🥧 我的环境:
- 语言环境:Python3
- 深度学习环境:TensorFlow2
🥂 相关教程:
- 编译器教程:新手入门深度学习 | 1-2:编译器Jupyter Notebook
- 深度学习环境配置教程:新手入门深度学习 | 1-1:配置深度学习环境
- 一个深度学习小白需要的所有资料我都放这里了:新手入门深度学习 | 目录
建议你学习本文之前先看看下面这篇入门文章,以便你可以更好的理解本文:
强烈建议大家使用Jupyter Lab编译器打开源码,你接下来的操作将会非常便捷的!
大家好,我是K同学啊!这次为大家准备了一个天气识别的实例,文章我采用了VGG16、ResNet50、IceptionV3、DenseNet121、LeNet-5、MobileNetV2、EfficientNetB0等7个模型来识别天气,使用的数据集包含 5,531 张不同类型天气的图像,最后模型的识别准确率为 93.9% 。
🍰 重点说明:本文为大家准备了多个算法进行对比分析,每一个算法的学习率都是独立的,你可以自由调整。并且为你提供了准确率(Accuracy)、损失(Loss)、召回率(recall)、精确率(precision)以及AUC值等众多指标的对比分析,你只需要选择需要对比的模型、指标以及数据集即可进行相应的对比分析。
🍡 在本代码中你还可以探究的内容如下:
- 同一个学习率对不同模型的影响
- 同一个模型在不同学习率下的性能
- Dropout层的作用(解决过拟合问题)
🍳 效果展示:
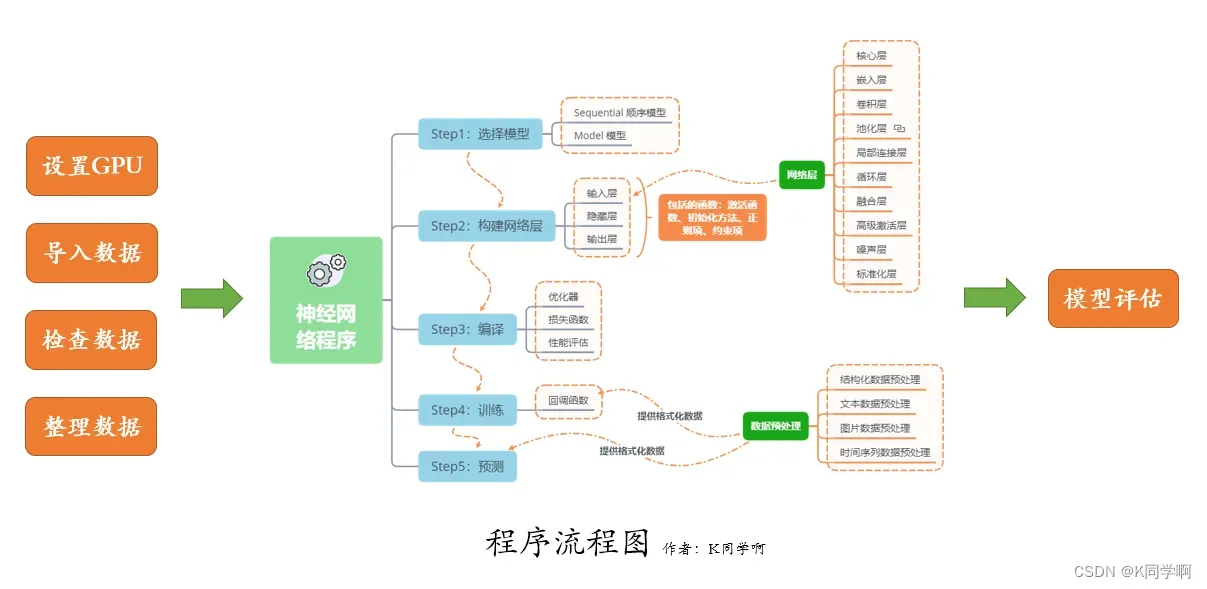
我们的代码流程图如下所示:
🍔 前期准备工作
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 打印显卡信息,确认GPU可用
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
🥗 导入数据
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./2-DataSet/",
validation_split=0.2,
subset="training",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5531 files belonging to 9 classes.
Using 4425 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./2-DataSet/",
validation_split=0.2,
subset="validation",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5531 files belonging to 9 classes.
Using 1106 files for validation.
class_names = train_ds.class_names
print(class_names)
['dew', 'fogsmog', 'frost', 'hail', 'lightning', 'rain', 'rainbow', 'rime', 'snow']
AUTOTUNE = tf.data.AUTOTUNE
# 归一化
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
plt.figure(figsize=(14, 8)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(28):
plt.subplot(4, 7, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
plt.title(class_names[np.argmax(labels[i])])
plt.show()

🥙 设置评估指标metrics
评估指标用于衡量深度学习算法模型的质量,评估深度学习算法模型对于任何项目都是必不可少的。在深度学习中,也有许多不同类型的评估指标可用于衡量算法模型,例如accuracy、precision、recall、auc等都是常用的评估指标。
关于评估指标metrics的详细介绍请参考:🍦新手入门深度学习 | 3-5:评估指标metrics
metrics = [
tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.AUC(name='auc')
]
🍟 定义模型
🥪 VGG16模型
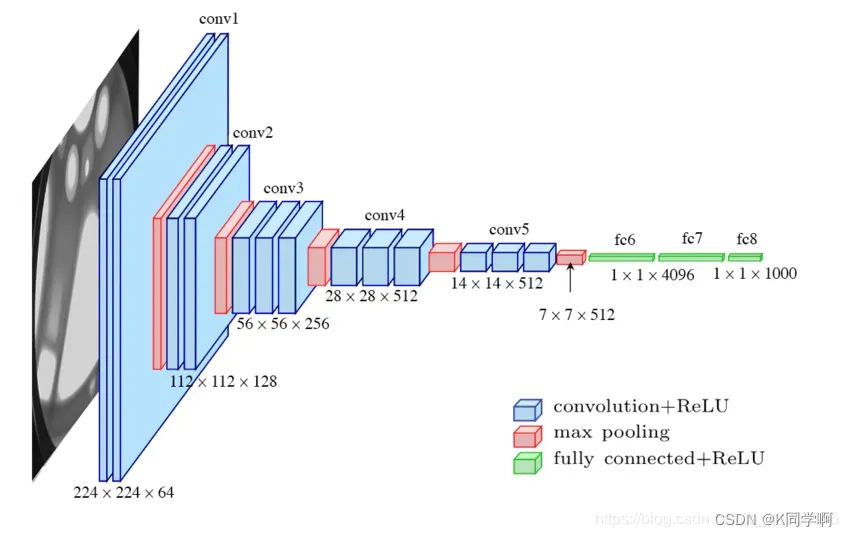
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
# input_tensor=tf.keras.Input(shape=(img_width, img_height, 3)),
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in vgg16_base_model.layers:
layer.trainable = True
X = vgg16_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=70, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(lr_schedule) # 这里选择不使用动态学习率
vgg16_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics = metrics)
# vgg16_model.summary()
🌮 ResNet50模型
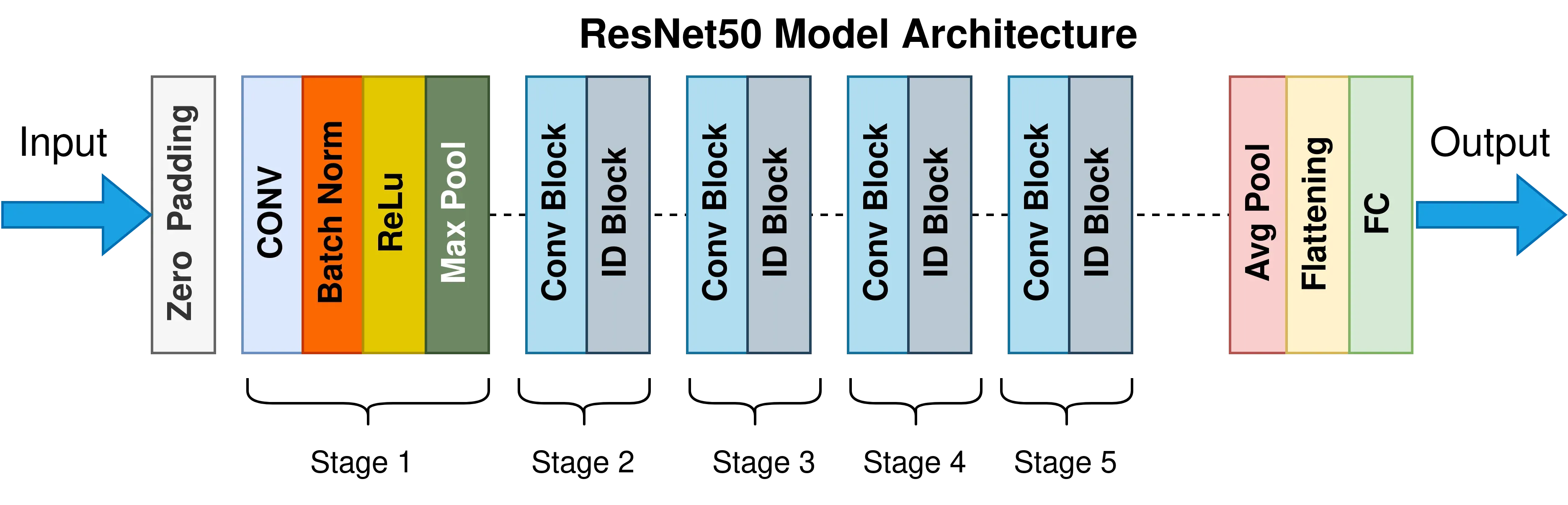
# 加载预训练模型
resnet50_base_model = tf.keras.applications.resnet50.ResNet50(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in resnet50_base_model.layers:
layer.trainable = True
X = resnet50_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
resnet50_model = Model(inputs=resnet50_base_model.input, outputs=output)
# optimizer = tf.keras.optimizers.Adam(lr_schedule)
resnet50_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics= metrics)
# resnet50_model.summary()
🌯 InceptionV3模型
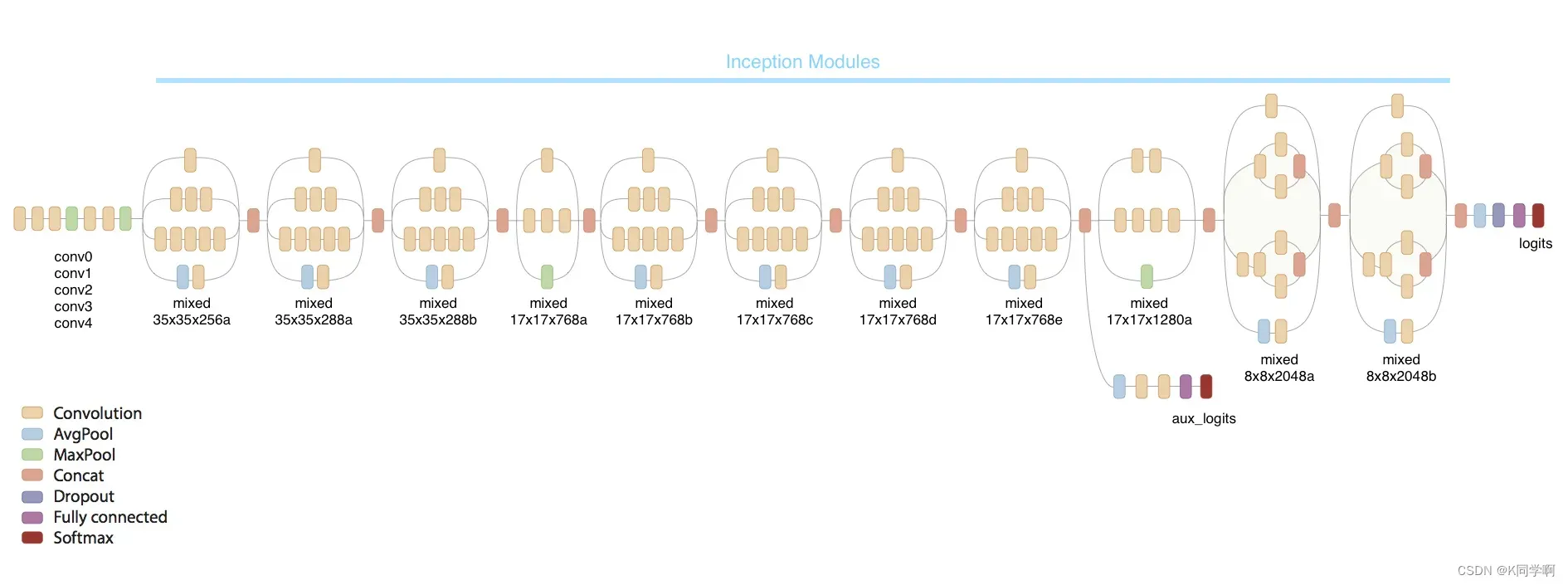
# 加载预训练模型
InceptionV3_base_model = tf.keras.applications.inception_v3.InceptionV3(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in InceptionV3_base_model.layers:
layer.trainable = True
X = InceptionV3_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
InceptionV3_model = Model(inputs=InceptionV3_base_model.input, outputs=output)
InceptionV3_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics= metrics)
# InceptionV3_model.summary()
🥫 DenseNet121算法模型
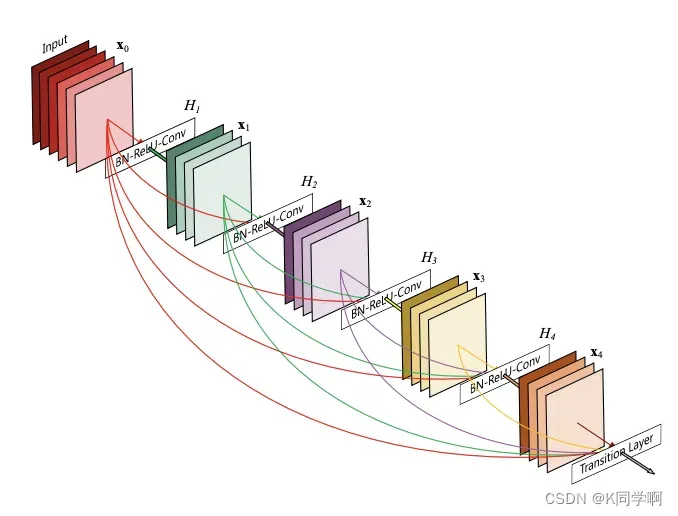
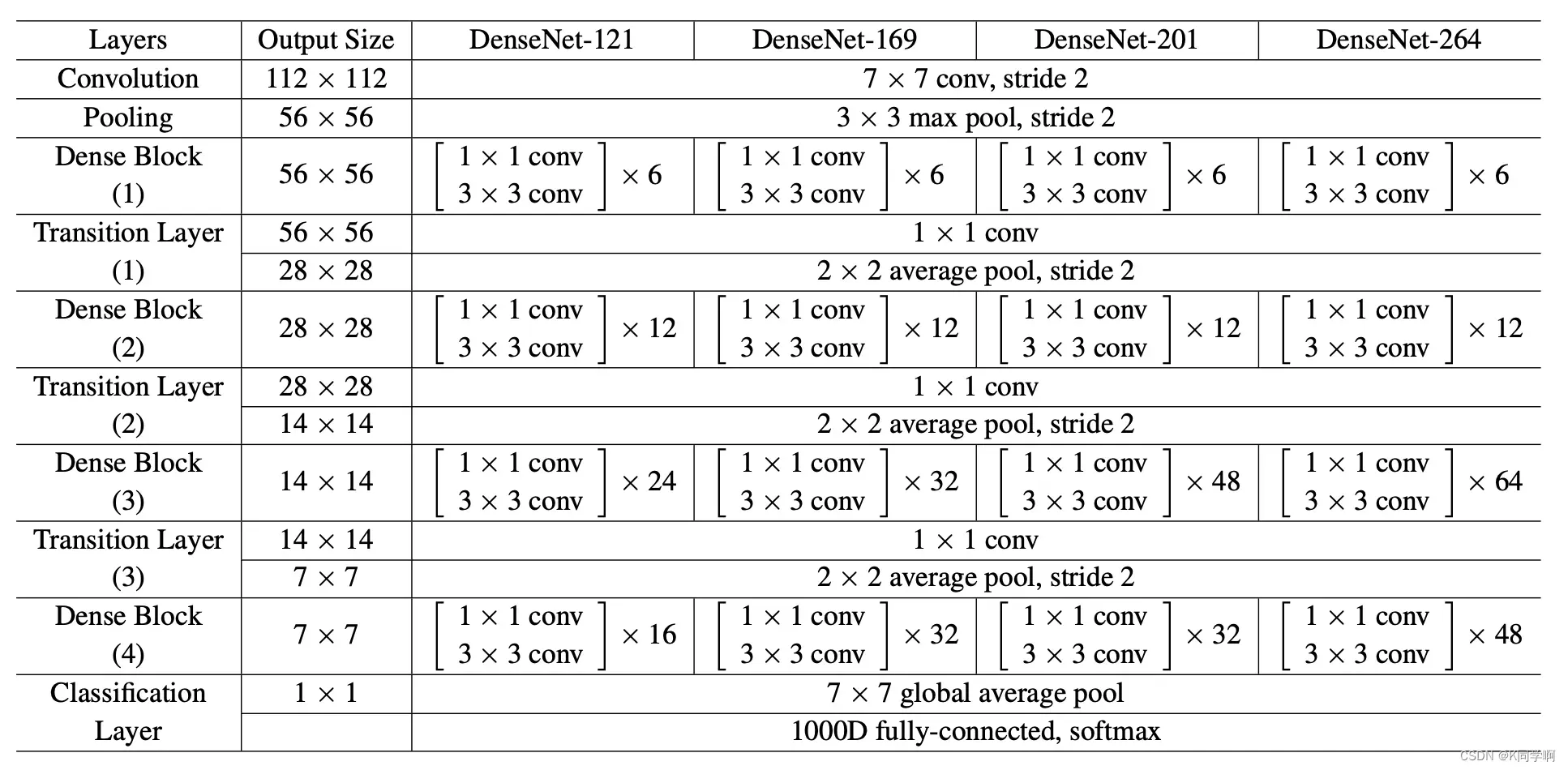
# 加载预训练模型
DenseNet121_base_model = tf.keras.applications.densenet.DenseNet121(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in DenseNet121_base_model.layers:
layer.trainable = True
X = DenseNet121_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
DenseNet121_model = Model(inputs=DenseNet121_base_model.input, outputs=output)
DenseNet121_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics= metrics)
# model.summary()
🍛 LeNet-5模型
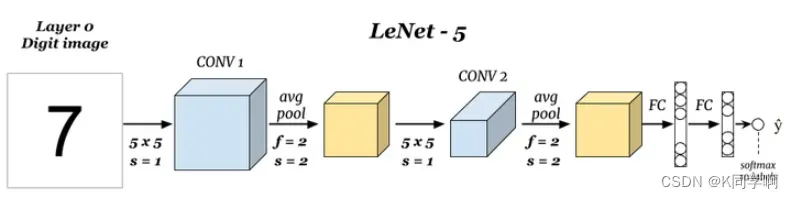
LeNet5_model = keras.Sequential([
# 卷积层1
keras.layers.Conv2D(6, 5), # 使用6个5*5的卷积核对单通道32*32的图片进行卷积,结果得到6个28*28的特征图
keras.layers.MaxPooling2D(pool_size=2, strides=2), # 对28*28的特征图进行2*2最大池化,得到14*14的特征图
keras.layers.ReLU(), # ReLU激活函数
# 卷积层2
keras.layers.Conv2D(16, 5), # 使用16个5*5的卷积核对6通道14*14的图片进行卷积,结果得到16个10*10的特征图
keras.layers.MaxPooling2D(pool_size=2, strides=2), # 对10*10的特征图进行2*2最大池化,得到5*5的特征图
keras.layers.ReLU(), # ReLU激活函数
keras.layers.Flatten(),
# 全连接层1
keras.layers.Dense(500, activation='relu'), # 32*84
# 全连接层2
keras.layers.Dense(100, activation='relu'), # 32*84
# 全连接层2
keras.layers.Dense(len(class_names), activation='softmax') # 32*10
])
LeNet5_model.build(input_shape=(batch_size, img_width,img_height,3))
# LeNet5_model.summary()
LeNet5_model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
metrics= metrics)
🍜 MobileNetV2算法模型
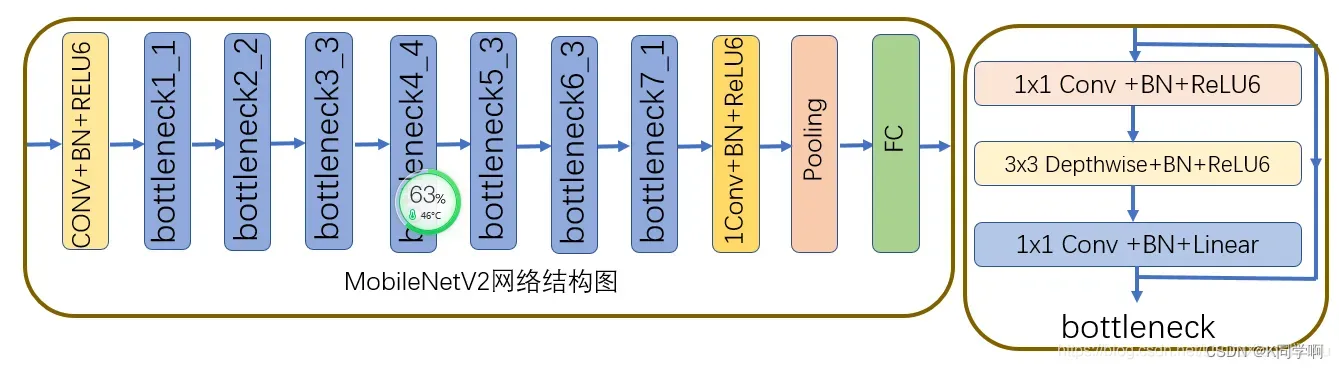
# 加载预训练模型
MobileNetV2_base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in MobileNetV2_base_model.layers:
layer.trainable = True
X = MobileNetV2_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
MobileNetV2_model = Model(inputs=MobileNetV2_base_model.input, outputs=output)
MobileNetV2_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics= metrics)
# model.summary()
🥡 EfficientNetB0算法模型
EfficientNetB0_base_model = tf.keras.applications.efficientnet.EfficientNetB0(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='max')
for layer in EfficientNetB0_base_model.layers:
layer.trainable = True
X = EfficientNetB0_base_model.output
# X = Dropout(0.3)(X)
output = Dense(len(class_names), activation='softmax')(X)
EfficientNetB0_model = Model(inputs=EfficientNetB0_base_model.input, outputs=output)
EfficientNetB0_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='categorical_crossentropy',
metrics= metrics)
# EfficientNetB0_model.summary()
🌭 训练模型
vgg16_history = vgg16_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 35s 184ms/step - loss: 0.8009 - accuracy: 0.7313 - precision: 0.8380 - recall: 0.6466 - auc: 0.9579 - val_loss: 0.4339 - val_accuracy: 0.8472 - val_precision: 0.8938 - val_recall: 0.8065 - val_auc: 0.9867
Epoch 2/30
139/139 [==============================] - 18s 133ms/step - loss: 0.3605 - accuracy: 0.8744 - precision: 0.9090 - recall: 0.8447 - auc: 0.9904 - val_loss: 0.3253 - val_accuracy: 0.8933 - val_precision: 0.9251 - val_recall: 0.8599 - val_auc: 0.9924
......
Epoch 30/30
139/139 [==============================] - 19s 134ms/step - loss: 7.2972e-05 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - val_loss: 0.3784 - val_accuracy: 0.9394 - val_precision: 0.9410 - val_recall: 0.9367 - val_auc: 0.9852
resnet50_history = resnet50_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 21s 124ms/step - loss: 1.5570 - accuracy: 0.8165 - precision: 0.8231 - recall: 0.8134 - auc: 0.9424 - val_loss: 8.3198 - val_accuracy: 0.0642 - val_precision: 0.0643 - val_recall: 0.0642 - val_auc: 0.4878
Epoch 2/30
139/139 [==============================] - 16s 115ms/step - loss: 0.0972 - accuracy: 0.9756 - precision: 0.9762 - recall: 0.9749 - auc: 0.9969 - val_loss: 12.0035 - val_accuracy: 0.1646 - val_precision: 0.1646 - val_recall: 0.1646 - val_auc: 0.5218
。。。。。。
Epoch 30/30
139/139 [==============================] - 16s 115ms/step - loss: 3.2757e-06 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - val_loss: 0.4380 - val_accuracy: 0.9358 - val_precision: 0.9365 - val_recall: 0.9340 - val_auc: 0.9823
InceptionV3_history = InceptionV3_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 21s 109ms/step - loss: 0.6351 - accuracy: 0.8291 - precision: 0.8708 - recall: 0.7968 - auc: 0.9752 - val_loss: 0.4674 - val_accuracy: 0.8553 - val_precision: 0.8660 - val_recall: 0.8418 - val_auc: 0.9839
Epoch 2/30
139/139 [==============================] - 13s 92ms/step - loss: 0.0451 - accuracy: 0.9876 - precision: 0.9907 - recall: 0.9835 - auc: 0.9999 - val_loss: 0.3189 - val_accuracy: 0.9105 - val_precision: 0.9201 - val_recall: 0.9060 - val_auc: 0.9904
......
Epoch 30/30
139/139 [==============================] - 13s 92ms/step - loss: 1.6310e-05 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - val_loss: 0.3224 - val_accuracy: 0.9231 - val_precision: 0.9264 - val_recall: 0.9222 - val_auc: 0.9884
DenseNet121_history = DenseNet121_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 30s 158ms/step - loss: 0.9439 - accuracy: 0.8006 - precision: 0.8226 - recall: 0.7872 - auc: 0.9602 - val_loss: 0.4637 - val_accuracy: 0.8725 - val_precision: 0.8860 - val_recall: 0.8644 - val_auc: 0.9817
Epoch 2/30
139/139 [==============================] - 19s 135ms/step - loss: 0.0615 - accuracy: 0.9792 - precision: 0.9812 - recall: 0.9772 - auc: 0.9994 - val_loss: 0.3314 - val_accuracy: 0.9105 - val_precision: 0.9150 - val_recall: 0.9051 - val_auc: 0.9897
。。。。。。
Epoch 30/30
139/139 [==============================] - 19s 135ms/step - loss: 3.9534e-05 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - val_loss: 0.2790 - val_accuracy: 0.9304 - val_precision: 0.9318 - val_recall: 0.9259 - val_auc: 0.9911
LeNet5_history = LeNet5_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 3s 17ms/step - loss: 1.5704 - accuracy: 0.5485 - precision: 0.8639 - recall: 0.3410 - auc: 0.8849 - val_loss: 1.2588 - val_accuracy: 0.5696 - val_precision: 0.7702 - val_recall: 0.3879 - val_auc: 0.9004
Epoch 2/30
139/139 [==============================] - 2s 15ms/step - loss: 1.1065 - accuracy: 0.6350 - precision: 0.8069 - recall: 0.4495 - auc: 0.9224 - val_loss: 1.0188 - val_accuracy: 0.6754 - val_precision: 0.7986 - val_recall: 0.5054 - val_auc: 0.9342
......
Epoch 30/30
139/139 [==============================] - 2s 15ms/step - loss: 0.3052 - accuracy: 0.9306 - precision: 0.9611 - recall: 0.8884 - auc: 0.9943 - val_loss: 0.7361 - val_accuracy: 0.7649 - val_precision: 0.8367 - val_recall: 0.7134 - val_auc: 0.9646
MobileNetV2_history = MobileNetV2_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 19s 117ms/step - loss: 1.3687 - accuracy: 0.7252 - precision: 0.7581 - recall: 0.7064 - auc: 0.9281 - val_loss: 1.4920 - val_accuracy: 0.7043 - val_precision: 0.7203 - val_recall: 0.6917 - val_auc: 0.9184
Epoch 2/30
139/139 [==============================] - 15s 109ms/step - loss: 0.0676 - accuracy: 0.9792 - precision: 0.9798 - recall: 0.9765 - auc: 0.9992 - val_loss: 1.4331 - val_accuracy: 0.7260 - val_precision: 0.7380 - val_recall: 0.7206 - val_auc: 0.9241
。。。。。。
Epoch 30/30
139/139 [==============================] - 15s 108ms/step - loss: 5.0026e-05 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - val_loss: 0.4606 - val_accuracy: 0.8933 - val_precision: 0.8955 - val_recall: 0.8915 - val_auc: 0.9807 1.0000 - precision: 1.0000 - recall: 1.0000 -
EfficientNetB0_history = EfficientNetB0_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/30
139/139 [==============================] - 28s 162ms/step - loss: 1.6410 - accuracy: 0.6706 - precision: 0.7080 - recall: 0.6478 - auc: 0.9135 - val_loss: 9.5856 - val_accuracy: 0.0696 - val_precision: 0.0696 - val_recall: 0.0696 - val_auc: 0.4577
Epoch 2/30
139/139 [==============================] - 21s 151ms/step - loss: 0.3428 - accuracy: 0.8856 - precision: 0.9044 - recall: 0.8723 - auc: 0.9895 - val_loss: 3.5993 - val_accuracy: 0.0832 - val_precision: 0.0911 - val_recall: 0.0642 - val_auc: 0.5274
......
Epoch 30/30
139/139 [==============================] - 21s 151ms/step - loss: 0.0067 - accuracy: 0.9989 - precision: 0.9991 - recall: 0.9984 - auc: 1.0000 - val_loss: 0.9306 - val_accuracy: 0.7920 - val_precision: 0.8105 - val_recall: 0.7848 - val_auc: 0.9535
🍿 结果分析
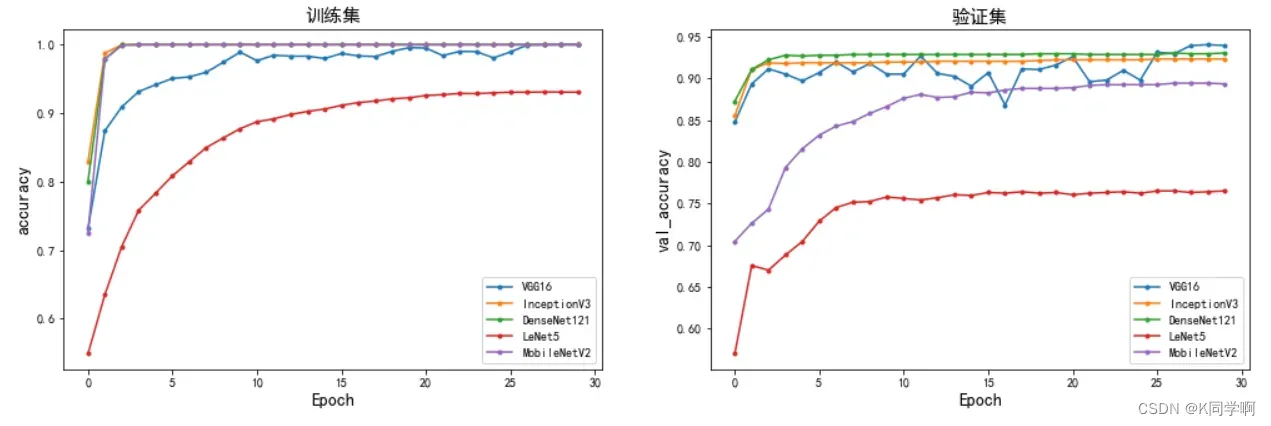
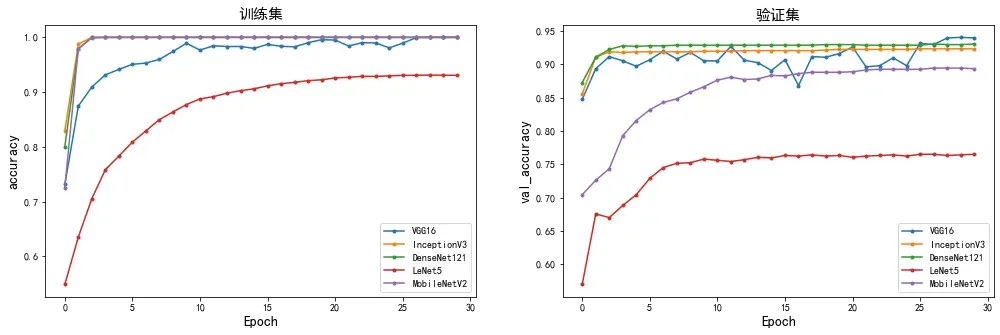
🦪 准确率对比分析
plot_model(["VGG16","InceptionV3","DenseNet121","LeNet5","MobileNetV2"],
[vgg16_history,InceptionV3_history,DenseNet121_history,LeNet5_history,MobileNetV2_history],
["accuracy","val_accuracy"],
marker = ".")
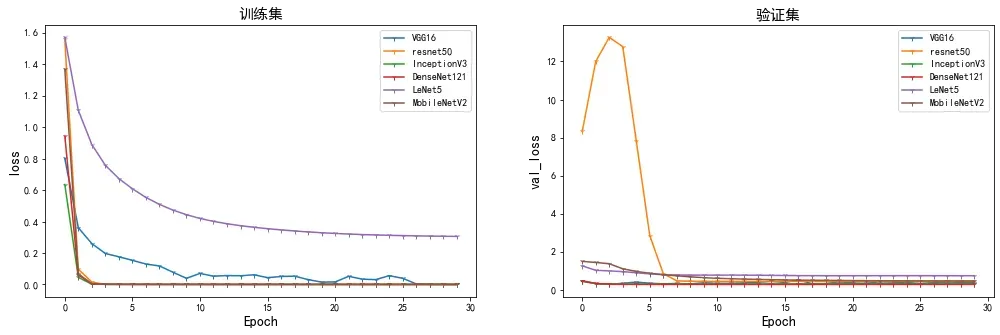
🍣 损失对比分析
plot_model(["VGG16","resnet50","InceptionV3","DenseNet121","LeNet5","MobileNetV2"],
[vgg16_history,resnet50_history,InceptionV3_history,DenseNet121_history,LeNet5_history,MobileNetV2_history],
["loss","val_loss"],
marker = "1")
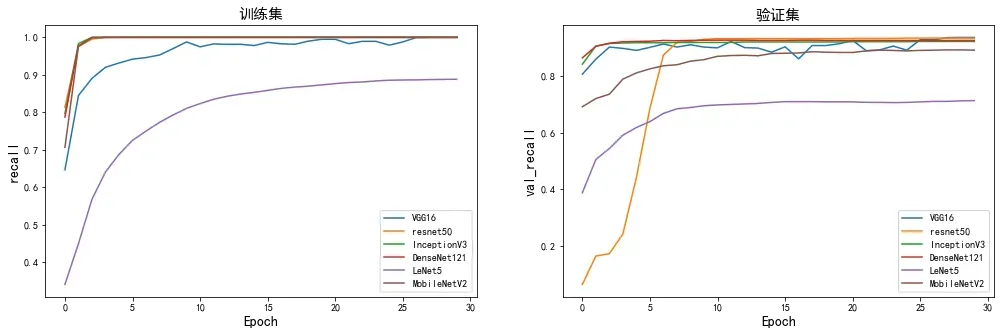
🍤 召回率对比分析
召回率(Recall),也称查全率,是被正确分类的正例(反例)样本,占所有正例(反例)样本的比例。
plot_model(["VGG16","resnet50","InceptionV3","DenseNet121","LeNet5","MobileNetV2"],
[vgg16_history,resnet50_history,InceptionV3_history,DenseNet121_history,LeNet5_history,MobileNetV2_history],
["recall","val_recall"],
marker = "")
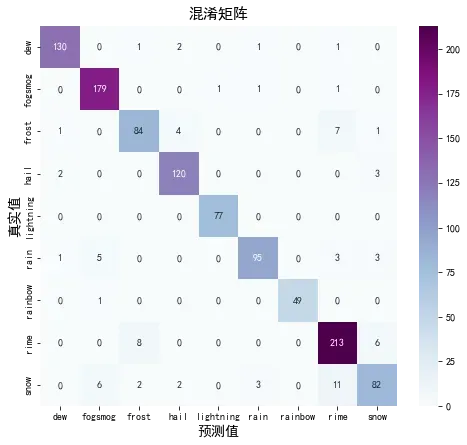
🍘 混淆矩阵
val_pre = []
val_label = []
for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵
for image, label in zip(images, labels):
# 需要给图片增加一个维度
img_array = tf.expand_dims(image, 0)
prediction = DenseNet121_model.predict(img_array)
val_pre.append(np.argmax(prediction))
val_label.append([np.argmax(one_hot)for one_hot in [label]])
plot_cm(val_label, val_pre)
🍙 评估指标生成
support:当前行的类别在测试数据中的样本总量;precision:被判定为正例(反例)的样本中,真正的正例样本(反例样本)的比例,精度=正确预测的个数(TP)/被预测正确的个数(TP+FP)。recall:被正确分类的正例(反例)样本,占所有正例(反例)样本的比例,召回率=正确预测的个数(TP)/预测个数(TP+FN)。f1-score: 精确率和召回率的调和平均值,F1 = 2精度召回率/(精度+召回率)。accuracy:表示准确率,也即正确预测样本量与总样本量的比值。macro avg:表示宏平均,表示所有类别对应指标的平均值。weighted avg:表示带权重平均,表示类别样本占总样本的比重与对应指标的乘积的累加和。
from sklearn import metrics
def test_accuracy_report(model):
print(metrics.classification_report(val_label, val_pre, target_names=class_names))
score = model.evaluate(val_ds, verbose=0)
print('Loss: %s, Accuracy:' % score[0], score[1])
test_accuracy_report(vgg16_model)
precision recall f1-score support
dew 0.97 0.96 0.97 135
fogsmog 0.94 0.98 0.96 182
frost 0.88 0.87 0.87 97
hail 0.94 0.96 0.95 125
lightning 0.99 1.00 0.99 77
rain 0.95 0.89 0.92 107
rainbow 1.00 0.98 0.99 50
rime 0.90 0.94 0.92 227
snow 0.86 0.77 0.82 106
accuracy 0.93 1106
macro avg 0.94 0.93 0.93 1106
weighted avg 0.93 0.93 0.93 1106
Loss: 0.3783927857875824, Accuracy: 0.9394213557243347
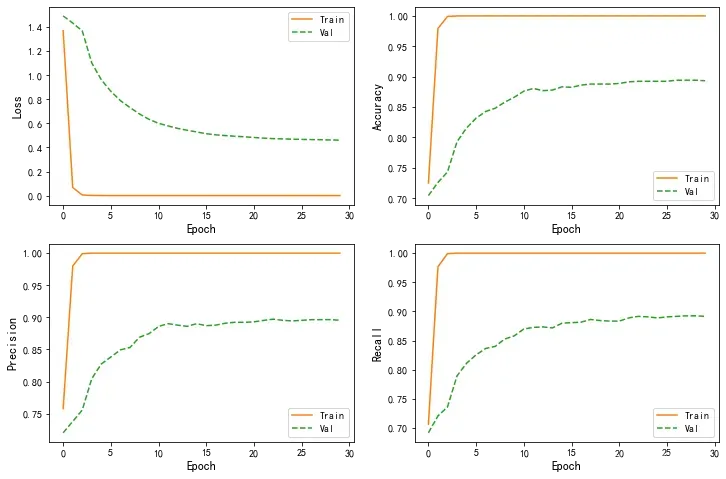
🍥 Loss/accuracy/Precision/Recall对比分析
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
plt.figure(figsize=(12,8))
def plot_metrics(history):
metrics = ['loss', 'accuracy', 'precision', 'recall']
for n, metric in enumerate(metrics):
name = metric.replace("_"," ").capitalize()
plt.subplot(2,2,n+1)
plt.plot(history.epoch, history.history[metric], color=colors[1], label='Train')
plt.plot(history.epoch, history.history['val_'+metric],color=colors[2],
linestyle="--", label='Val')
plt.xlabel('Epoch',fontsize=12)
plt.ylabel(name,fontsize=12)
plt.legend()
plot_metrics(MobileNetV2_history)
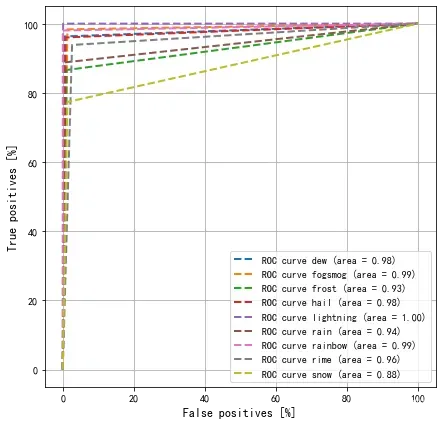
🥮 AUC
即ROC曲线(TPR vs FPR)下的面积,其值在0~1之间,AUC值越高,代表分类器效果越好。更详细的介绍请看AUC 评价指标详解,准确率(ACC),敏感性(sensitivity),特异性(specificity)计算 Python3【TensorFlow2入门手册】一文。
关于ROC曲线应用的其他实例:
import sklearn
from tensorflow.keras.utils import to_categorical
def plot_roc( labelsـ, predictions):
fpr = dict()
tpr = dict()
roc_auc = dict()
temp = class_names
for i, item in enumerate(temp):
fpr[i], tpr[i], _ = sklearn.metrics.roc_curve(labelsـ[:, i], predictions[:, i])
roc_auc[i] = sklearn.metrics.auc(fpr[i], tpr[i])
plt.subplots(figsize=(7, 7))
for i, item in enumerate(temp):
plt.plot(100*fpr[i], 100*tpr[i], label=f'ROC curve {item} (area = {roc_auc[i]:.2f})', linewidth=2, linestyle="--")
plt.xlabel('False positives [%]',fontsize=12)
plt.ylabel('True positives [%]',fontsize=12)
plt.legend(loc="lower right")
plt.grid(True)
# 调用函数
plot_roc(to_categorical(val_label), to_categorical(val_pre))
🍨 指定图片进行预测
from PIL import Image
img = Image.open("./2-DataSet/fogsmog/4083.jpg")
image = tf.image.resize(img, [img_height, img_width])/255.0
img_array = tf.expand_dims(image, 0)
predictions = vgg16_model.predict(img_array)
print("预测结果为:",class_names[np.argmax(predictions)])
预测结果为: fogsmog
🥤 点击我获取 数据+代码 🥤
文章出处登录后可见!