征,它不仅包含了F中丰富的像素语义,还包含了聚类中心G′( s )收集的原型语义。由于聚类中心聚合了周围像素的语义导致局部细节丢失,pixel descriptor首先对F中的局部细节进行像素语义建模。具体来说,将F投影到低维空间,建立像素之间的局部关系,使得每个局部块保持一个清晰的边界。然后将G′(s)嵌入到F中,通过双线性插值恢复到原始空间特征F′。最后,它们通过线性投影层进行集成。
Prototype Learning by Adaptive Frequency Filter
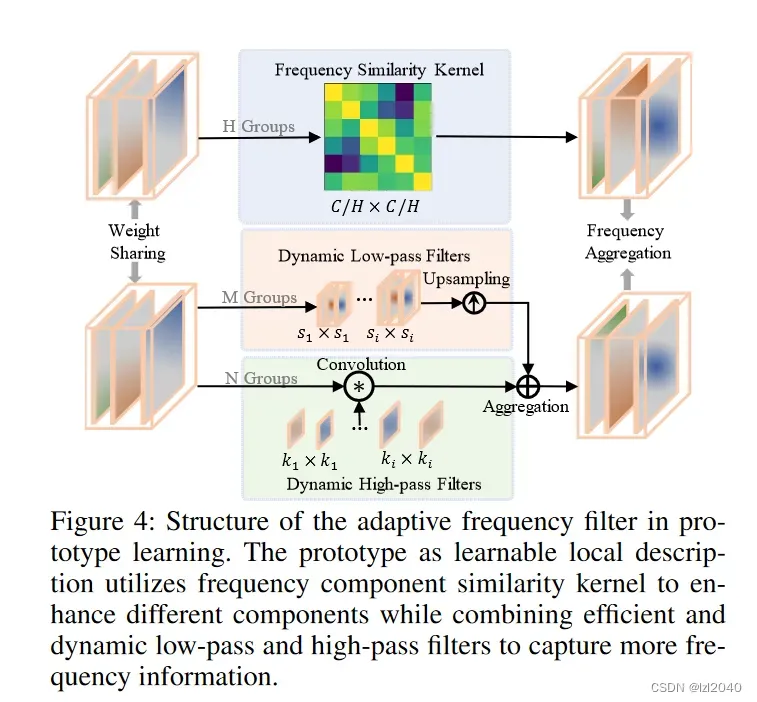
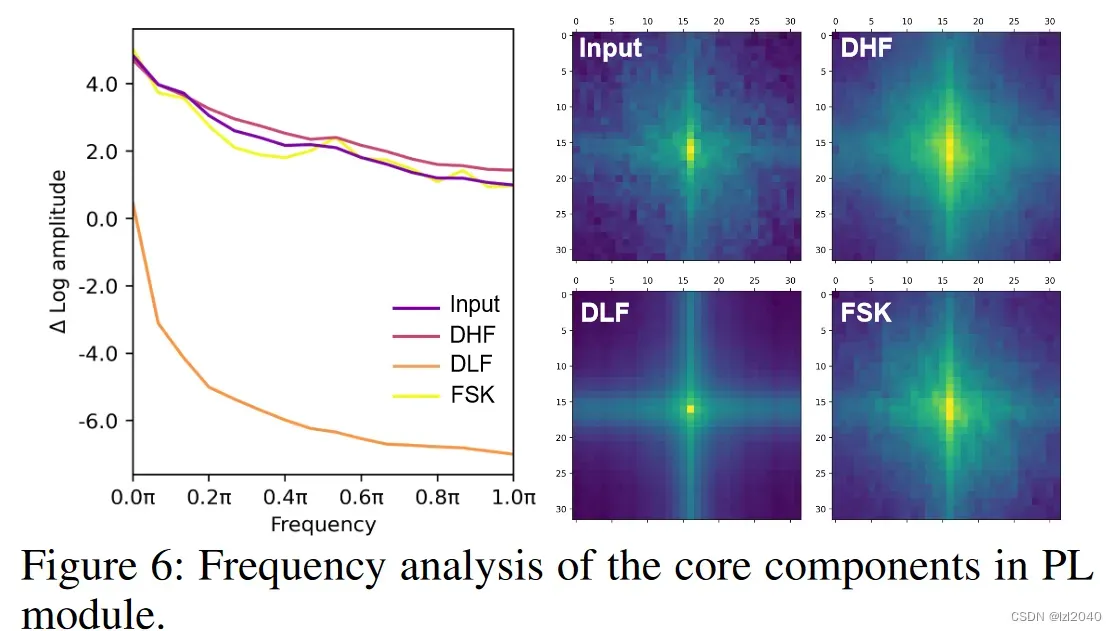
结构说明:原型作为可学习的局部描述,利用频率成分相似核对不同成分进行增强,同时结合高效动态的低通和高通滤波器以捕获更多的频率信息。
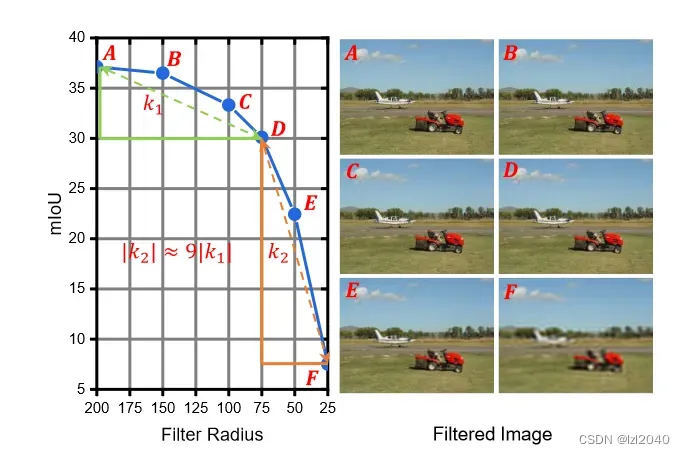
使用该模块的原因:频率表征可以作为学习类别间差异的新范式,可以挖掘人类视觉忽略的信息。挖掘更多的频率信息可以增强类别之间的差异性,使每个类别之间的边界更加清晰,从而提高语义分割的效果。除非过滤掉绝大多数频率成分,否则人类对频率信息去除具有鲁棒性,如下图,利用给定半径的低通算子滤除高频信息。
本文的做法:由于特征F包含丰富的频率特征,网格G中的每个聚类中心也有这些频率信息。受此启发,在网格G中提取更多的有益频率有助于区分每个聚类的属性。
由于傅里叶变换和傅里叶逆变换会带来额外的计算开销,文章从频谱相关性的角度出发,设计了基于vanilla vision transformer的自适应频率滤波块,直接在空间域捕获重要的高频和低频特征。公式为:
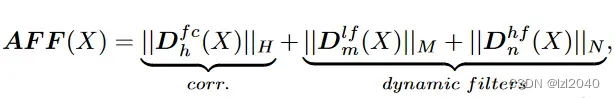
其中Dfc表示frequency similarity kernel,它有H个组,用于实现频率成分相关性增强;Dlf表示dynamical low-pass filters,它有M个组;Dhf表示dynamical high-pass filters,它有N个组。|| · || 表示拼接操作。这些算子采用并行结构,通过共享权重进一步降低计算成本。
Frequency Similarity Kernel (FSK)
问题:不同的频率成分分布在G中,我们的目的是选择和增强有助于语义解析的重要成分。
公式:
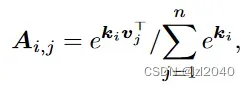
其中Aij是一个similarity kernel,它表示不同频率成分之间的对应关系,我们通过查询similarity kernel选取重要频率成分。ki表示K中的第i个频率分量,vj表示V中的第j个频率分量。K和V都是特征X经过线性映射层得到的,在这里,X其实就是G。
文章还通过一个线性层将输入X转换为查询Q,并在固定大小的相似度核上通过交互得到组件增强的输出。
Dynamic Low-Pass Filters (DLF)
低频成分占据了绝对图像中的大部分能量,代表了大部分的语义信息。
我们采用典型的平均池化作为低通滤波器,同时由于不同图像的截止频率不同,我们在不同组使用了不同的核和步长,公式为:
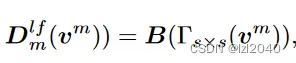
其中B代表双线性插值,Γs × s表示输出大小为s × s的自适应平均池化。m代表这是第m组的。
Dynamic High-Pass Filters (DHF)
高频信息对分割中细节的保留至关重要。卷积作为一种典型的高通算子,可以滤除不相关的低频冗余成分,保留有利的高频成分。
由于高频成分决定了图像质量,每幅图像的高通截止频率不同,因此也是将输入分成了多组,公式如下:
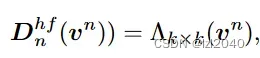
其中Λk × k表示核大小为k × k的深度卷积层。
此外,文章使用查询和高频特征的Hadamard乘积来抑制对象内部的高频,这些高频是用于分割的噪声。
实验
在ADE20K上的实验结果:
频率数据的可视化:
结论
本文提出了一种无头的轻量级语义分割特定架构AFFormer。其核心是从频率角度学习聚类原型的局部描述表示,而不是直接学习所有的像素嵌入特征。它在具有线性复杂度Transformer的同时去除了复杂的解码器,实现了与常规分类一样简单的语义分割。实验结果表明,AFFormer在较低的计算代价下具有较强的准确性、稳定性和鲁棒性。
感悟
学到的知识点:
- 低频成分占据了绝对图像中的大部分能量,代表了大部分的语义信息。
- 高频信息对分割中细节的保留至关重要
- 卷积作为一种典型的高通算子,可以滤除不相关的低频冗余成分,保留有利的高频成分
- 语义解码器将编码器得到的图像语义传播到每个像素,恢复下采样中丢失的细节
- 频率表征可以作为学习类别间差异的新范式,可以挖掘人类视觉忽略的信息
- 挖掘更多的频率信息可以增强类别之间的差异性,使每个类别之间的边界更加清晰,从而提高语义分割的效果。
- 频谱图中心是低频,四周是高频
文章出处登录后可见!