前言
ASR语音识别任务通常使用开源数据集进行训练,为了补充语音识别数据,通过脚本自动生成一些视频片段进行自动标注,可以有效地减少认为标注的工作量。
一、语音识别任务
通过ASR深度学习模型识别出语音的文字。
二、代码实现
通过程序自动从电影或电视剧中剪辑对应的音频内容,保存本地作为语音识别任务的数据源。
经过剪辑的音频文件可通过音频标注工具进行校验修改。音频标注工具在主页博客可看到。
1.语音定位
依赖环境
pytorch
easyocr
pydub
tqdm
moviepy
使用easyocr作为ocr文字提取模型,该库需要下载中文模型包。
import time
import cv2
import easyocr
import cv2 as cv
import numpy as np
from tqdm import tqdm
thresh = 235 # 设定阈值 进行二值化
temporary_frame = []
reader = easyocr.Reader(["ch_sim", "en"], gpu=True, download_enabled=False) # 用于识别文字
start_flag=False
end_flag=False
start_cnt=0
end_cnt=0
no_text=0
result=[]
def cal_video(img, imgo=None):
'''
计算当前字幕是否相同
'''
return ((img - imgo) ** 2).sum() / img.size * 100
def end(img):
'''
检测字幕是否结束
'''
totle=img.size
img=img==0
img = str(img.tolist())
number = img.count('True')
# 计算当前无字幕区域大小是否占输入区域大小的99%
if number>totle*0.99:
return True
return False
def find_text(path,top,buttom):
'''
寻找电影中的字幕
:param path: 路径
:param top: 字幕上边缘点
:param buttom: 字幕下边缘点
'''
cnt = 0
print('-----',path)
video_file = cv.VideoCapture(path)
video_fps = video_file.get(cv.CAP_PROP_FPS)
total_frames = int(video_file.get(cv.CAP_PROP_FRAME_COUNT))
image_size = (int(video_file.get(cv.CAP_PROP_FRAME_HEIGHT)), int(video_file.get(cv.CAP_PROP_FRAME_WIDTH)))
frames_height, frames_weight = image_size[0], image_size[1]
global start_flag,result,end_flag,end_cnt,start_cnt
for i in tqdm(range(total_frames)):
success, frames = video_file.read()
# print("打开第{}帧,一共{}".format(cnt,total_frames))
if not success:
# 结束
return
frames_cut = frames[:, :, 0] # [(486, 864)]
frames_wh_cut = frames_cut[top: buttom, :]
_, frames_threshold = cv.threshold(frames_wh_cut, thresh, 255, cv.THRESH_BINARY)
temporary_frame.append(frames_threshold)
if cnt > 2:
del temporary_frame[0]
mid_result = cal_video(temporary_frame[1], temporary_frame[0])
# 判断开始
if mid_result > 2:
if not start_flag or result==[]:
# print("程序运行!第{}帧".format(cnt))
result = reader.readtext(frames_wh_cut)
# print(result)
for i in range(len(result) - 1, -1, -1):
if result[i][-1] <= 0.4:
del result[i]
start_flag = True if result !=[] else False
start_cnt=cnt
# 是否结束
if start_flag:
end_flag = end(temporary_frame[1])
# 更新结束帧
end_cnt = cnt+15 if end_flag else end_cnt
if end_flag and start_flag:
if len(result) > 0:
f = open(path[:-4]+'.txt', "a", encoding="utf-8")
f.write(str(start_cnt/int(video_fps)) + "--->" + str(end_cnt/int(video_fps)) + "\n")
for i in result:
if i[1][0] not in ' 1234567890qwertyuiopasdfghjklzxcvbnm':
f.write(str(i[1]))
f.write('\n')
f.close()
start_flag=False
end_flag = False
cnt += 1
音频会读取视频文件,并生成对应文本文件,包含了音频开始时间,结束时间,文本内容。
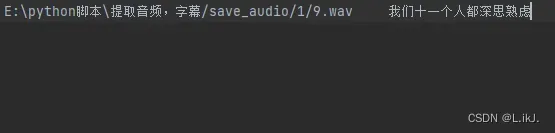
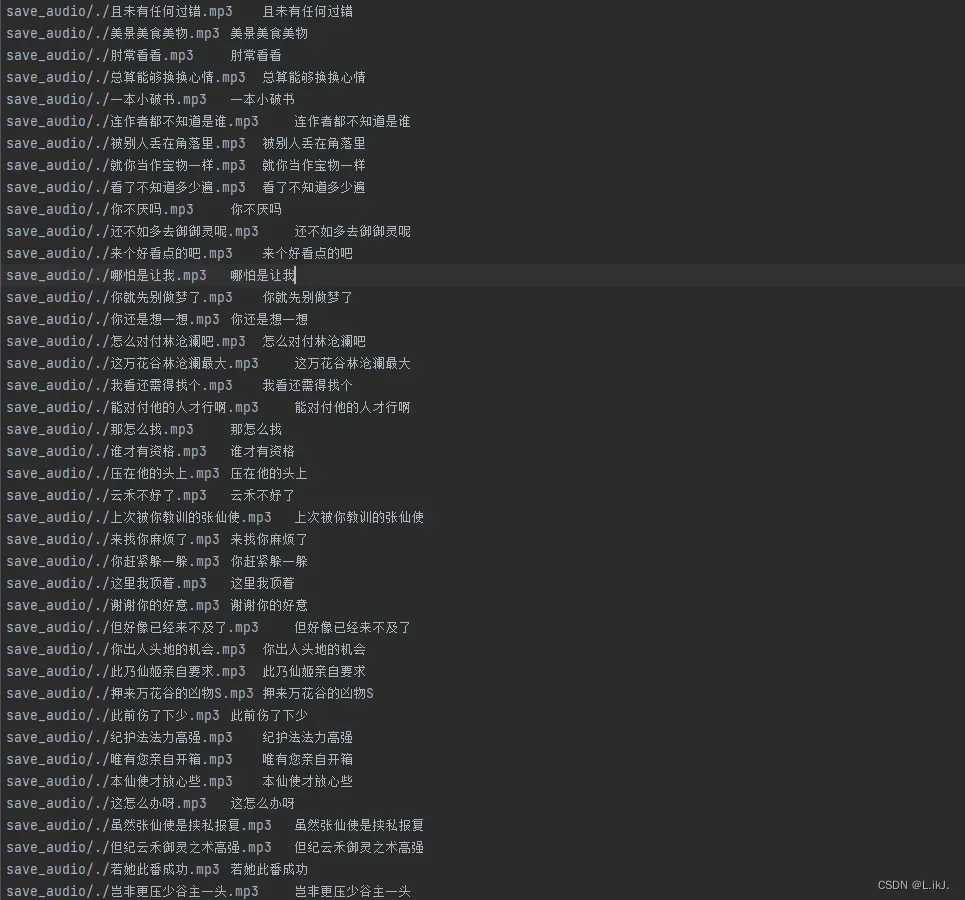
2.根据时间剪辑对应音频
import os
import subprocess
def cut_wav(path):
cnt = 1
print(path)
file_name=path.split('/')[-1]
with open(path, encoding='utf-8') as f:
info_list=f.readlines()
ff=open('dataset.txt','a')
for i in range(0,len(info_list),2):
t1,t2=info_list[i].split('--->')
text=info_list[i+1]
print(text)
if text=='\n':
continue
ff.write('save_audio/{}/{}.mp3\t'.format(path.split('/')[0],text[:-1])+text.replace(' ',''))
# print(t1, t2)
target_path='./save_audio/{}'.format(file_name[:-4])
if not os.path.exists(target_path):
os.mkdir(target_path)
clip_audio(path[:-3]+'mp4', './save_audio/{}/{}.mp3'.format(file_name[:-4],cnt), round(float(t1), 2), round(float(t2), 2))
with open('./save_audio/{}/{}.txt'.format(file_name[:-4],cnt),'w',encoding='utf-8') as f:
f.writelines('{}/save_audio/{}/{}.wav\t{}'.format(os.path.abspath('./'),file_name[:-4],cnt,text))
cnt+=1
print('./save_audio/{}/{}.mp3'.format(file_name[:-4],cnt))
from moviepy.video.io.VideoFileClip import VideoFileClip
from pydub import AudioSegment
def clip_audio(source_file, target_file, start_time, stop_time):
"""
利用pydub进行音频剪切。pydub支持源文件为mp4格式,因此这里的输入可以与视频剪切源文件一致
:paramsource_file:原视频的路径,mp4格式
:paramtarget_file:生成的目标视频路径,mp4格式
:paramstart_time:剪切的起始时间点(第start_time秒)
:paramstop_time:剪切的结束时间点(第stop_time秒)
:return:
"""
validate_file(source_file)
audio = AudioSegment.from_file(source_file, "mp4")
audio = audio[start_time * 1000:stop_time * 1000]
audio_format = target_file[target_file.rindex(".") + 1:]
audio.export(target_file, format=audio_format)
# 转换
try:
# windows
result = 'C:/Program Files/ffmpeg/bin/ffmpeg -i "{}"'.format(
str(target_file)) + ' -f wav -ac 1 -ar 16000 ' + '"{}"'.format(
str(target_file[:-3] + 'wav'))
subprocess.call(result)
except:
# linux
result = '/usr/bin/ffmpeg -i "{}"'.format(
str(target_file)) + ' -f wav -ac 1 -ar 16000 ' + '"{}"'.format(
str(target_file[:-3] + 'wav'))
os.system(result)
# 删除
os.remove(target_file)
def validate_file(source_file):
if not os.path.exists(source_file):
raise FileNotFoundError("没有找到该文件:" + source_file)
经过剪辑的音频会生成对应的视频内容和文本内容。
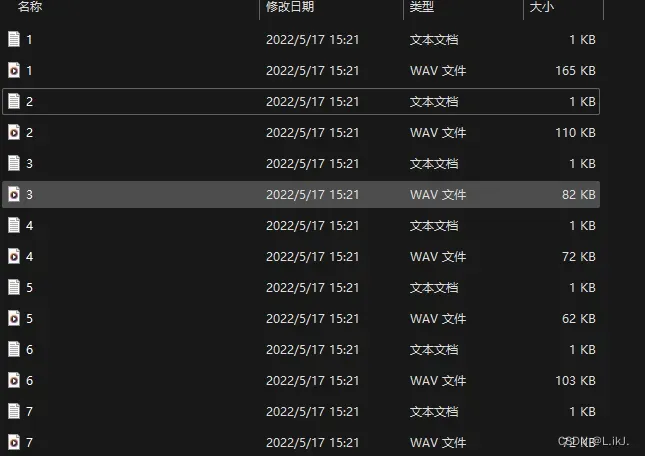
总结
通过脚本自动生成电影中的字幕所对应的音频内容,经过预处理后可直接用于语音识别任务中。
文章出处登录后可见!
已经登录?立即刷新