相信看到标题的你心里会有以下疑问:什么是激活函数?为什么要用激活函数?激活函数是什么?下面让Sun小白带大家一起了解神经网络中的社交规则——激活函数。
什么是激活函数?
在神经网络的前向传输中,输入值经过一系列加权求和后被应用到另一个函数上,这就是激活函数。与人脑中的神经元类似,激活函数决定是否传递一个信号以及传递什么给下一个神经元。
为什么需要激活函数?
因为神经网络中每一层的输入和输出都是一个线性求和过程,所以下一层的输出只是上一层输入函数的线性变换。如果不使用激活函数,则输出信号只是一个简单的线性函数。
线性函数是一阶多项式,线性方程的复杂度有限,从数据中学习复杂函数映射的能力很小。
如果没有激活函数,神经网络就无法学习和模拟其他复杂类型的数据,例如图像、视频、音频、语音等。
为什么需要非线性激活函数?
如果网络中都有线性分量,那么线性组合仍然是线性的,与单个线性分类器没有区别。这使得不可能逼近具有非线性的任意函数。
使用非线性激活函数以使网络更强大并增加其能力,以便它可以学习复杂的事物。使用非线性激活函数,可以在输入和输出之间生成非线性映射,表示输入和输出之间的非线性复杂任意函数映射。
它是什么? – – -常用激活函数
- sigmoid函数,函数定义如下,值域为(0,1):
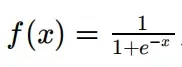
功能图如下: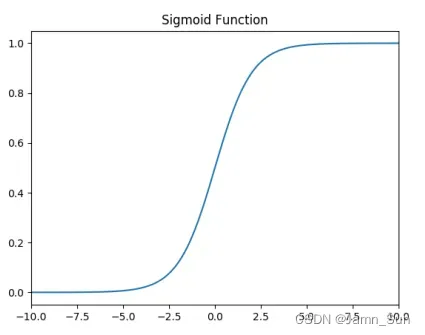
- tanh激活函数,函数定义如下,值域为(-1,1):
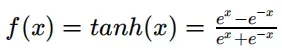
功能图如下: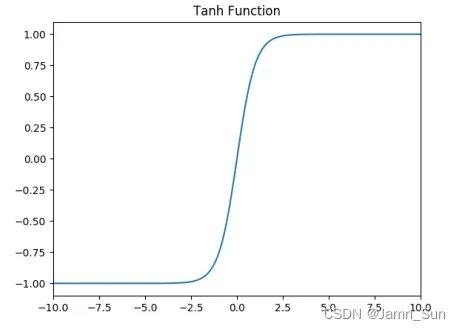
- Relu激活函数,函数定义如下,值域为[0,+∞):
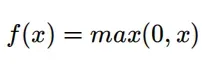
功能图如下: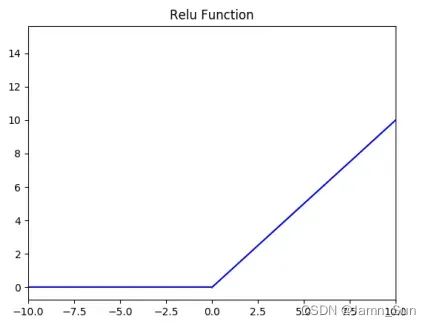
ReLU 函数从图像上看,是⼀个分段线性函数,把所有的负值都变为 0,⽽正值不变,这样就成为单侧抑制。
由于这种单方面的抑制,神经网络中的神经元也具有稀疏激活。
稀疏激活:从信号上看,即神经元只选择性地同时对一小部分输入信号做出反应,大量的信号被故意屏蔽掉,这样可以提高学习的准确率,更好地提取并且更快。稀疏特征。
- Leak Relu激活函数,函数定义如下,值域为(-∞,+∞):
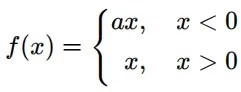
函数图像如下(a = 0.5):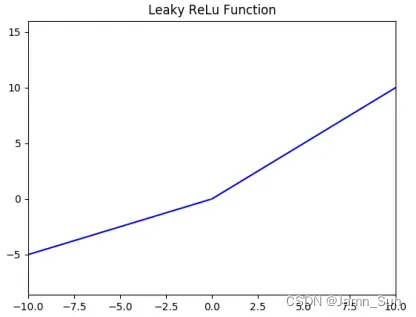
- 在实践中,使⽤ ReLu 激活 函数神经⽹络通常会⽐使⽤ sigmoid 或者 tanh 激活函数学习的更快。
- sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,⽽ Relu和Leaky ReLu 函数⼤于 0 部分都为常数,不会产⽣梯度弥散现象。
- Relu 进⼊负半区的时候,梯度为 0,神经元此时不会训练,产⽣所谓的稀疏性,⽽Leaky ReLu 不会产⽣这个问题。
- SoftPlus激活函数,函数定义如下,值域为(0,+∞):
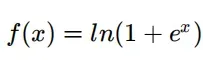
功能图如下: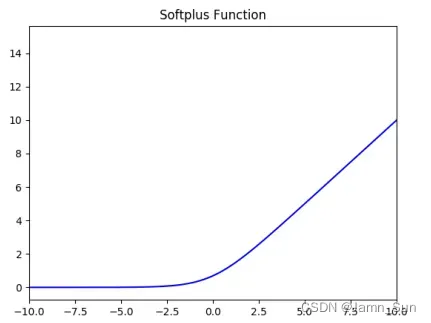
- softmax激活函数
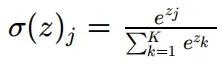
softmax 函数可以把它的输⼊,通常被称为 logits 或者 logit scores,处理成 0 到 1 之间,并且能够把输出归⼀化到和为 1。这意味着 softmax 函数与分类的概率分布等价。它是⼀个⽹络预测多酚类问题的最佳输出激活函数。
softmax ⽤于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解, 从⽽来进⾏多分类。
假设我们有⼀个数组,Vi表示V中的第i个元素,那么这个元素的 softmax 值就是: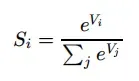
以下示例说明: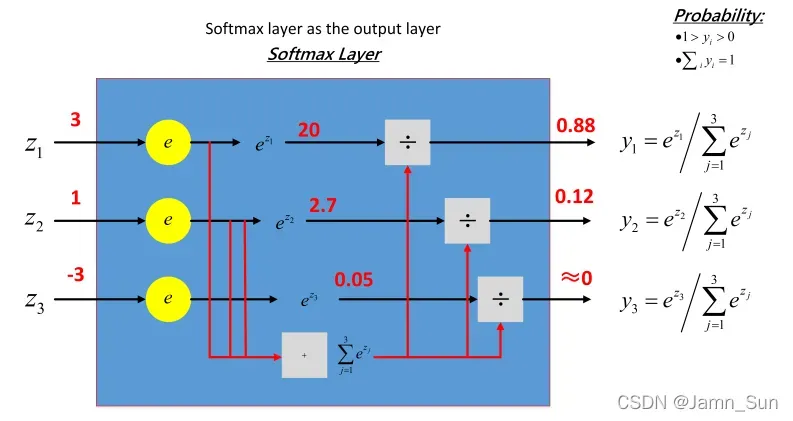
softmax 直⽩来说就是将原来的输出3、1、-3 通过 softmax 函数作⽤,映射成为(0,1)的值,而这些值的累和为 1(满⾜概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
文章出处登录后可见!