RAG(Retrieval-Augmented Generation)是一种自然语言处理模型架构,旨在结合检索和生成两个关键的NLP(Natural Language Processing)任务。RAG模型可以应用于诸如问答系统、文本摘要、对话系统等多个领域。在本章的内容中,将详细讲解RAG的基础知识,介绍RAG技术的原理和架构知识,为读者步入后面知识的学习打下基础。
1.1 RAG模型概述
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。RAG是结合检索和生成任务的自然语言处理模型架构,RAG模型通常包括如下两个主要组成部分:
- 信息检索模块:用于从大型文本数据中检索相关的信息;
- 生成模块:用于生成输出文本。这种结合检索和生成的方法旨在提高模型的性能,特别是在涉及特定领域知识或需要引用外部信息的任务中。
1.1.1 RAG的推出背景
使用过ChatGPT、文心一言、科大讯飞等大模型的读者应该对大模型的能力有了一定的了解,但当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要原因如下:
- 知识的局限性:大型语言模型的知识完全源于其训练数据,而这些训练数据主要构建于公开网络数据。对于实时性、非公开或离线的数据,大模型无法获取,导致模型在某些领域缺乏专业知识。
- 幻觉问题:所有AI模型的底层原理基于数学概率,其输出是数值运算。在缺乏特定领域知识或面对不擅长的场景时,大模型有时会产生不准确或不切实际的结果。对于用户来说,区分这种幻觉问题可能是困难的,需要用户自身对特定领域有一定的了解。
- 数据安全性:企业对数据安全性极为重视,不愿意承担将私域数据上传到第三方平台进行训练的风险。这使得通用大型语言模型在数据安全和模型效果方面需要进行权衡。
- 计算资源需求:大型语言模型在推理时需要大量计算资源,可能对一些实时性能要求高的业务应用造成挑战。模型的规模和计算效率成为需要考虑的因素之一。
上面的这些原因强调了在实际业务应用中,通用大型语言模型可能无法直接满足特定业务需求,需要更加灵活和定制化的解决方案。检索增强生成(RAG)等结合检索和生成的模型架构被提出,以弥补上述通用大模型的一些不足,特别是在处理特定领域知识和需要引用外部信息的任务中。
总结起来,RAG的优点如下所示。
- 矢量搜索融合:RAG 通过将矢量搜索功能与生成模型集成,引入了一种新颖的范例。这种融合使得大型语言模型 (LLM) 能够生成更丰富、更具上下文感知的输出。
- 减少幻觉:RAG 显着降低了法学硕士的幻觉倾向,使生成的文本更加基于数据。
- 个人和专业实用程序:从筛选笔记等个人应用程序到更专业的集成,RAG 展示了在提高生产力和内容质量方面的多功能性,同时基于值得信赖的数据源。
1.1.2 RAG的构建与组成
RAG(检索增强生成)结合了检索技术和大型语言模型(LLM)提示,通过向LLM提出问题,RAG从多源数据中检索相关信息,将检索到的信息和问题注入到LLM提示中,最终由LLM生成答案。在2023年,RAG成为基于LLM的系统中最受欢迎的架构,被广泛应用于构建各种产品,涵盖了从基于Web搜索引擎和LLM的问答服务到使用私有数据的聊天应用程序。尽管在2019年,Faiss实现了基于嵌入的向量搜索技术,但是RAG推动了向量搜索领域的发展。例如,Chroma、Weaviate.io和Pinecone等初创公司在开源搜索索引引擎(主要是Faiss和NMSLIB)的基础上,最近增加了输入文本的额外存储和其他工具,推动了这一领域的创新。
在RAG模型的运作过程中主要分为两个关键步骤:语义搜索和生成输出,这个过程旨在从大型知识库中检索相关信息,并在生成阶段利用这些信息来产生有意义的响应。
- 在语义搜索步骤中,追求从知识库中提取与查询最相关的信息片段。在这一过程中,RAG模型利用其信息检索模块,通过向大型文本数据提出问题,寻找与查询相关的内容。这一步骤的关键在于有效地捕捉并提取知识库中的信息,以便在后续生成步骤中产生更加准确和有深度的回应。
- 在生成输出步骤中,RAG模型将从语义搜索中获得的信息注入到生成模块中,用于创造性地构建输出文本。通过将检索到的信息与提出的问题有机地融合,RAG模型能够生成更富有内涵、针对性更强的答案。这种结合检索和生成的方法有效地提高了模型性能,特别是在需要特定领域知识或引用外部信息的任务中。
近年来,基于大型语言模型(LLM)的管道和应用程序的开源库受到广泛关注,其中最著名的开源库是LangChain和LlamaIndex。这两个项目分别在2022年10月和11月创立,通过借鉴ChatGPT的发布,激发了开发者社区的兴趣,并在2023年获得了大量的采用。
然而,尽管这些开源项目取得了显著的进展,但他们的快速发展也带来了一些挑战,其中一个挑战是文档的厚度。由于开发速度之快,LlamaIndex和LangChain的文档已经达到甚至超过2016年的机器学习教科书的厚度。这种现象表明了LLM领域的快速演进,但同时也提醒我们需要更全面系统地理解这些开源项目,而不仅仅是局限于个别技术的教程。因此,本文的目的是借鉴LlamaIndex的实现,系统地介绍关键的高级RAG技术,以促进对这些模型的深入研究。
1.1.3 RAG的实现过程
RAG融合是一种用于(可能)提升RAG应用检索阶段的技术,其 基本实现过程是利用大模型生成多个查询,通过向量搜索检索相关信息,注入到生成模块的 Prompt 中,最终由大模型生成答案。如图1-1所示。
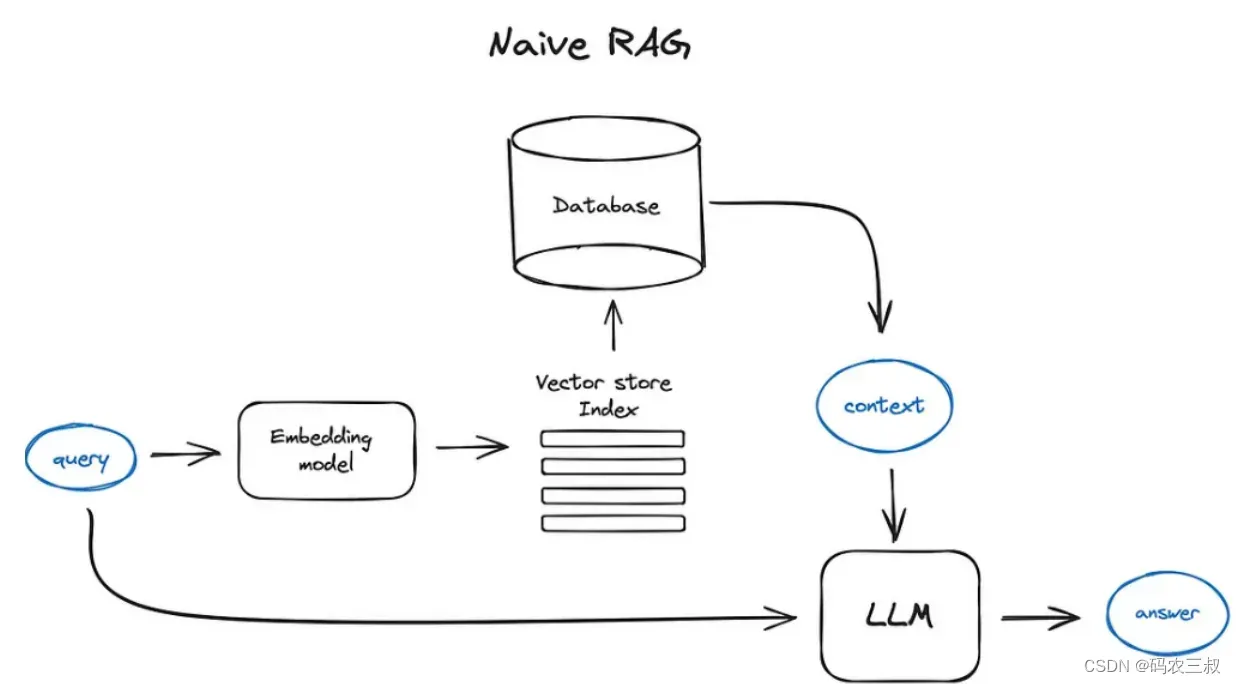
图1-1 RAG实现流程
具体来说,RAG实现过程的主要步骤如下所示。
(1)问题提问:用户通过向大型语言模型(LLM)提出问题,这个问题将作为RAG的输入。
(2)检索技术:RAG使用检索技术从各种数据源中获取与用户问题相关的信息。这可以包括在大型文本数据集中进行关键词匹配、相似度计算或者其他检索方法,以找到与问题相关的内容。
(3)信息注入:RAG将从检索中获取的信息与用户的问题一同注入到LLM的提示中。这样,LLM在生成答案时可以综合考虑用户提问的问题和检索到的外部信息。
(4)LLM生成答案:带有注入信息的LLM提示被用于生成最终的答案。LLM会利用其深度学习架构,结合用户提问和检索到的信息,生成相应的自然语言文本作为答案。
(5)答案返回:RAG将LLM生成的答案返回给用户,完成整个问答过程。在这个步骤中,RAG模型可以仅负责检索和信息注入,而最终的答案生成和输出可以由LLM来完成。然而,在某些实现中,RAG模型可能会负责将LLM生成的答案传递给用户。这种情况下,RAG模型充当了一个中介的角色,它不仅执行检索任务,还负责将生成的答案传递给最终的用户。
实现RAG的关键在于有效整合检索技术和大型语言模型,以使得模型能够利用外部信息,提高对特定问题的准确性和适应性。这个结合检索和生成的方法使RAG在处理特定领域的问题时更为灵活和有针对性。在实际中,可以根据具体任务和需求调整RAG的实现细节。
未完待续
版权声明:本文为博主作者:码农三叔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/asd343442/article/details/136009330