源码获取:https://gitee.com/fgy120/DETR
首先对DETR做个简单介绍

上图即为DETR的流程pipeline,相比以前的RCNN系列、YOLO系列等,最特别的在于加入了Transformer。
目录
main函数(一)参数设置
直接看源码,从train.py的主函数开始。
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)#以output_dir创建Path对象并执行mkdir创建文件夹操作
main(args)首先是常规的参数解析操作,利用的argparse库,主要通过解析命令行输入的参数来设置模型训练的超参数或其他设置。第一步创建解析对象parser,运行parser.parse_args方法得到解析后的各个参数args,默认为解析运行代码的命令行。如果其中包含output_dir参数且output_dir不存在,利用Pathlib中的Path库的mkdir方法创建output_dir的路径文件夹。
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
接着进入main()函数
def main(args):
utils.init_distributed_mode(args)#分布式训练初始化,关闭
print("git:\n {}\n".format(utils.get_sha()))#获得git 状态
if args.frozen_weights is not None:
assert args.masks, "Frozen training is meant for segmentation only"
#冻结训练只使用于分割
print(args)
device = torch.device(args.device)#选择cuda或者cpu,tensor分配到的设备
# fix the seed for reproducibility相同的随机种子seed将模型在初始化过程中所用到的“随机数”全部固定下来,以保证每次重新训练模型需要初始化模型参数的时候能够得到相同的初始化参数,从而达到稳定复现训练结果的目的
seed = args.seed + utils.get_rank()#utils.get_rank()当分布式训练时,需要多个seed
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)utils.init_distributed_mode(args):判断是否进行分布式训练,根据你的电脑的环境配置中是否有相关配置来判断或设置,一般单卡单机的话都是执行到else语句就return了。可选择跳过看代码。
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
#os.environ: 获取环境变量作为字典,例:通过os.environ.get(“HOME”),就可以获取环境变量HOME的值
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
torch.distributed.barrier()
setup_for_distributed(args.rank == 0)utils.get_sha():通过命令行获得git 的commitID和git status以及所在的branch。
#获得git 状态
def get_sha():
cwd = os.path.dirname(os.path.abspath(__file__))
#os.path.dirname去掉文件名返回目录
def _run(command):
return subprocess.check_output(command, cwd=cwd).decode('ascii').strip()
sha = 'N/A'
diff = "clean"
branch = 'N/A'
try:
sha = _run(['git', 'rev-parse', 'HEAD'])
#在命令行中cmd路径下输入git rev-parse HEAD获得git commit id
#subprocess模块允许我们启动一个新线程,并连接到它们的输入输出error通道,从而获取返回值
subprocess.check_output(['git', 'diff'], cwd=cwd)
diff = _run(['git', 'diff-index', 'HEAD'])
diff = "has uncommited changes" if diff else "clean"
branch = _run(['git', 'rev-parse', '--abbrev-ref', 'HEAD'])
except Exception:
pass
message = f"sha: {sha}, status: {diff}, branch: {branch}"
return messagesubprocess.check_output(command, cwd=cwd) subprocess库的check_output方法通过在cwd打开cmd,然后输入commend,并返回cmd的输出
device = torch.device(args.device)#选择cuda或者cpu,通过解析得到device的参数来决定tensor分配到的设备是GPU还是CPU
seed = args.seed + utils.get_rank() #utils.get_rank()当分布式训练时,需要多个seed torch.manual_seed(seed) np.random.seed(seed) random.seed(seed) seed会决定上面三种取随机数方法的值,相同的随机种子seed将模型在初始化过程中所用到的“随机数”全部固定下来,即每次初始化都是一样的,以保证每次重新训练模型需要初始化模型参数的时候能够得到相同的初始化参数,从而达到稳定复现训练结果的目的。
main函数(二)搭建模型
model, criterion, postprocessors = build_model(args)#构建model
model.to(device)
model_without_ddp = model
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
model_without_ddp = model.module
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print('number of params:', n_parameters)model, criterion, postprocessors = build_model(args)构建网络模型def build_model(args): return build(args)
build(args):
#构建模型
def build(args):
#设置识别目标类型,可根据自己的数据集修改
num_classes = 2 if args.dataset_file != 'coco' else 2
if args.dataset_file == "coco_panoptic":
num_classes = 2
#设置cpu或者GPU
device = torch.device(args.device)
#搭建主干网络
backbone = build_backbone(args)
#搭建transformer
transformer = build_transformer(args)
#搭建DETR模型
model = DETR(
backbone,
transformer,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
)
if args.masks:
model = DETRsegm(model)
matcher = build_matcher(args)
weight_dict = {'loss_ce': 1, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
if args.masks:
weight_dict["loss_mask"] = args.mask_loss_coef
weight_dict["loss_dice"] = args.dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
for i in range(args.dec_layers - 1):
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
if args.masks:
losses += ["masks"]
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict,
eos_coef=args.eos_coef, losses=losses)
criterion.to(device)
postprocessors = {'bbox': PostProcess()}
if args.masks:
postprocessors['segm'] = PostProcessSegm()
if args.dataset_file == "coco_panoptic":
is_thing_map = {i: i <= 90 for i in range(201)}
postprocessors["panoptic"] = PostProcessPanoptic(is_thing_map, True, threshold=0.85)
return model, criterion, postprocessorsbuild_backbone():包括构建位置编码器以及backbone
def build_backbone(args):
#搭建位置编码器
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
#是否需要记录backbone的每层输出
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
#将backbone和位置编码器集合在一起放在一个model里
model = Joiner(backbone, position_embedding)
#设置model的输出通道数
model.num_channels = backbone.num_channels
return modelbuild_position_encoding(args): 构建位置编码器,有两种方式,一种是使用正、余弦函数来对各位置的奇、偶维度进行编码,不需要额外的参数进行学习,DETR默认使用的就是这种正余弦编码。还有一种是可学习的。下面主要讲解正余弦编码
def build_position_encoding(args):
N_steps = args.hidden_dim // 2 #args.hidden_dim transformer的输入张量的channel数,位置编码和backbone的featuremap结合后需要输入到transformer中
#余弦编码方式,文章说采用正余弦函数,是根据归纳偏置和经验做出的选择
if args.position_embedding in ('v2', 'sine'):
# TODO find a better way of exposing other arguments
position_embedding = PositionEmbeddingSine(N_steps, normalize=True)
#可学习的编码方式
elif args.position_embedding in ('v3', 'learned'):
position_embedding = PositionEmbeddingLearned(N_steps)
else:
raise ValueError(f"not supported {args.position_embedding}")
return position_embeddingPositionEmbeddingSine(N_steps, normalize=True):正余弦编码方式,这种方式是将各个位置的各个维度映射到角度上,因此有个scale,默认是2pi。下面的是编码公式
作者为啥要设计如此复杂的编码规则?原因是sin和cos的如下特性
可参考:Transformer中的position encoding(位置编码一)_zuoyou-HPU的博客-CSDN博客_正余弦位置编码想帮你快速入门视觉Transformer,一不小心写了3W字……|向量|key|coco|编码器_网易订阅
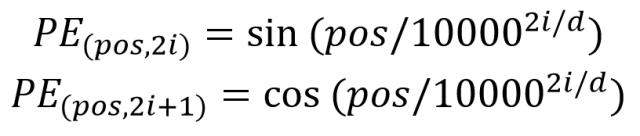
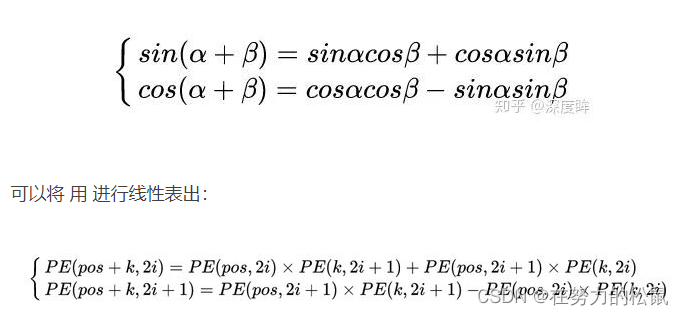
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats#transformer输入张量的channel大小//2
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list):
#(batch,channel,height,width)注意,height 和 width 是图像经过backbone后的featuremap的高宽,如果用resnet50作为backbone则height=图像Height//32,width=图像Width//32
x = tensor_list.tensors
#(batch,height,width) mask是为了指示那些位置是padding而来的,mask中值为true的部分就是padding的部分
mask = tensor_list.mask
#(batch,height,width)取反后not_mask中值为true的部分即为非padding的部分,真实有效
not_mask = ~mask
#cumsum()方法在列和行分别进行累加
#沿着列方向累加,并转为float型得到y_embed(batch,height,width)
# 示例:[[[1,1,1,...,1],
# [2,2,2,...,2],
# ...
# [h,h,h,...,h]],...]
y_embed = not_mask.cumsum(1, dtype=torch.float32)
#在行方向累加,并转为float型得到x_embed(batch,height,width)
# 示例:[[[1,2,3,...,w],
# [1,2,3,...,w],
# ...
# [1,2,3,...,w]],...]
x_embed = not_mask.cumsum(2, dtype=torch.float32)
# 进行归一化
if self.normalize:
eps = 1e-6
#y_embed[:, -1:, :]取每一个batch的最后一列全部元素组成新的矩阵(batch,1,width)
# 示例:[[[h,h,h,...,h]],
# ...
# [h,h,h,...,h]],...]
#对batch中每一个分别进行角度归一化
#得到公式中的pos
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
#torch.arange(start=0, end, step=1, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
#返回一个一维向量,其大小为(end-start)/step,取值区间为[start, end) ,从start开始,以step为步长增加,直到end结束(不包括end)
#创建0到(num_pos_feats-1)=127的步长为1的float一维张量
# tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.,
# 12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23.,
# ...
# 120., 121., 122., 123., 124., 125., 126., 127.], device='cuda:0')
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
#dim_t // 2得到有重复值的0到63的一维张量
# tensor([0., 0., 1., 1., 2., 2., 3., 3., 4., 4., 5., 5., 6., 6.,
# 7., 7., 8., 8., 9., 9., 10., 10., 11., 11., 12., 12., 13., 13.,
# ...
# 56., 56., 57., 57., 58., 58., 59., 59., 60., 60., 61., 61., 62., 62.,
# 63., 63.], device='cuda:0')
#(2 * (dim_t // 2) / self.num_pos_feats)得到
# tensor([0.0000, 0.0000, 0.0156, 0.0156, 0.0312, 0.0312, 0.0469, 0.0469, 0.0625,
# 0.0625, 0.0781, 0.0781, 0.0938, 0.0938, 0.1094, 0.1094, 0.1250, 0.1250,
# ...
# 0.9062, 0.9219, 0.9219, 0.9375, 0.9375, 0.9531, 0.9531, 0.9688, 0.9688,
# 0.9844, 0.9844], device='cuda:0')
#最后得到dim_t
# tensor([1.0000e+00, 1.0000e+00, 1.1548e+00, 1.1548e+00, 1.3335e+00, 1.3335e+00,
# 1.5399e+00, 1.5399e+00, 1.7783e+00, 1.7783e+00, 2.0535e+00, 2.0535e+00,
# 2.3714e+00, 2.3714e+00, 2.7384e+00, 2.7384e+00, 3.1623e+00, 3.1623e+00,
# ...
# 5.6234e+03, 5.6234e+03, 6.4938e+03, 6.4938e+03, 7.4989e+03, 7.4989e+03,
# 8.6596e+03, 8.6596e+03], device='cuda:0')
#pow(10000,2i/d),2i需要在num_pos_feats范围内,因此i为dim_t // 2,且这样就在一个张量里有了两个相同的张量分别表示奇数行列和偶数行列,方便后面操作
#得到公式中的分母1000^(2i/d),i = dim_t//2
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
#pos_x(b,h,w,num_post_feats) 得到公式中的pos/1000^(2i/d),因为图像是2D的,所以pos有横列两种
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
#torch.stack 沿着一个新维度进行堆叠拼接outputs = torch.stack(inputs, dim=?)
#inputs : 待连接的张量序列。dim : 新的维度, 必须在0到len(outputs)之间。len(outputs)=len(inputs)+1
#torch.sin() 会将输入值作为弧度而不是角度计算sin值,cos()类似
#0::2双冒号表示从0开始步长为2取值到最后,使用这个是为了将奇数行列用cos编码,偶数行列用sin编码
#torch.flatten(input, start_dim=0, end_dim=-1) start_dim:平铺的起始维度。end_dim: 平铺的结束维度。
#.flatten(3) 从第三维开始到最后一维进行平铺到一个维度上
#(batch,height,width,num_post_feats)得到公式的sin(pos/1000^(2i/d)) 和 cos(pos/1000^(2i/d))并放在一起
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
#torch.cat()将多给矩阵连接 outputs = torch.cat(inputs, dim=?) inputs : 待连接的张量序列;dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
#permute()将tensor的维度进行交换
#(batch,2*num_post_feats,height,width)将一个像素的位置可以用对应的横向编码和纵向编码值表示
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos得到位置编码pos,pos是一个(batch, 2* num_post_feats, height, width)的tensor,每个batch中的每一个前num_post_feats的(height, width)tensor表示y方向的位置编码pos_y, 后num_post_feats则表示x方向的位置编码,合并使用则可以得到类似(pos_y,pos_x)的效果来对2D张量进行位置编码
build_position得到位置编码后回到接下来回到build_backbone函数
def build_backbone(args):
#搭建位置编码器
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
#是否需要记录backbone的每层输出
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
#将backbone和位置编码器集合在一起放在一个model里
model = Joiner(backbone, position_embedding)
#设置model的输出通道数
model.num_channels = backbone.num_channels
return modelargs.lr_backbone默认为1e-5,则train_backbone默认为true,通过设置backbone的lr来设置是否训练网络时接收backbone的梯度从而让backbone也训练。return_interm_layers在后面解释。进入到Backbone()函数,args.backbone默认为resnet50,args.dilatyion默认为false。
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
#torchvision.models是pytorch的一个重要的包,包含了各种常用的网络结构,并且提供了预训练模型
#getattr(obj,name)获取obj中命名为name的组成。可以理解为获取obj.name
#获取torchvision.models中实现的resnet50网络结构
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=True, norm_layer=FrozenBatchNorm2d)
#replace_stride_with_dilation 决定是否使用膨胀卷积;pretrained 是否使用预训练模型;norm_layer 使用FrozenBatchNorm2d归一化方式
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)获得resnet50网络结构,并设置输出channels为2048,所以我们的backbone的输出则是(batch,2048,H//32,W//32),在父类BackboneBase.__init__中进行初始化。
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__() #调用nn.Module.__init__(),创建Backbone框架
for name, parameter in backbone.named_parameters():#对resnet50架构中的设置
#(python中优先级 not>or>and)
# 如果train_backbone为false,或者layer2,3,4都不在backbone中,backbone是用字典表示的,把backbone冻结,不进行梯度回传训练
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:#设置你想要能够获得输出的层
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': 0}
#IntermediateLayerGetter(Model)获取一个Model中你指定要获取的哪些层的输出,然后这些层的输出会在一个有序的字典中
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list):
xs = self.body(tensor_list.tensors)#输入的tensor list 经过backbone后得到featuremap
out = OrderedDict()#按顺序遍历layer,在return_layers中的layer输出则会放到out中
for name, x in xs.items():
#将mask插值带与输出特征图尺寸一致
mask = F.interpolate(tensor_list.mask[None].float(), size=x.shape[-2:]).bool()[0]
out[name] = NestedTensor(x, mask)#将图像张量与mask封装到一起
return out到这,位置编码和backbone都搭建完毕,回到build_backbone
def build_backbone(args):
#搭建位置编码器
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
#是否需要记录backbone的每层输出
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
#将backbone和位置编码器集合在一起放在一个model里
model = Joiner(backbone, position_embedding)
#设置model的输出通道数为backbone的输出通道数,resnet50为2048
model.num_channels = backbone.num_channels
return model接着在Joiner()中,将backbone和位置编码器用nn.Sequential()按顺序结合,forward可结合前面的一起来看,过一遍操作
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
#self[0]是backbone,self[1]是position_embedding
def forward(self, tensor_list):
#对backbone的输出进行位置编码,最终返回backbone的输出及对应的位置编码结果
xs = self[0](tensor_list)#tensor_list经过backbone后得到xs序列,其中每一个包括mask(batch, W/32,H/32)和featuremap(batch, 2042, W/32,H/32)
out = []
pos = []
for name, x in xs.items():
out.append(x) #把mask和featuremap添加到out中
# position encoding
pos.append(self[1](x).to(x.tensors.dtype))#把x作为输入给到位置编码器,得到的输出添加到pos中
return out, posbackbone搭建完成后,回到build(args),接下来是搭建transformer,就在DETR源码笔记(二)吧 。
文章出处登录后可见!