
摘要
知识提炼已经成功地应用于各种任务。当前的蒸馏算法通常通过模仿老师的输出来提高学生的表现。本文表明,教师也可以通过指导学生的特征恢复来提高学生的表征能力。从这个角度出发,我们提出了掩蔽生成蒸馏(MGD),它很简单:我们掩蔽学生特征的随机像素,通过一个简单的块,迫使它生成老师的全部特征。MGD是一种真正通用的基于特征的提取方法,可用于各种任务,包括图像分类、对象检测、语义分割和实例分割。我们用大量的数据集对不同的模型进行了实验,结果表明所有的学生都取得了很大的进步。值得注意的是,我们将ResNet-18的ImageNet top-1精确度从69.90%提高到71.69%,将具有ResNet-50主干的RetinaNet的边界框图从37.4提高到41.0,将基于ResNet-50的SOLO的遮罩图从33.1提高到36.2,并将基于ResNet-18的DeepLabV3从7320万提高到7602万。
我们的代码可以在https://github.com/yzd-v/MGD.找到。
1.介绍
…
以前的基于特征的提取方法通常让学生尽可能地模仿老师的输出,因为老师的特征具有更强的表示能力。但是,我们认为没有必要直接模仿老师来提高学生特征的表征能力。用于提取的特征一般是通过深度网络的高阶语义信息。特征像素在一定程度上已经包含了相邻像素的信息。所以,如果能通过简单的分块,用部分像素还原老师的全部特征,这些用过的像素的表现力也能得到提升。从这个角度出发,我们提出了一种简单有效的基于特征的提取方法——掩蔽生成提取法。如图2所示,我们首先屏蔽学生特征的随机像素,然后通过一个简单的块用屏蔽的特征生成教师的完整特征。由于在每次迭代中使用随机像素,因此在整个训练过程中将使用所有像素,这意味着该特征将更加鲁棒,并且其表示能力将得到提高。在我们的方法中,老师只是作为学生恢复特征的指导,并不要求学生直接模仿。

图一。FPN输出的第一层要素的可视化。老师:RetinaNet-ResNeXt101。学生:RetinaNet-ResNet50。FGD[36]是一种检测器的提取方法,它迫使学生模仿老师的特征。
为了证实我们的假设,即不直接模仿教师的掩蔽特征生成可以提高学生的特征表征能力,我们从学生和教师的脖子[21]的第一层做了特征的可视化。如图1所示,学生和教师的特征非常不同。与教师相比,学生特征的背景具有更高的响应。老师的图也明显高于学生,41.0对37.4。在用最先进的蒸馏技术FGD蒸馏后,这就迫使学生的特征专注于模仿老师的特征,学生的特征变得更像老师,学生的mAP也大幅提升到了40.7。而经过MGD训练后,学生和教师的特征仍有显著差异,但学生对背景的反应却大大降低。我们也很惊讶这个学生的成绩超过FGD,甚至达到了和老师一样的mAP。这也说明用MGD训练可以提高学生特征的表征能力。此外,我们还在图像分类和密集预测任务上做了大量的实验。实验结果表明,MGD可以在图像分类、目标检测、语义分割和实例分割等方面带来显著的改进。MGD还可以与其他基于logit或基于head的蒸馏方法结合使用,以获得更大的性能增益。综上所述,本文的贡献在于:
1.我们提出了一种新的基于特征的知识提取方法,让学生用教师的屏蔽特征来生成教师的特征,而不是直接模仿它。
2.我们提出了一种新的基于特征的知识提取方法——掩蔽生成提取法,该方法简单易用,只需要两个超参数。
3.通过在不同数据集上的大量实验,我们验证了我们的方法在不同模型上的有效性。对于图像分类和密集预测任务,学生通过MGD获得了显著的改进。
2.相关工作
2.1 图像分类的知识蒸馏
2.2密集预测的知识蒸馏
分类和密集预测有很大区别。许多用于分类的蒸馏工作在密集预测上失败了。理论上,基于特征的提取方法应该有助于分类和密集预测任务,这也是我们的方法的目标。
用于物体检测的知识蒸馏。陈等人[1]首先计算了探测器颈部和头部的蒸馏损失。由于前景和背景之间的极端不平衡,提取目标的关键是从哪里提取。为了避免从背景中引入噪声,FGFI[32]利用细粒度掩模提取物体附近的区域。然而,failure[13]指出,前景和背景的语义信息对提取都很重要。GID[10]选择学生和教师表现不同的领域进行提炼。FKD[38]使用教师和学生注意力地图的总和来引导学生关注可变区域。FGD[36]提出了焦点提炼和全局提炼,焦点提炼迫使学生学习老师的关键部分,而全局提炼则弥补缺失的全局信息。
语义分割的知识蒸馏。刘等人[24]提出了成对和整体的升华,加强了学生和教师的输出之间的成对和高阶一致性。何等人[16]将教师网络的输出重新解释为一个重新表示的潜在域,并从教师网络中获取长期依赖性。CWD[30]最小化了概率图之间的kull back-lei bler(KL)散度,该概率图通过归一化每个通道的激活图来计算,并且可以应用于检测和分割。
3.方法
对于不同的任务,模型的架构有很大的不同。此外,大多数蒸馏方法是为特定任务设计的。然而,基于特征的提取可以应用于分类和密集预测。特征提取的基本方法可以表述为:
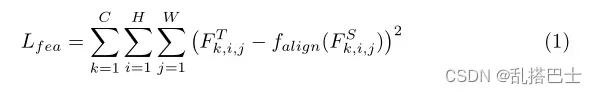
其中FT和FS分别表示教师和学生的特征,而falign是将学生的特征FS与教师的特征FT对齐的适应层。C,H,W表示特征图的大小。
这种方法有助于学生直接模仿老师的特征。然而,我们提出掩蔽生成蒸馏(MGD ),其目的在于强迫学生生成教师的特征,而不是模仿它,从而为学生带来分类和密集预测的显著改进,MGD的架构如图2所示,我们将在本节中专门介绍。
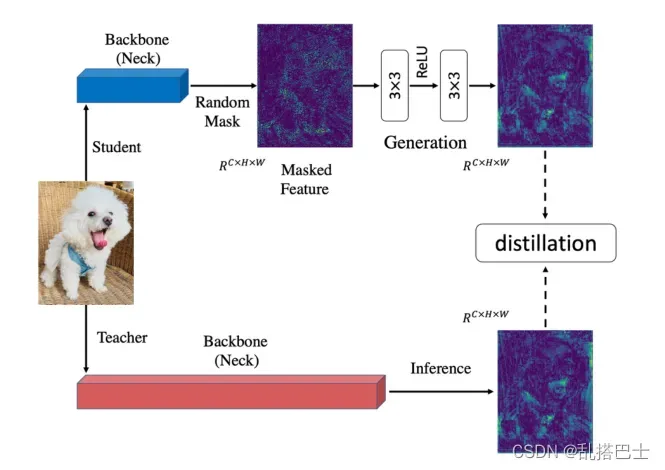
图二。一个MGD的例子,掩盖的生成蒸馏。我们首先随机掩盖学生的特征。然后,我们使用投影层来迫使学生生成带有蒙版特征的教师特征。
3.1生成具有掩膜的特征
对于基于CNN的模型,更深层的特征对于原始输入图像具有更大的感受域和更好的表示。换句话说,特征图像素在一定程度上已经包含了相邻像素的信息。因此,我们可以使用部分像素来恢复完整的特征图。我们的方法旨在通过学生的掩蔽特征生成教师的特征,这可以帮助学生获得更好的表征。
我们用Tl ∈ RC×H×W和Sl∈ RC×H×W(l = 1,…,L)分别表示老师和学生的第L个特征图。首先,我们设置第l个随机掩码来覆盖学生的第l个特征,这可以表述为:
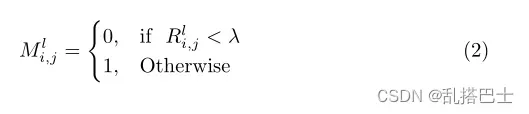
其中Rl i,j是(0,1)中的随机数,I,j分别是特征图的水平和垂直坐标。λ是一个表示屏蔽率的超参数。第l个特征图被第l个随机掩码覆盖。
然后,我们使用相应的遮罩来覆盖学生的特征图,并尝试使用左侧像素来生成教师的特征图,其公式如下:
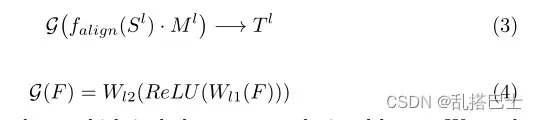
G表示投影层,它包括两个卷积层:Wl1和Wl2,一个激活层ReLU。在本文中,我们采用1×1卷积层作为适配层,3×3卷积层作为投影层Wl1和Wl2。根据这种方法,我们设计了MGD的蒸馏损失Ldis:
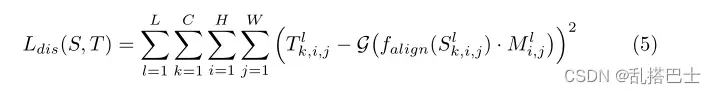
其中L是蒸馏层的总和,C、H、W表示特征图的形状。s和T分别表示学生和教师的特征。
3.2总体loss
使用MGD的建议蒸馏损失Ldis,我们用以下总损失训练所有模型:
其中,Loriginal是所有任务中模型的原始损失,α是平衡损失的超参数。
MGD是一种非常简单有效的训练学生的方法,可以很容易地应用于各种任务。我们的方法的过程总结在算法1中。

4.主要的实验
MGD是一种基于特征的蒸馏,可以很容易地应用于不同任务的不同模型。在本文中,我们进行了各种任务的实验,包括分类,对象检测,语义分割和实例分割。我们用不同的模型和数据集对不同的任务进行了实验,所有的模型都通过MGD实现了很好的改进。
…
5.分析
5.1 使用MGD得到更好的表现
MGD强制学生用其被屏蔽的特征生成老师的完整特征图,而不是直接模仿。这有助于学生更好地呈现输入图像。在这一小节中,我们通过学生自学来研究这一点。我们先把ResNet-18直接训练成老师和基准线。然后我们用训练过的ResNet-18用MGD进行自蒸馏。为了比较,我们也通过强迫学生直接模仿老师来提取学生。模仿的蒸馏损失是学生的特征地图和教师的特征图之间的L2距离的平方。
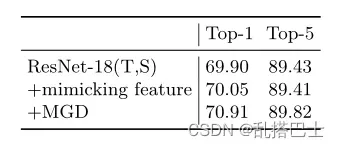
如表5所示,即使教师本身就是学生,学生也可以通过MGD获得1.01的准确度提高。相比之下,当强迫学生直接模仿老师的特征图时,改善是非常有限的。比较表明,学生的特征图比教师的特征图提取后具有更好的代表性。
此外,我们可视化了使用MGD和模仿老师进行蒸馏的训练损失曲线,如图3所示。图中的差异表示学生和老师的最后特征图之间的L2距离的平方,这也是模仿老师的蒸馏损失。如图所示,在直接模仿老师的过程中,差异不断减小,最终学生获得了与老师相似的特征。然而,这种方法的改进很小。相比之下,使用MGD训练后,差异变得更大。虽然学生得到的特征与老师不同,但它的准确率更高,也说明学生的特征获得了更强的表征能力。
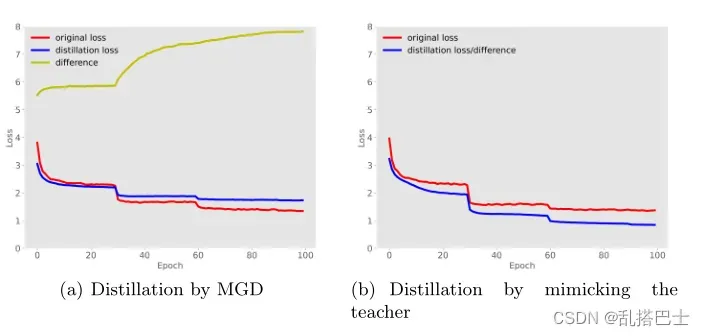
图3。提取ResNet-18的训练损失曲线。差异意味着学生和教师的最后特征地图之间的L2距离的平方。也是模仿老师的蒸馏损失。
5.3通过掩膜随机通道进行蒸馏
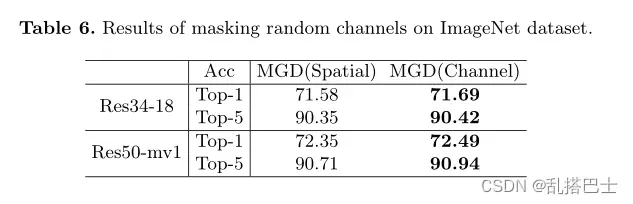
对于图像分类,模型通常利用池层来降低特征图的空间维度。这一层使模型对通道比对空间像素更敏感。因此,在这一小节中,我们尝试通过掩蔽随机通道而不是空间像素来应用MGD进行分类。实验采用掩蔽比β = 0.15,超参数α= 7×105。如表6所示,学生可以通过掩蔽随机通道而不是空间通道来获得更好的图像分类性能。学生版Res-18和MobileNet分别获得0.13和0.14的顶级精度增益。
表5。Rse18-18在ImageNet上的蒸馏结果。我们直接训练ResNet-18作为老师和学生的基线。t和S分别表示老师和学生。
5.3使用不同教师进行蒸馏
…
5.4生成块
5.5在不同阶段进行蒸馏
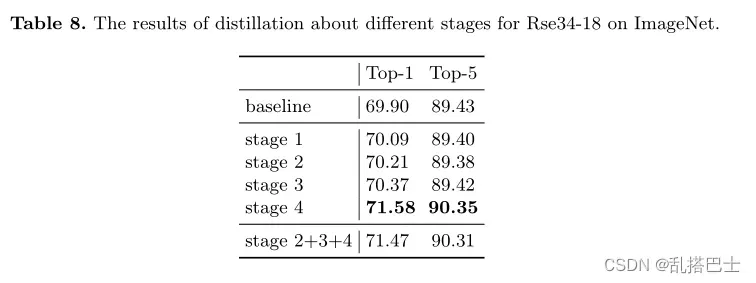
我们的方法也可以应用于模型的其他阶段。在这一小节中,我们通过使用ResNet-34在ImageNet上提取ResNet18来探索不同阶段的提取。我们计算了教师层和学生层的蒸馏损失。如表8所示,提取较浅的层对学生也有帮助,但非常有限。而提取包含更多语义信息的更深层次对学生更有益。此外,来自早期阶段的特征不直接用于分类。因此,将这样的特征与最后阶段的特征一起提取可能会损害学生的准确性。
5.6超参数的敏感性研究
…
6.结论
在本文中,我们提出了一种新的知识提取方法,这种方法迫使学生用教师的屏蔽特征来生成教师的特征,而不是直接模仿它。基于这种方法,我们提出了一种新的知识提取方法——掩蔽生成提取法。学生可以通过MGD获得更强的表征能力。此外,我们的方法只是基于特征图,因此MGD可以很容易地应用于各种任务,如图像分类,对象检测,语义分割和实例分割。在不同数据集上对不同模型的大量实验证明了我们的方法是简单有效的。
文章出处登录后可见!