读入训练集和测试集
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
from keras.datasets import mnist #从Keras中导入mnist数据集
#读入训练集和测试集
(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data()
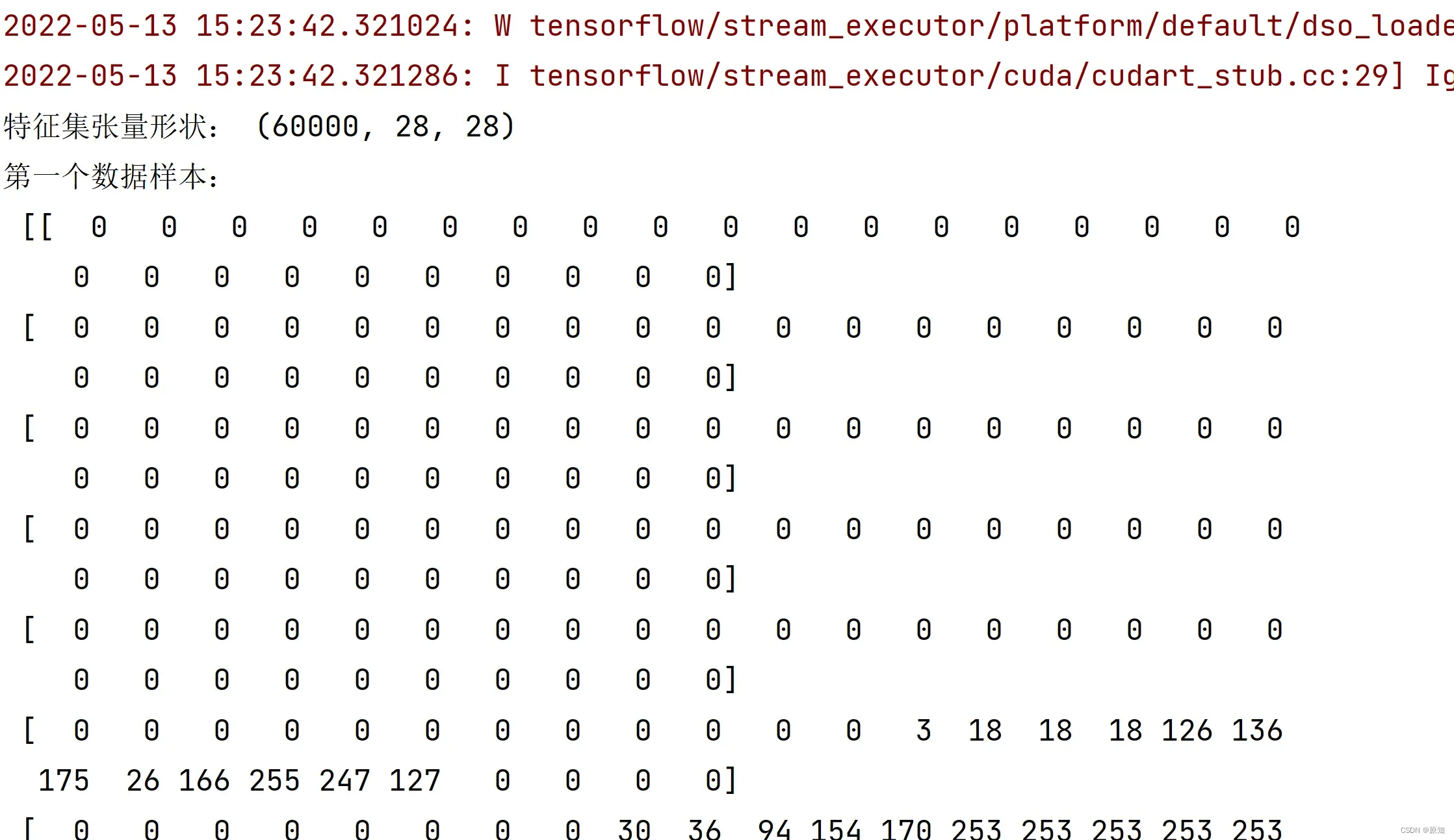
print ("特征集张量形状:", X_train_image.shape) #用shape方法显示张量的形状
print ("第一个数据样本:\n", X_train_image[0]) #注意Python的索引是从0开始的
print ("第一个数据样本的标签:", y_train_lable[0])
注:
X_train_image:训练集特征:图片
y_train_lable:训练集标签:数字
X_test_image:测试集特征:图片
y_test_lable:测试集标签:数字
关于mnist的详细信息可看博客:https://blog.csdn.net/bwqiang/article/details/110203835
获取前10条MNSIT数据集的图片形式
import matplotlib.pyplot as plt
for i in range(10):
img = np.reshape(X_train_image [i, :], (28, 28))
label = np.argmax(X_train_image [i, :])
plt.matshow(img, cmap = plt.get_cmap('gray'))
plt.show()
用卷积神经网络处理MNIST数据集
注:这里还有一些问题没搞明白,弄懂之后再回来补充
from tensorflow.keras.utils import to_categorical # 导入keras.utils工具箱的类别转换工具
X_train = X_train_image.reshape(60000,28,28,1) # 给标签增加一个维度
X_test = X_test_image.reshape(10000,28,28,1) # 给标签增加一个维度
y_train = to_categorical(y_train_lable, 10) # 特征转换为one-hot编码
y_test = to_categorical(y_test_lable, 10) # 特征转换为one-hot编码
print ("数据集张量形状:", X_train.shape) # 特征集张量的形状
print ("第一个数据标签:",y_train[0]) # 显示标签集的第一个数据
from keras import models # 导入Keras模型, 和各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = models.Sequential() # 用序贯方式建立模型
model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层
input_shape=(28,28,1))) # 指定输入数据样本张量的类型,张量用来存储高阶数组,但本质上标量,向量,矩阵都可以看作是张量的特殊形式
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 展平
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活,输出10维分类码
# 编译模型
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定验证过程中的评估指标
#对机器学习进行5轮的训练
model.fit(X_train, y_train, # 指定训练特征集和训练标签集
validation_split = 0.3, # 部分训练集数据拆分成验证集
epochs=5, # 训练轮次为5轮
batch_size=128) # 以128为批量进行训练",
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率",
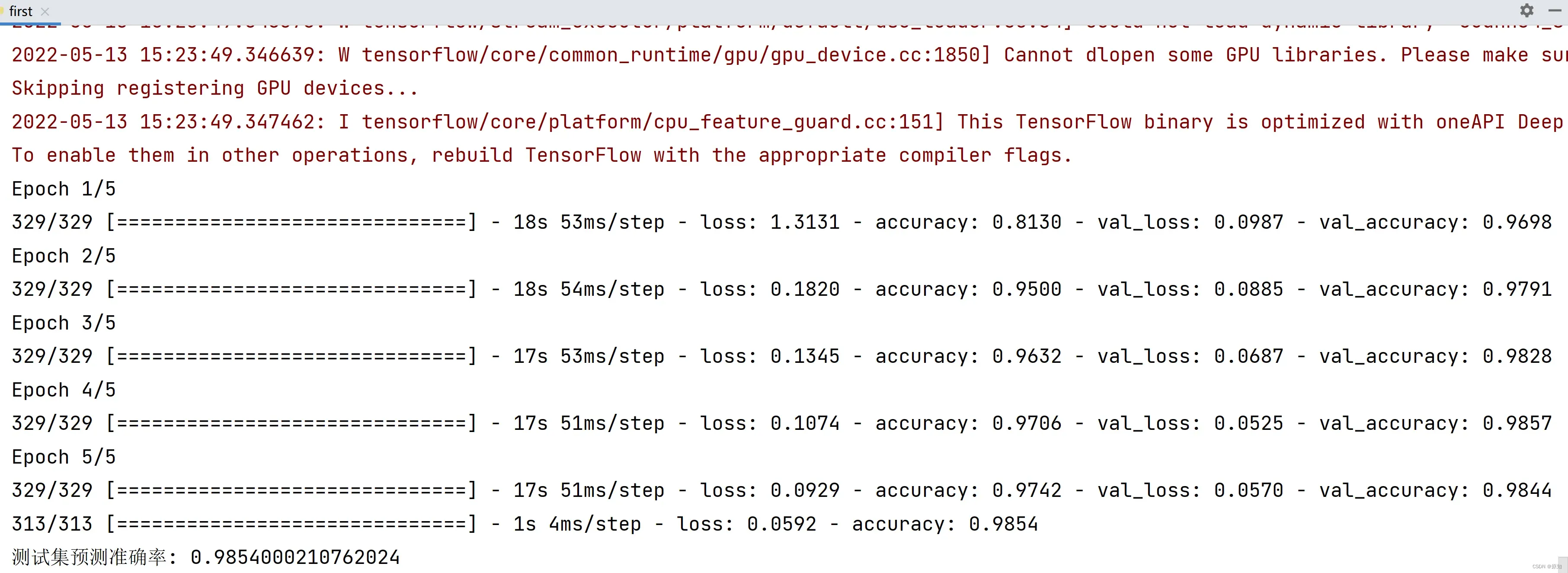
accuracy:表示训练集上的预测准确率
val_accuracy:表示验证集上预测的准确率
注:
1、解释一下为什么要新的格式:
(1)Keras要求图像数据集导入卷积网络模型时为4阶张量,最后一阶代表颜色深度,灰度图像只有一个颜色通道,可以设置为1
(2)在机器学习的分类问题中,标签[0.0.0.0.0.0.0.1.0]表示8.
2、基础知识:
图像格式数据的输入通常是张量流中的四维数组
「(数值、宽度、高度、深度)」
「num_instance:「数据实例数。通常指定为」无」,以适应数据大小的波动
「宽度」:图像的宽度
「高度」:图像的高度
「深度」:图像的深度。彩色图像的深度通常为3(RGB为3个通道)。黑白图像的深度通常为1(只有一个通道)
3、具体张量的定义,看这篇博客:https://blog.csdn.net/yangqinglin193/article/details/114264394
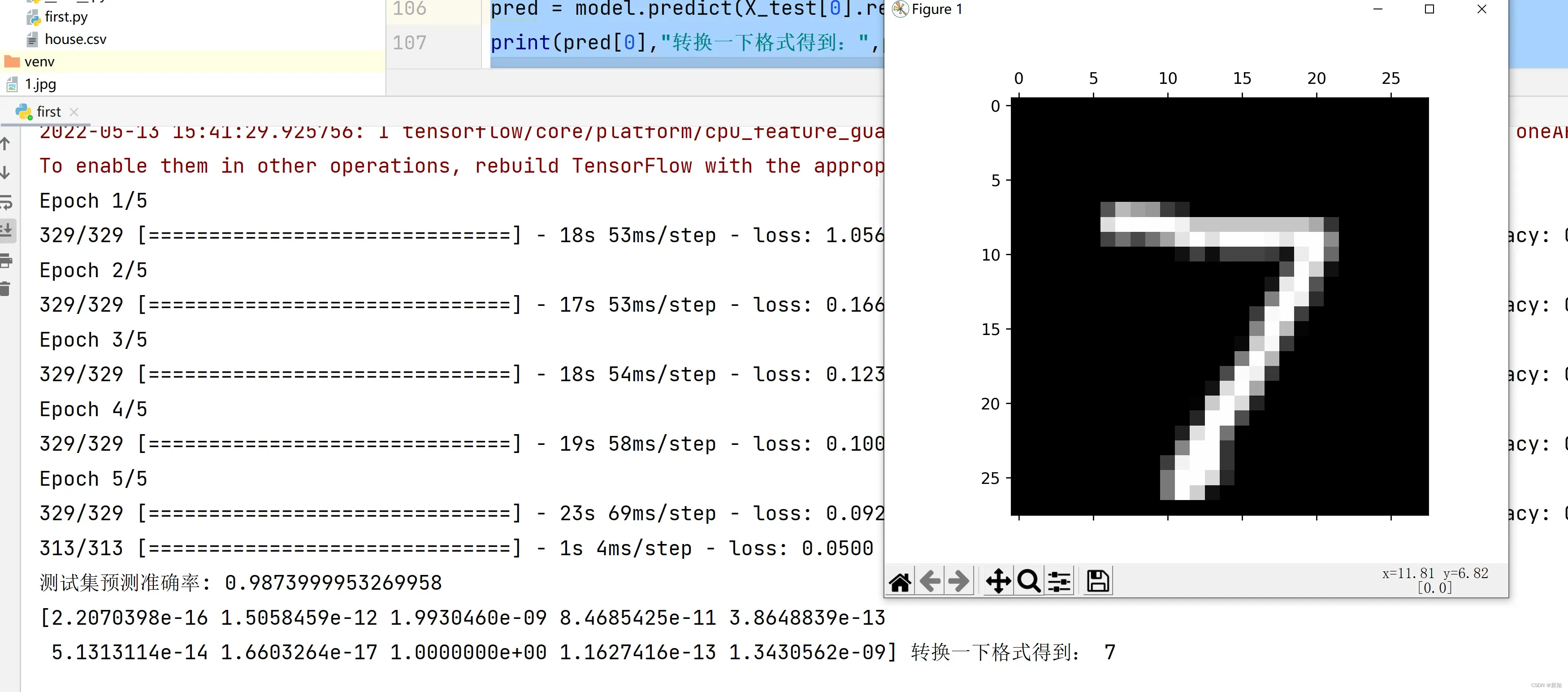
数据集预测:
pred = model.predict(X_test[0].reshape(1, 28, 28, 1)) # 预测测试集第一个数据
print(pred[0],"转换一下格式得到:",pred.argmax()) # 输出数组里的最大索引
import matplotlib.pyplot as plt # 导入绘图工具包,输出图片
img=np.reshape(X_test[0],(28,28))
label = np.argmax(X_train_image [0])
plt.matshow(img, cmap = plt.get_cmap('gray'))
plt.show()
文章出处登录后可见!
已经登录?立即刷新