
Active Object Localization with Deep Reinforcement Learning
https://arxiv.org/pdf/1511.06015.pdf
做了什么
该论文将强化学习应用于图像中的目标定位。我们用手机看图片时,会通过放大,滑动屏幕等等操作来定位目标:
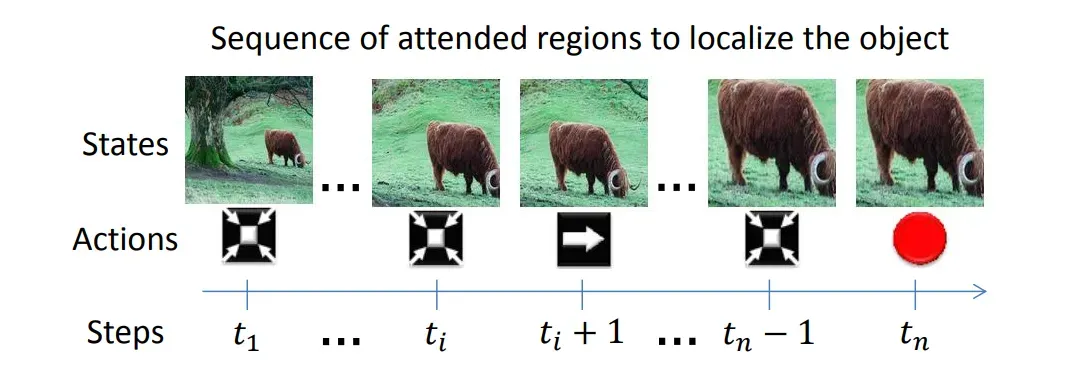
该论文让智能体学习类似的操作。
怎么做的
对目标定位进行马尔可夫决策过程建模,使用DQN算法让智能体学习定位策略。
动作
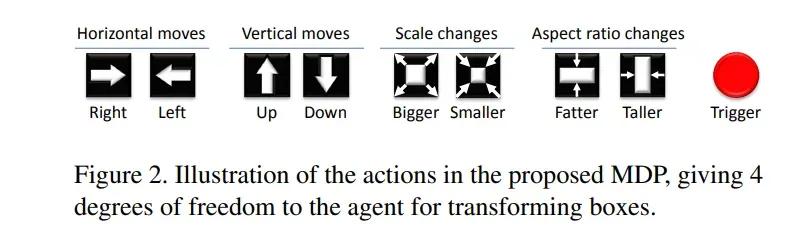
总共九个动作:
(1)八个动作用于定位边框的变换:
这些操作如图2所示,分成四个子集:在水平轴(horizontal)和垂直轴(vertical)上移动边框、改变边框的比例(scale)和修改边框的长宽比( aspect ratio)。
边框由其两个角的像素坐标表示:。动作对边框的更改值
或
与边框的当前大小相关:
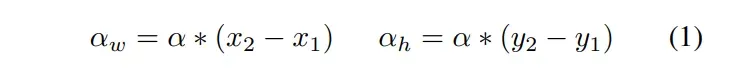
其中,实验中设置为0.2。
例如,
向右水平移动边框可以将和
与
相加;
而减小纵横比可以将与
相减,并将
与
相加。
请注意,图像平面中的原点位于左上角。
(2)一个动作用于结束目标搜索:

触发器(trigger)不变换边框,而是用于指示对象已被定位。一旦执行了这个动作,目标搜索将终止,并在初始位置重新启动边框以进行新一轮目标搜索。触发器还对图像进行了修改:它用黑➕标记了上次搜索得到的目标区域,通过这样阻止已定位的目标再次被定位,实现多目标的定位。

一些例子:

状态
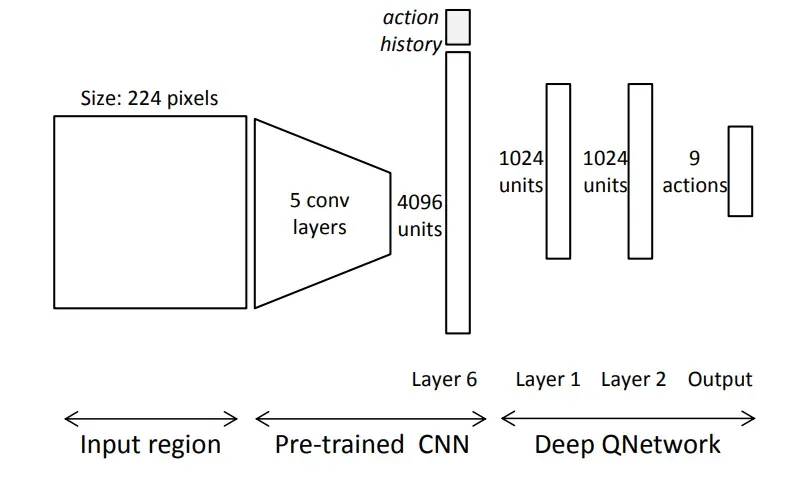
状态是一个元组,其中
是边框包围区域的特征向量,
所采取历史动作组成的向量。
边框内的区域都会被扩展到原始框周围的16个像素,变换为224×224以匹配网络的输入大小,输入预训练CNN,输出4096维的特征向量。
历史向量 包含10个历史动作。每个动作都用one-hot向量表示。这意味着
。
奖励
令为目前的边框,
为目标边框。
和
的IoU为:
![]()
八个变换动作的奖励
当智能体选择动作从状态
移动到状态
时,边框由
变为
。智能体获得的奖励:
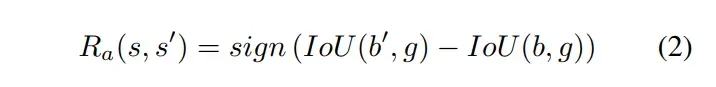
直观地说,等式(2)表示如果从状态到状态
时IoU变大,则奖励为
,否则为
。
终止动作的奖励
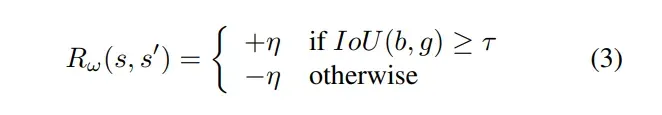
其中是终止动作,
是终止奖励,实验中设置为3.0,
是一个阈值,表示允许将检测到区域视为真正(TP)的最小IoU,实验中
设置为0.6。
结果
所有参与区域(All joining regions, AAR):对智能体处理的所有区域进行评分。
终端区域(Terminal regions,TR):只考虑智能体使用触发器指示为存在目标的区域。
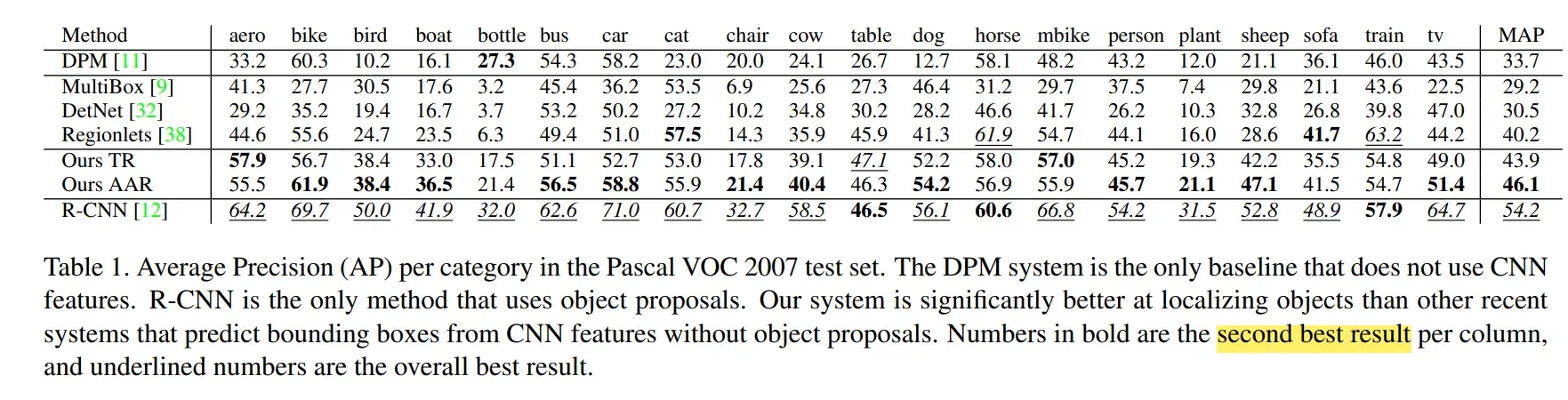
准确率评估
召回率评估
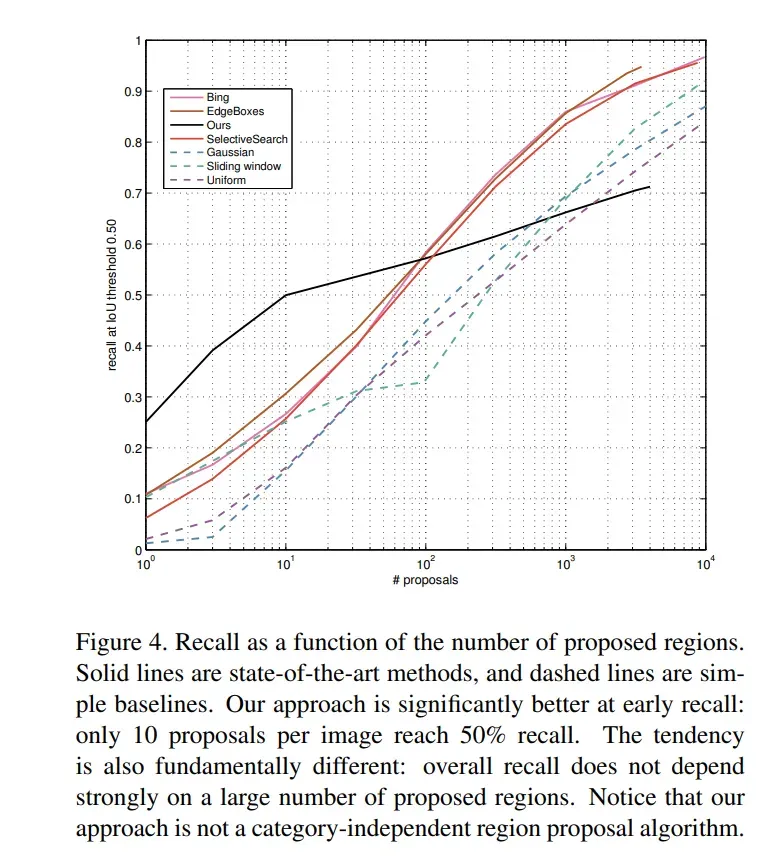
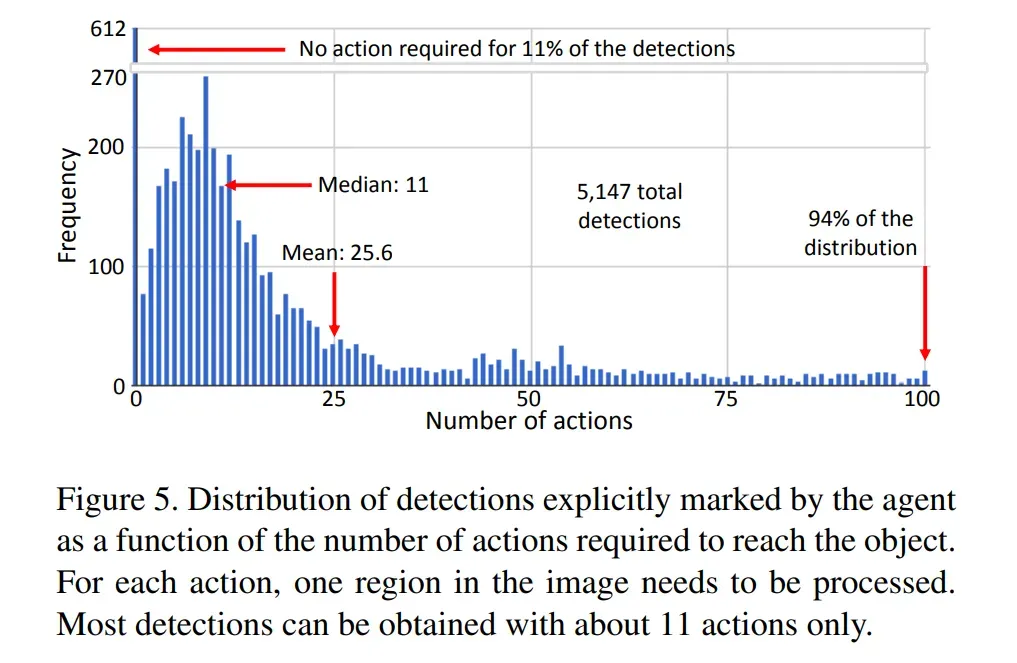
图5绘制了正确检测到对象所需的步数的分布图。
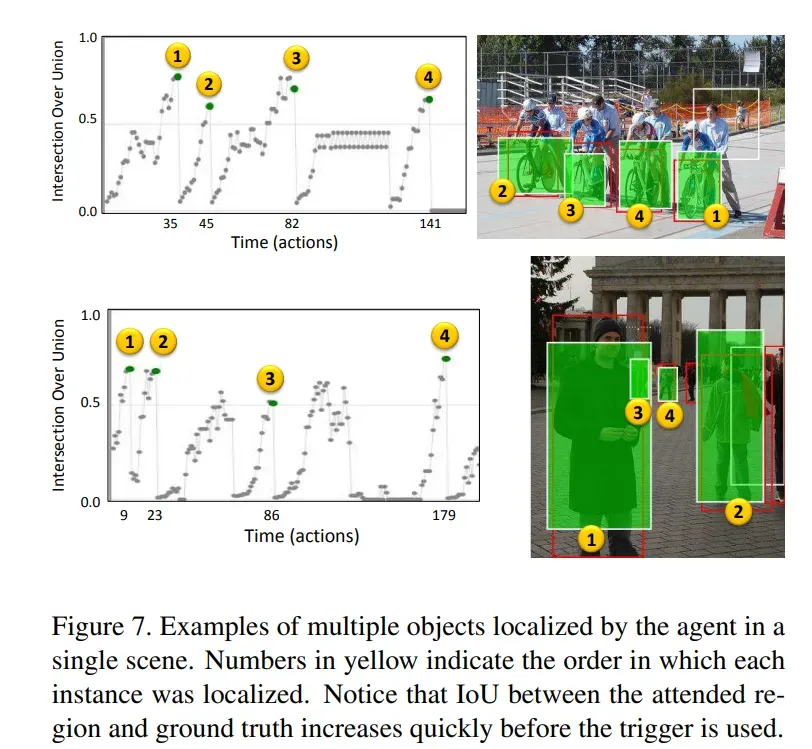
定性评估
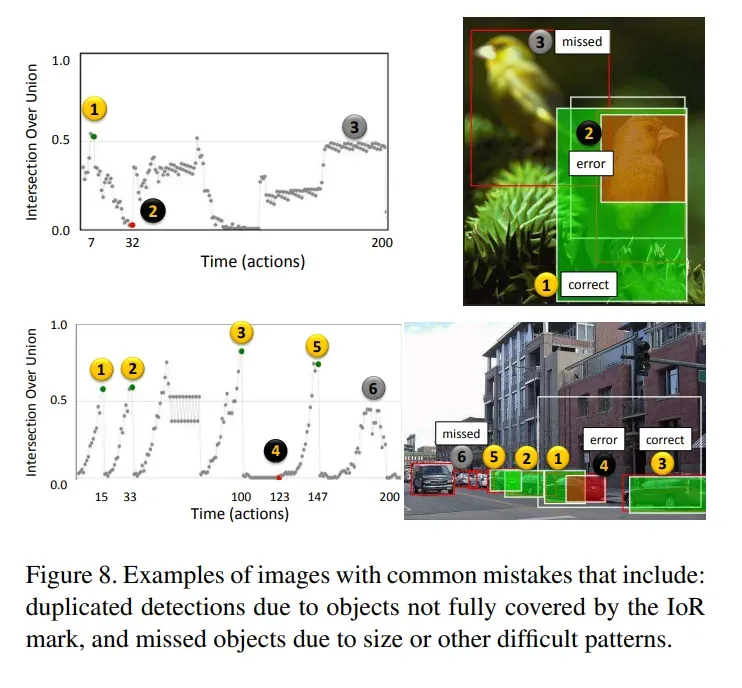
错误例子
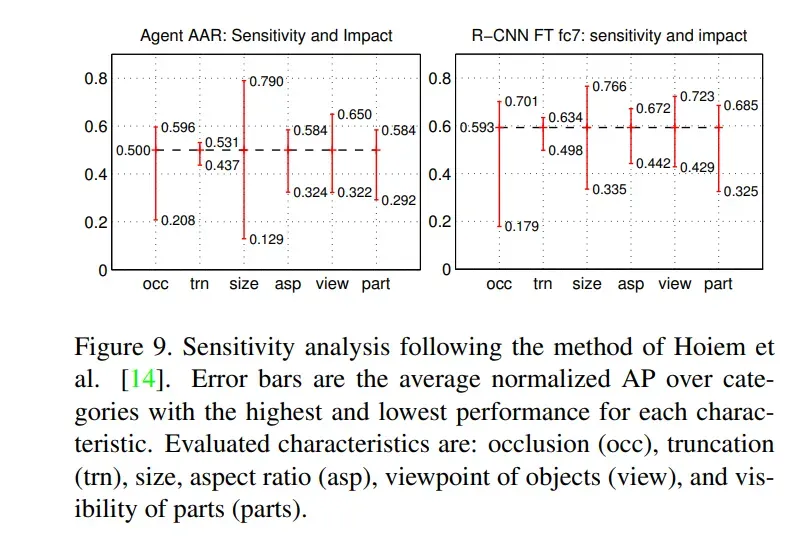
敏感性分析
评估特征有:遮挡(occ)、截断(trn)、大小、纵横比(asp)、物体视点(view)和部分可见(parts)。
文章出处登录后可见!