🌞欢迎来到机器学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2021年3月12日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

🍈 一、概述
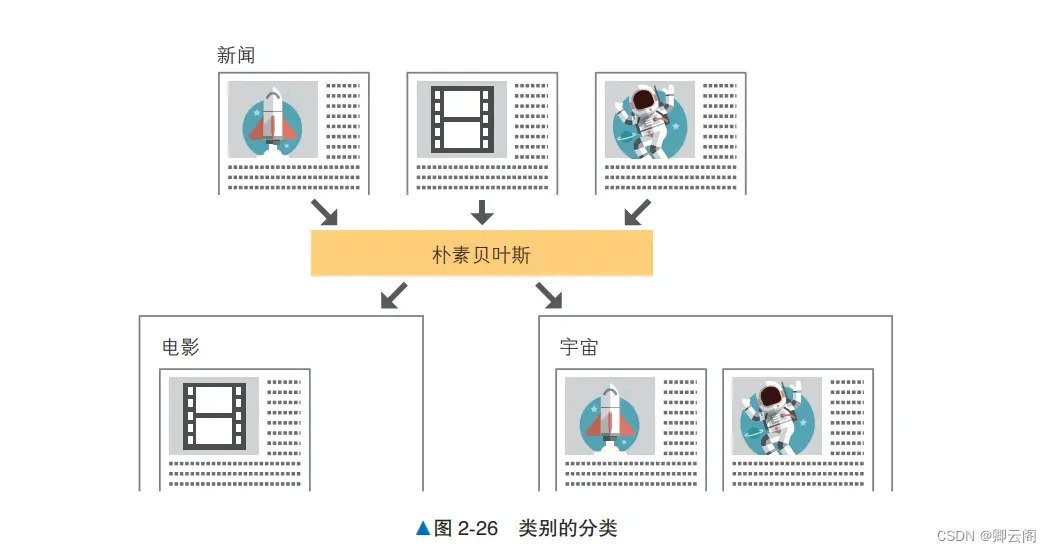
朴素贝叶斯是一个基于概率进行预测的算法,在实践中被用于分类问题。具体来说,就是计算 数据为某个标签的概率,并将其分类为概率值最大的标签。下面使用朴素贝叶斯将虚构的新闻标题分类为“电影”和“宇宙”两个类别。
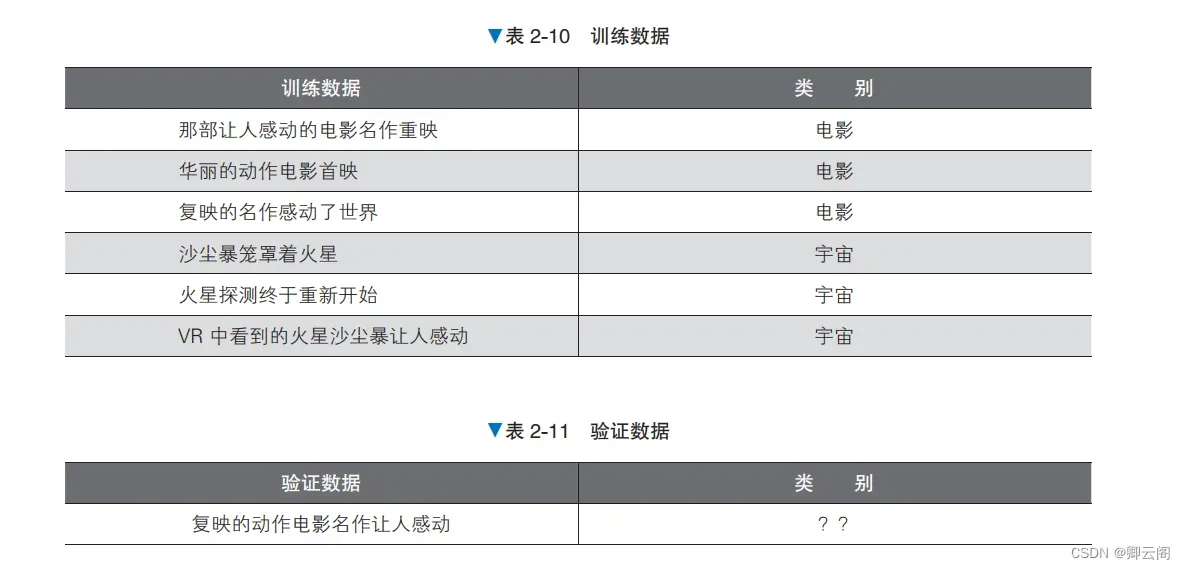
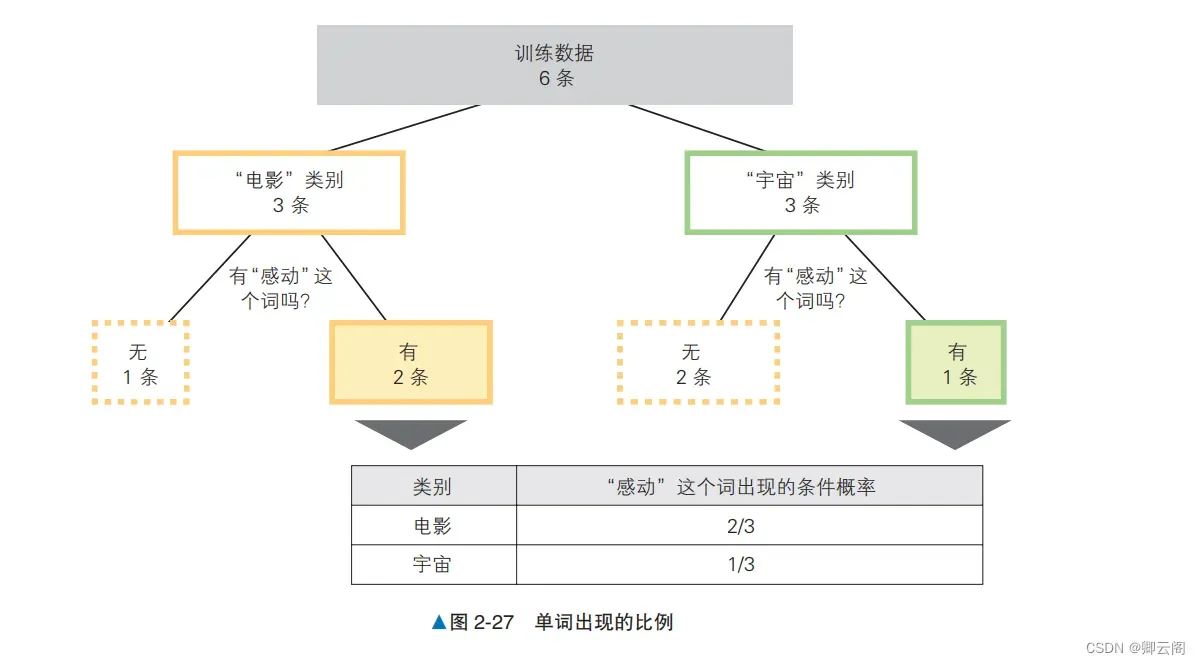
验证数据是作为“电影”类别的新闻标题生成的,但这里我们当作不知道它的类别。下面思考根据训练数据计算未知数据的类别是“电影”还是“宇宙”的概率的方法。训练数 据中类别为“电影”的数据有 3 条,类别为“宇宙”的数据也有 3 条。简单地计算一下,可知未知 数据的类别为“电影”的概率是 3/6=50%,同样地,类别为“宇宙”的概率也是 50%。这个方法虽 然很简单,但是如果采用这个计算方法,那么不管未知数据中的文本是什么,分类为各个类别的概 率都是固定的。朴素贝叶斯基于文本中包含的单词推测未知数据的类别。我们关注一下验证数据中包含的“感动”这个词。这个词在哪个类别里都会出现,但是出现的比例在每个类别里都不一样。在“电影”类别的数据中出现“感动”这个词的概率是 2/3 ≈ 67%,在“宇宙”类别的数据中则是 1/3 ≈ 33%,可见这个词更容易出现在“电影”类别的数据中。另外,在出现“感动”这个词的数据中,类别为“电影”的概率是 2/3 ≈ 67%,为“宇宙”的概率是 1/3 ≈ 33%。如果对使用验证 数据中的“感动”这个词进行筛选后的数据计算比例,类别是“电影”的概率更高。此处求得的在 某个条件(这次的条件是“感动”这个词出现)下的概率叫作条件概率。朴素贝叶斯不仅使用了单词在文本中出现的比例,还使用了每个单词的条件概率,通过文本中 单词的信息提高了计算精度。🍉二、算法说明
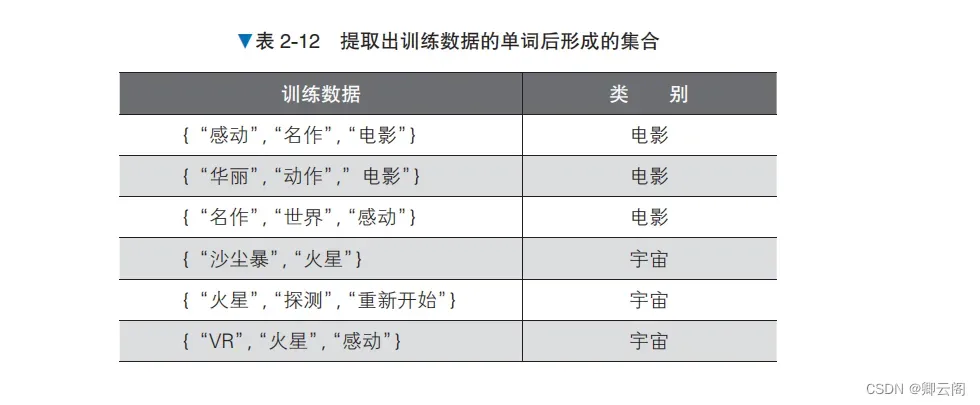
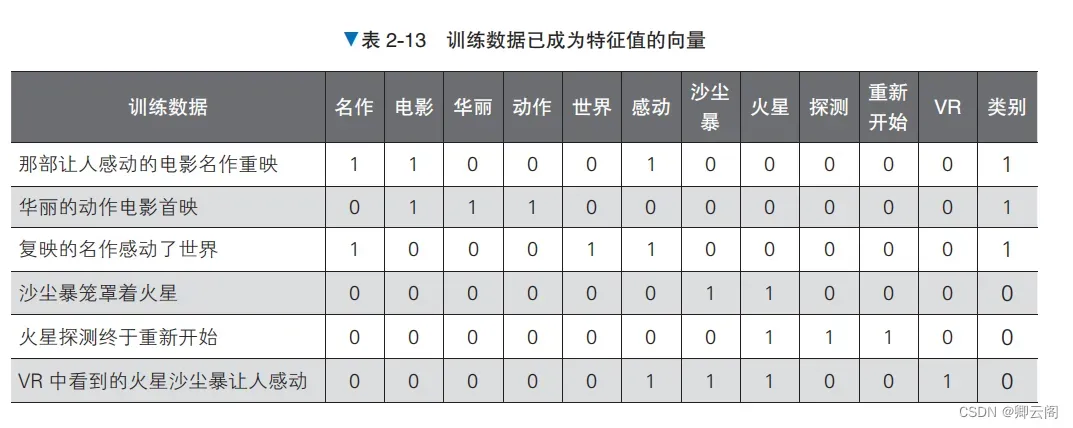
虽然最终要做的是自然语言处理的分类,但在应用朴素贝叶斯时,还需要将输入数据转换为由特征值构成的向量。我们先在预处理阶段将文本转换为由特征值构成的向量,然后使用朴素贝叶斯 进行训练,最后查看结果。预处理在预处理阶段,我们将文本转换为 BoW(Bag of Words,词袋)的形式,形成由特征值构成的 向量和标签的组合。先从现有的训练数据的文本中只提取出名词,忽略名词在文本中的顺序,把它们作为集合处理 A。接下来,将训练数据和类别转换为易于处理的数据形式。当所有单词的集合包含训练数据的单 词时,将该单词列的值设为 1,否则设为 0。另外,当类别为“电影”时,将类别的值替换为 1;当 类别为“宇宙”时,将类别的值替换为 0,结果如表 2-13 所示。这些就是标签。通过以上处理,我们可以将以自然语言书写的文本转换为表示单词出现的特征值和标签的组
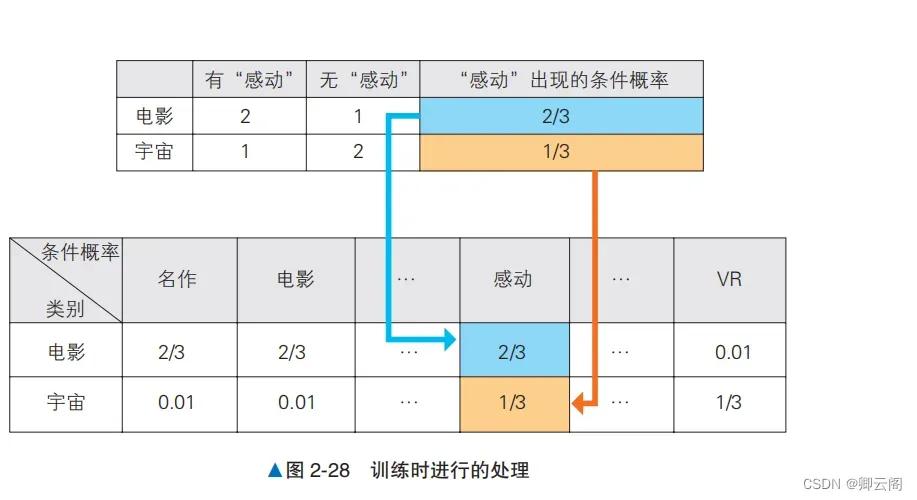
合,这种文本表示方式称为 BoW。下面采用同样的做法处理验证数据。验证数据中包含了训练数 据中不包含的“复映”一词通过实施上述预处理,本次的问题就变为了预测验证数据 [1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0] 的类别的问题。概率的计算朴素贝叶斯使用训练数据来学习与各标签对应的单词的出现概率。在分类时求出每个标签对应 的概率,将概率最高的标签作为分类结果。朴素贝叶斯在训练时计算以下两种概率。1. 每个标签出现的概率。2. 在各标签下,每个单词出现的条件概率。对朴素贝叶斯在训练时进行的处理进行汇总,如图 2-28 所示。注意,图中只展示了部分特征值的列。在图 2-8 中应该分配概率 0 的地方,我们分配了小的概率值 0.01,这种做法叫作平滑(smoothing)。概率为 0 的位置表示在对应的训练数据中没有出现对应的单词,但是如果使用更大的数据集作为训 练数据,那个单词却真有可能出现。平滑处理考虑到了这种可能性,在没有出现单词的位置也分配 小的概率值。 在分类时,朴素贝叶斯分别为每个标签值计算上述两个概率的乘积,通过比较进行分类。例如,在对本次的验证数据 [1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0](“复映的动作电影名作让人感动”)这个文本进行分类时,实际比较的是下列处理的结果。1. 求出“电影”类别的文本出现的概率。2. 从“电影”类别的文本中分别求出“名作”“动作”“感动”这几个单词出现的概率。3. 对于文本中没有出现的单词,也要求出在“电影”类别的文本中没有出现的概率。4. 计算所有概率的乘积。上述处理如图 2-29 所示。按标签比较图 2-29 中的处理的结果,输出其中概率最大的标签作为 分类结果。2-29 中分别计算了作为特征值的每个单词的概率,没有考虑单词的顺序和组合。朴素贝叶斯通过“每个单词都是独立的”这样一个简单的假设简化了学习过程。示例代码下面实际编写代码来查看计算结果from sklearn.naive_bayes import MultinomialNB # 生成数据 X_train = [[1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0], [0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1]] y_train = [1, 1, 1, 0, 0, 0] model = MultinomialNB() model.fit(X_train, y_train) # 训练 model.predict([[1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0]]) # 评估array([1])这里得到的 array([1]) 意味着类别是“电影”,说明这次的判断是正确的。
🍊三、详细说明
朴素贝叶斯是自然语言分类的基础算法,但是不适合预测天气预报中的降水概率那种预测值是 概率本身的情况。前面的“算法说明”部分提到过,朴素贝叶斯基于“每个单词的概率可以独立计 算”的假设,这是为了使概率的计算方法尽量简单。这个假设忽略了文本中单词之间的关联性。如果要计算的概率值很重要,则应该避免直接将由朴素贝叶斯算出的值用作概率。另外,朴素贝叶斯的“即使将各自的特征作为独立的变量来处理,也可以计算出概率”这一假设对于某些学习任务不成立。例如,如果单词在不同的上下文中含义不同,那么朴素贝叶斯的假设是不成立的。“踢”这个单词常常在格斗等运动的文本中出现,但是如果文本中出现了“踢了球” 的用法,那么此时文本的主题很有可能是足球。这种单词含义在不同的上下文中有所变化的情况是 不满足朴素贝叶斯“所有特征都是相互独立的”这一假设的。如果要考虑单词的上下文,就需要根据不同的上下文考虑使用其他模型。🍋四、朴素贝叶斯的应用
利用朴素贝叶斯对fetch_20newsgroups数据集进行预测 代码如下:
from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer def naivebayes(): #朴素贝叶斯算法进行文本分类 #获取数据 news = fetch_20newsgroups(subset='all') #拆分训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25) #特征工程 #使用tf-idf进行文本特征抽取 tf = TfidfVectorizer() #以训练集中词的列表进行每篇文章重要性统计 x_train = tf.fit_transform(x_train) x_test = tf.transform(x_test) #调用朴素贝叶斯算法 alpha为拉普拉斯平滑系数 nav = MultinomialNB(alpha=1.0) nav.fit(x_train,y_train) y_predict = nav.predict(x_test) score = nav.score(x_test,y_test) print(tf.get_feature_names()) print(x_train) print("预测的文章类型:",y_predict) print("准确率:",score) return None if __name__ == "__main__": naivebayes()预测的文章类型: [17 17 12 ... 4 7 12] 准确率: 0.8508064516129032


文章出处登录后可见!
已经登录?立即刷新