原文标题 :Datasets to Train, Validate, and Evaluate Machine Translation
用于训练、验证和评估机器翻译的数据集
选择、检查和拆分

对于大多数自然语言处理 (NLP) 任务,重要的一步是选择数据集来训练、验证和评估系统。机器翻译也不例外,但具有任务的多语言性所固有的一些特殊性。
在这篇文章中,我将解释如何选择、检查和拆分数据集来构建机器翻译系统。我通过示例展示了机器翻译数据集最重要的属性是什么,以及如何根据机器翻译系统的目标在数据质量和数量之间进行权衡。
训练、验证和评估
要构建机器翻译系统,我们需要尽可能多的数据:
- 训练:必须训练机器翻译系统来学习如何翻译。如果我们计划使用神经模型,那么就数据和计算资源而言,这一步是迄今为止成本最高的一步。
- 验证:可以在训练期间使用验证数据集来监控正在训练的模型的性能。例如,如果一段时间后性能没有提高,我们可以决定提前停止训练。然后,如果我们在不同的训练步骤中保存了模型,我们可以选择在验证数据上表现最好的模型,并使用该模型进行评估。
- 评估:此步骤会自动产生我们所选模型在数据集上的性能,该数据集尽可能接近我们的系统在部署后将翻译的文本。如果性能令人满意,那么我们可以部署我们的模型。否则,我们将不得不使用不同的超参数或训练数据重新训练模型。
所有这些数据集都是源语言和目标语言的平行语料库,最好是在目标域中。
一个句子中有很多关键字。让我们一一解释。
- 源语言:这是将由我们的机器翻译系统翻译的文本的语言。
- 目标语言:这是机器翻译系统生成的翻译语言。
- 目标域:这个概念定义起来比较复杂。假设用于构建我们系统的数据看起来应该尽可能接近系统在部署后将要翻译的数据:例如相同的风格、流派和主题。如果我们希望我们的系统翻译推文,那么在推文上进行训练要比在科学摘要上进行训练要好得多。这可能看起来很明显,但通常在目标域中找到大型数据集具有挑战性,因此我们必须对其进行近似。
- 平行语料库:这通常以源语言的句子或片段的形式与目标语言的翻译配对。我们使用并行数据来教系统如何翻译。这类数据还有许多其他名称:平行数据、双语语料库、双文本等。“平行数据”可能是最常见的一种。
例如,以下数据集是并行的:

Quality
为了得到最好的机器翻译系统,我们需要一个大型的平行语料库来训练系统。但我们不应该为了数量而牺牲质量。
根据我们谈论的是训练数据还是验证/评估数据,所用数据的质量会产生不同的影响。
但首先,让我们定义从头开始构建系统的高质量并行数据最重要的特征是什么。
Correct
平行数据中的翻译应该是正确和自然的。理想情况下,这意味着翻译应该由专业翻译人员从头开始制作(即,不进行后期编辑)并进行独立检查。平行语料库通常是由非专业翻译人员通过众包产生的。数据也可以简单地从网络上爬取并自动配对,这绝对不是完美的,特别是对于只有少量数据可用的域和语言对。尽管此类数据集的质量远非最佳,但当它们是给定语言对的唯一可用资源时,我们可能别无选择,只能使用它们。
Aligned
并行数据中的段或文档应该正确对齐。如果段没有正确配对,系统将在训练时学习错误的翻译。
Original
并行数据的源端不应是另一种语言的翻译。要完全理解这一点可能有点复杂。我们希望我们的系统学习如何翻译源语言的文本。但是,如果在训练时,我们向我们的系统提供原本不是源语言的文本,即已经是另一种源语言的翻译文本,那么它会学习如何比原始文本更好地翻译翻译。我将在下面详细说明为什么这很重要。
In-domain
数据应该在目标域中。这是有争议的,适合理想情况。我们可以在域外数据集上训练一个非常好的系统,然后在目标域中的较小数据集上对其进行微调。
Raw
数据应该接近原始数据。使用已经预处理过的数据集通常不是一个好主意。预处理是指任何改变原始文本的过程。它可以是标记化、真实大小写、标点符号规范化等。通常,所有这些预处理步骤都未指定,结果是我们无法在部署后系统实际翻译的文本上准确地重现它们。定义我们自己的预处理步骤更安全,有时甚至更快。
要大致了解数据集的质量,我们应该始终知道数据来自何处以及如何创建。我会在下面写更多关于这个的内容。
在训练时,机器翻译系统将学习并行数据的属性。神经模型对噪声相当稳健,但如果我们的训练数据噪声很大,即未对齐或有很多翻译错误,系统将学习生成有错误的翻译。
在验证/评估时,所用并行数据的质量更为关键。如果我们的数据集质量很差,评估步骤只会告诉我们我们的系统在翻译质量方面有多好。换句话说,这将是一个无用的评估,但这可能会说服我们部署一个训练有素的机器翻译系统。
Quantity
除了质量,所用数据的数量也很关键。
“数量”通常是指平行语料库中平行片段的数量。我将在这里使用这个定义。
对于训练,使用尽可能多的数据是一个很好的经验法则,前提是数据具有合理的质量。我将训练场景分为 3 类:
- 低资源:训练数据包含少于 100,000 个平行片段(或所谓的句子)
- 中等资源:训练数据包含 100,000 到 1,000,000 个平行段
- 高资源:训练数据包含超过 1,000,000 个并行段
对于验证和评估,使用大量数据似乎是对我们的模型进行准确评估的正确选择,但通常我们实际上更喜欢使用更多数据进行训练,而不是用于验证和评估。
如果您查看研究和开发中的最佳实践,您会发现机器翻译的验证和评估数据集通常包含 1,000 到 3,000 个并行段。请记住,与训练数据集相比,这些数据集的质量比数量重要得多。我们希望评估数据集能够完美翻译,并尽可能接近我们的系统将翻译的文本。
Monolingual data
与我上面描述的平行数据相反,单语数据是一种语言的文本。它可以是源语言或目标语言。
由于此数据是单语的,因此比平行数据更容易大量收集。
它通常用于生成合成并行数据,然后用于扩充训练并行数据。
生成合成数据的策略有很多,例如反向翻译和正向翻译。如果处理不当,它们可能是非常复杂的技术,会对训练产生负面影响。
我将在另一篇博文中详细讨论它们。敬请关注!
Data leakage prevention
如果您熟悉机器学习,您可能已经知道什么是数据泄漏。
我们希望训练数据尽可能接近验证和评估数据,但没有任何重叠。
如果有重叠,我们就会谈论数据泄漏。
这意味着我们的系统部分接受了也用于验证/评估的数据训练。这是一个关键问题,因为它人为地改进了验证/评估所获得的结果。该系统确实特别擅长翻译其验证/评估数据,因为它在训练时看到了它,而一旦投入生产,系统可能会接触到看不见的文本进行翻译。
防止数据泄漏比听起来要困难得多,而且使事情变得更加复杂的是许多不同级别的数据泄漏。
数据泄漏最明显的情况是评估数据中的成对片段或文档也在训练数据中。这些细分市场应该被排除在外。
另一种形式的数据泄漏是训练和评估数据来自相同的文档。例如,打乱数据集片段的顺序,然后选择前 95% 用于训练,最后 5% 用于验证/评估可能会导致数据泄漏。在这种情况下,我们可能会在训练和验证/评估数据中使用最初来自相同文档的成对片段,这些片段可能由同一位翻译人员创建。也有可能训练数据中的片段被直接用作上下文来创建验证/评估数据中片段的翻译。因此,人为地验证/评估数据变得更容易翻译。
为防止数据泄露,始终了解数据的来源、数据的生成方式以及如何拆分为训练/验证/评估数据集。
关于翻译的一句话
平行语料库有两个方面。理想情况下,源端是由母语为源语言的人编写的原始文本,而目标端是由目标语言为母语的人制作的翻译。
目标端不是原文:它是翻译。翻译可能有错误。研究还表明,与原文相比,译文在词汇上的多样性较低,在句法上更为简单。这些翻译工件定义了“translationese”。
为什么它在机器翻译中很重要?
假设您有一个平行语料库,原始来源为西班牙语,翻译为英语。这非常适合西班牙语到英语的机器翻译系统。
但是如果你想要一个英语到西班牙语的系统,你可能会想交换平行语料库的两边:原文在目标方,翻译在源方。
然后,您的系统将学习翻译……翻译!由于翻译比原始文本更容易翻译,因此神经网络的学习任务要简单得多。但是这样一来,机器翻译系统在翻译用户输入的原文时就会表现不佳。
底线是:检查数据的来源,至少确保源端没有翻译。
请注意,有时这种情况是不可避免的,尤其是在处理低资源语言时。
平行语料库的来源
幸运的是,有许多不同领域和语言的在线平行语料库。
我主要使用以下网站来获取我需要的东西:
- OPUS:这可能是最广泛的平行语料库来源。有数十种语料库可用于 300 多种语言。它们可以纯文本(2 个文件:1 个用于源语言,1 个用于目标语言)或 TMX 格式下载,这是一种翻译行业常用的 XML 格式。对于每个语料库,还给出了大小和长度(以段和标记的数量表示)。[0]
- Dataset from Hugging Face:这个不是专门针对机器翻译的资源,但是如果你选择“translation”标签,你会发现那里有很多平行语料库。 OPUS 和 Dataset 之间的交集很大,但是你会发现一些 OPUS 上没有的平行语料库。[0]
这是迄今为止最大的两个平行语料库来源。如果您认识其他人,请在评论中注明。
请注意,您在那里发现的大多数平行语料库都可用于研究和学术目的,但不能用于商业目的。 OPUS 不显示每个数据集的许可证。如果你需要知道它,你将不得不直接检查数据集的原始来源或联系创建它的人。
Examples
现在让我们更实际地操作一些数据集。我创建了两个需要并行数据的任务:
- 任务 1:将西班牙语翻译成英语的通用机器翻译系统 (Es→En)
- 任务 2:将 COVID-19 相关内容从斯瓦希里语翻译成英语的专用机器翻译系统(Sw→En)
我们将首先关注任务 1。
我们可以开始在 OPUS 上搜索,看看是否有这个任务的平行语料库。
幸运的是,Es→En 是一项高资源任务。在各个领域都有大量的平行语料库。例如,从 OPUS 我们可以得到:
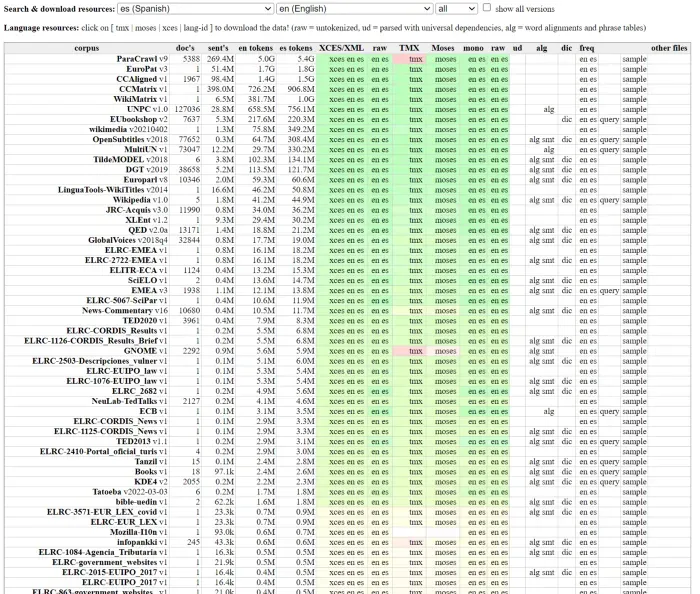
第一个“ParaCrawl v9”是最大的一个。它是自动创建的,但足以训练机器翻译系统。我们应该始终检查许可证以确保我们可以将它用于我们的目标应用程序。正如我上面提到的,OPUS 不提供许可证信息,但一旦您单击它,它就会提供数据集的来源。许可证信息,我们要查看数据的原始来源:https://www.paracrawl.eu/。该语料库是在 CC0 许可下提供的。允许学术和商业用途。[0][1]
这是一个包含 264M 对片段的庞大语料库。这足以将其拆分为训练/验证/评估数据集。我会像这样拆分数据以避免数据泄漏:
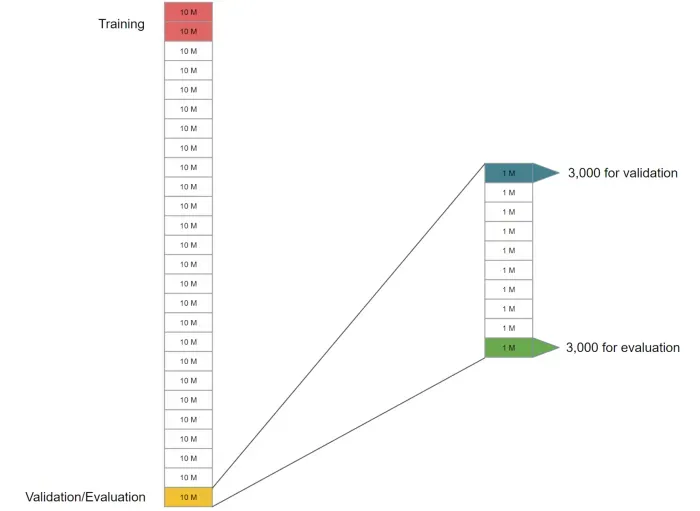
由于这是很多段,我们可以将数据拆分为连续的 10M 段块。我会提取一个块,例如最后一个块,然后将其重新拆分为 1M 的较小的连续块。最后,我将从第一个较小的块中随机提取 3,000 个片段进行验证,并从最后一个较小的块中随机提取另外 3,000 个片段进行评估。
训练、验证和评估数据集之间有足够的距离。这是一种非常简单的方法,但远非最佳。如果语料库中的片段已经打乱,它不能防止数据泄漏。
还有其他方法,我不会在这里讨论,以更好地保证没有数据泄漏,同时为每个数据集提取最有用的段对。
对于训练,您可以从 10M 段的前 2 个块开始。如果您对翻译质量不满意,您可以在训练数据中添加更多块。
如果翻译质量没有太大提高,则意味着您可能不需要使用剩余的 200M+ 段对。
任务 2 更具挑战性。
我们想翻译斯瓦希里语。众所周知,非洲语言资源匮乏。此外,我们针对的是一个相对较新的领域 COVID-19,因此我们可以预期可用于此任务的数据非常小。
正如预期的那样,在 OPUS 上可用的数据集要少得多:
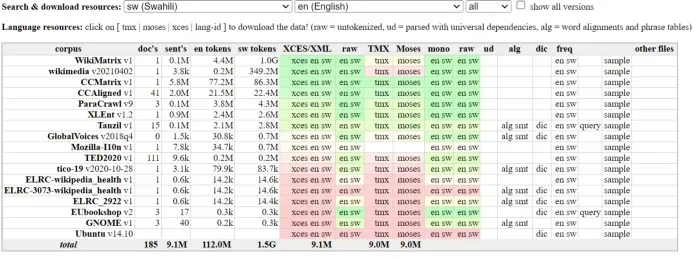
这里的一个好处是 Paracrawl 也可用于 Sw→En,但它的 100,000 段对相当小。然而,这是拥有 CC0 许可证的最大资源之一。我会用它来训练,然后尝试添加其他数据源(例如 CCMatrix 或 CCAligned)来观察性能如何提高。
但是如何评估专门用于翻译 COVID-19 内容的机器翻译系统呢?
在 COVID-19 爆发后,研究界努力制作多种语言的翻译资源。 TICO-19 语料库就是其中之一,并提供了 CC0 许可证。它在 OPUS 上可用。它很小,但提供斯瓦希里语和英语的 3,100 个片段的翻译。这足以制作验证/评估数据集。在这里,我将取 1,000 个用于验证,其余部分用于评估。然后,您将了解在 Paracrawl 上训练的系统在翻译 COVID-19 内容时的表现。[0]
请注意,我没有谈论这两个任务的翻译。 Paracrawl 的来源很可能有非原创的西班牙语和斯瓦希里语。 TICO-19 语料库是从英语创建的。斯瓦希里语方面是非原创的。换句话说,我们无法避免这两个任务的翻译。
Conclusion
在这篇文章中,我描述了如何选择和拆分您的数据集来制作您自己的机器翻译系统。
总而言之,我想说最重要的一点是找到质量和数量之间的最佳平衡点,尤其是当你的目标是低资源语言时。此外,非常了解您的数据集也很重要。如果任其发展,您可能会获得一个完全偏离目标且存在偏见和不公平的系统。
在下一篇文章中,我将向您展示如何预处理这些数据集以改进它们并促进机器翻译的训练。
文章出处登录后可见!