YOLOv5代码详解 (第一部分)
- 1. train.py
- 1.1 使用nvidia的apex接口计算混合精度训练
- 1.2 获取文件路径
- 1.3 获取数据路径
- 1.4 移除之前的结果
- 1.5 创建模型
- 1.6 检查训练和测试图片尺寸
- 1.7 设置优化器参数
- 1.8 加载预训练模型和权重,并写入训练结果到results.txt
- 1.9 把混合精度训练加载入训练中
- 1.10 设置cosine调度器,定义学习率衰减
- 1.11 定义并初始化分布式训练
- 1.12 载入训练集和测试集
- 1.13 模型参数
- 1.14 类别统计
- 1.15 检查anchors是否存在
- 1.16 指数移动平均
- 1.17 开始训练
- 1.17.1 获取参数
- 1.17.2 训练开始
- 1.18 定义模型文件名字
- 1.19 训练结束,返回结果
1. train.py
1.1 使用nvidia的apex接口计算混合精度训练
mixed_precision = True
try: # Mixed precision training https://github.com/NVIDIA/apex
from apex import amp
except:
print('Apex recommended for faster mixed precision training: https://github.com/NVIDIA/apex')
mixed_precision = False # not installed
1.2 获取文件路径
wdir = 'weights' + os.sep # weights dir
os.makedirs(wdir, exist_ok=True)
last = wdir + 'last.pt'
best = wdir + 'best.pt'
results_file = 'results.txt'
1.3 获取数据路径
# Configure
init_seeds(1)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dict
train_path = data_dict['train']
test_path = data_dict['val']
nc = 1 if opt.single_cls else int(data_dict['nc']) # number of classes
1.4 移除之前的结果
# Remove previous results
for f in glob.glob('*_batch*.jpg') + glob.glob(results_file):
os.remove(f)
1.5 创建模型
# Create model
model = Model(opt.cfg).to(device)
assert model.md['nc'] == nc, '%s nc=%g classes but %s nc=%g classes' % (opt.data, nc, opt.cfg, model.md['nc'])
model.names = data_dict['names']
assert是一个判断表达式,在assert后面成立时创建模型。
参考链接
1.6 检查训练和测试图片尺寸
# Image sizes
gs = int(max(model.stride)) # grid size (max stride)
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
1.7 设置优化器参数
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_parameters():
if v.requires_grad:
if '.bias' in k:
pg2.append(v) # biases
elif '.weight' in k and '.bn' not in k:
pg1.append(v) # apply weight decay
else:
pg0.append(v) # all else
optimizer = optim.Adam(pg0, lr=hyp['lr0']) if opt.adam else \
optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
Optimizer groups: 102 .bias, 108 conv.weight, 99 other
del并非删除数据,而是删除变量(删除指向数据的链接)参考链接
1.8 加载预训练模型和权重,并写入训练结果到results.txt
# Load Model
google_utils.attempt_download(weights)
start_epoch, best_fitness = 0, 0.0
if weights.endswith('.pt'): # pytorch format
ckpt = torch.load(weights, map_location=device) # load checkpoint
# load model
try:
ckpt['model'] = {k: v for k, v in ckpt['model'].float().state_dict().items()
if model.state_dict()[k].shape == v.shape} # to FP32, filter
model.load_state_dict(ckpt['model'], strict=False)
except KeyError as e:
s = "%s is not compatible with %s. Specify --weights '' or specify a --cfg compatible with %s." \
% (opt.weights, opt.cfg, opt.weights)
raise KeyError(s) from e
# load optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# load results
if ckpt.get('training_results') is not None:
with open(results_file, 'w') as file:
file.write(ckpt['training_results']) # write results.txt
start_epoch = ckpt['epoch'] + 1
del ckpt
1.9 把混合精度训练加载入训练中
若之前mixed_precision=False则不会加入混合精度训练至训练中。
if mixed_precision:
model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0)
opt_level=‘O1’ ,这里不是‘零1’,而是“O1”(偶1)
1.10 设置cosine调度器,定义学习率衰减
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: (((1 + math.cos(x * math.pi / epochs)) / 2) ** 1.0) * 0.9 + 0.1 # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch - 1 # do not move
1.11 定义并初始化分布式训练
# Initialize distributed training
if device.type != 'cpu' and torch.cuda.device_count() > 1 and torch.distributed.is_available():
dist.init_process_group(backend='nccl', # distributed backend
init_method='tcp://127.0.0.1:9999', # init method
world_size=1, # number of nodes
rank=0) # node rank
model = torch.nn.parallel.DistributedDataParallel(model)
当满足上面三个条件(非CPU、cuda设备大于1、分布式torch可用)时,就可以进行分布式训练了。
作者使用一张卡训练,不满足这个条件,也没有使用分布式训练。 ————————————————————————————————————————————————
nn.distributedataparallel()支持模型多进程并行,适用于单机或多机,每个进程都具备独立的优化器,执行自己的更新过程。
参考链接
1.12 载入训练集和测试集
# Trainloader
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect)
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Correct your labels or your model.' % (mlc, nc, opt.cfg)
# Testloader
testloader = create_dataloader(test_path, imgsz_test, batch_size, gs, opt,
hyp=hyp, augment=False, cache=opt.cache_images, rect=True)[0]
dataloader和testloader不同之处在于:
- testloader:没有数据增强,rect=True(大概是测试图片保留了原图的长宽比)
- dataloader:数据增强,保留了矩形框训练。
1.13 模型参数
# Model parameters
hyp['cls'] *= nc / 80. # scale coco-tuned hyp['cls'] to current dataset
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # giou loss ratio (obj_loss = 1.0 or giou)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) # attach class weights
1.14 类别统计
# Class frequency
labels = np.concatenate(dataset.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1.
# model._initialize_biases(cf.to(device))
if tb_writer:
plot_labels(labels)
tb_writer.add_histogram('classes', c, 0)
1.15 检查anchors是否存在
# Check anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
1.16 指数移动平均
# Exponential moving average
ema = torch_utils.ModelEMA(model)
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。参考博客
1.17 开始训练
1.17.1 获取参数
获取开始时间,batch size数量,epochs数量,图片数量。
# Start training
t0 = time.time() # start time
nb = len(dataloader) # number of batches
n_burn = max(3 * nb, 1e3) # burn-in iterations, max(3 epochs, 1k iterations)
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # 'P', 'R', 'mAP', 'F1', 'val GIoU', 'val Objectness', 'val Classification'
print('Image sizes %g train, %g test' % (imgsz, imgsz_test))
print('Using %g dataloader workers' % dataloader.num_workers)
print('Starting training for %g epochs...' % epochs)
# torch.autograd.set_detect_anomaly(True)
1.17.2 训练开始
加载图片权重(可选),定义进度条,设置偏差Burn-in,使用多尺度,前向传播,损失函数,反向传播,优化器,打印进度条,保存训练参数至tensorboard,计算mAP,保存结果到results.txt,保存模型(最好和最后)。
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional)
if dataset.image_weights:
w = model.class_weights.cpu().numpy() * (1 - maps) ** 2 # class weights
image_weights = labels_to_image_weights(dataset.labels, nc=nc, class_weights=w)
dataset.indices = random.choices(range(dataset.n), weights=image_weights, k=dataset.n) # rand weighted idx
# Update mosaic border
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(4, device=device) # mean losses
print(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'GIoU', 'obj', 'cls', 'total', 'targets', 'img_size'))
pbar = tqdm(enumerate(dataloader), total=nb) # progress bar
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device).float() / 255.0 # uint8 to float32, 0 - 255 to 0.0 - 1.0
# Burn-in
if ni <= n_burn:
xi = [0, n_burn] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # giou loss ratio (obj_loss = 1.0 or giou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [0.1 if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [0.9, hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
pred = model(imgs)
# Loss
loss, loss_items = compute_loss(pred, targets.to(device), model)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss_items)
return results
# Backward
if mixed_precision:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
# Optimize
if ni % accumulate == 0:
optimizer.step()
optimizer.zero_grad()
ema.update(model)
# Print
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = '%.3gG' % (torch.cuda.memory_cached() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * 6) % (
'%g/%g' % (epoch, epochs - 1), mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Plot
if ni < 3:
f = 'train_batch%g.jpg' % ni # filename
result = plot_images(images=imgs, targets=targets, paths=paths, fname=f)
if tb_writer and result is not None:
tb_writer.add_image(f, result, dataformats='HWC', global_step=epoch)
# tb_writer.add_graph(model, imgs) # add model to tensorboard
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
scheduler.step()
# mAP
ema.update_attr(model)
final_epoch = epoch + 1 == epochs
if not opt.notest or final_epoch: # Calculate mAP
results, maps, times = test.test(opt.data,
batch_size=batch_size,
imgsz=imgsz_test,
save_json=final_epoch and opt.data.endswith(os.sep + 'coco.yaml'),
model=ema.ema,
single_cls=opt.single_cls,
dataloader=testloader)
# Write
with open(results_file, 'a') as f:
f.write(s + '%10.4g' * 7 % results + '\n') # P, R, mAP, F1, test_losses=(GIoU, obj, cls)
if len(opt.name) and opt.bucket:
os.system('gsutil cp results.txt gs://%s/results/results%s.txt' % (opt.bucket, opt.name))
# Tensorboard
if tb_writer:
tags = ['train/giou_loss', 'train/obj_loss', 'train/cls_loss',
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/F1',
'val/giou_loss', 'val/obj_loss', 'val/cls_loss']
for x, tag in zip(list(mloss[:-1]) + list(results), tags):
tb_writer.add_scalar(tag, x, epoch)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # fitness_i = weighted combination of [P, R, mAP, F1]
if fi > best_fitness:
best_fitness = fi
# Save model
save = (not opt.nosave) or (final_epoch and not opt.evolve)
if save:
with open(results_file, 'r') as f: # create checkpoint
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'training_results': f.read(),
'model': ema.ema.module if hasattr(model, 'module') else ema.ema,
'optimizer': None if final_epoch else optimizer.state_dict()}
# Save last, best and delete
torch.save(ckpt, last)
if (best_fitness == fi) and not final_epoch:
torch.save(ckpt, best)
del ckpt
# end epoch ----------------------------------------------------------------------------------------------------
# end training
Image sizes 608 train, 608 test(设置训练和测试图片的size)
Using 8 dataloader workers(设置batch size 为8,即一次性输入8张图片训练)
Starting training for 100 epochs… (设置为100个epochs)
—————————————————————————————————————————————
tqdm是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
参考博客
tqdm进度条
python pbar = tqdm(enumerate(dataloader), total=nb)表示进度条,total=nb预期的迭代次数,即你上面设置的epochs。
—————————————————————————————————————————————
results.txt保存结果:
0/49 6.44G 0.09249 0.07952 0.05631 0.2283 6 608 0.1107 0.1954 0.1029 0.03088 0.07504 0.06971 0.03865
epoch, best_fitness, training_results, model, optimizer, img-size, P, R, mAP, F1, test_losses=(GIoU, obj, cls)
(有点不对,以后再补充)
1.18 定义模型文件名字
n = opt.name
if len(n):
n = '_' + n if not n.isnumeric() else n
fresults, flast, fbest = 'results%s.txt' % n, wdir + 'last%s.pt' % n, wdir + 'best%s.pt' % n
for f1, f2 in zip([wdir + 'last.pt', wdir + 'best.pt', 'results.txt'], [flast, fbest, fresults]):
if os.path.exists(f1):
os.rename(f1, f2) # rename
ispt = f2.endswith('.pt') # is *.pt
strip_optimizer(f2) if ispt else None # strip optimizer
os.system('gsutil cp %s gs://%s/weights' % (f2, opt.bucket)) if opt.bucket and ispt else None # upload
1.19 训练结束,返回结果
if not opt.evolve:
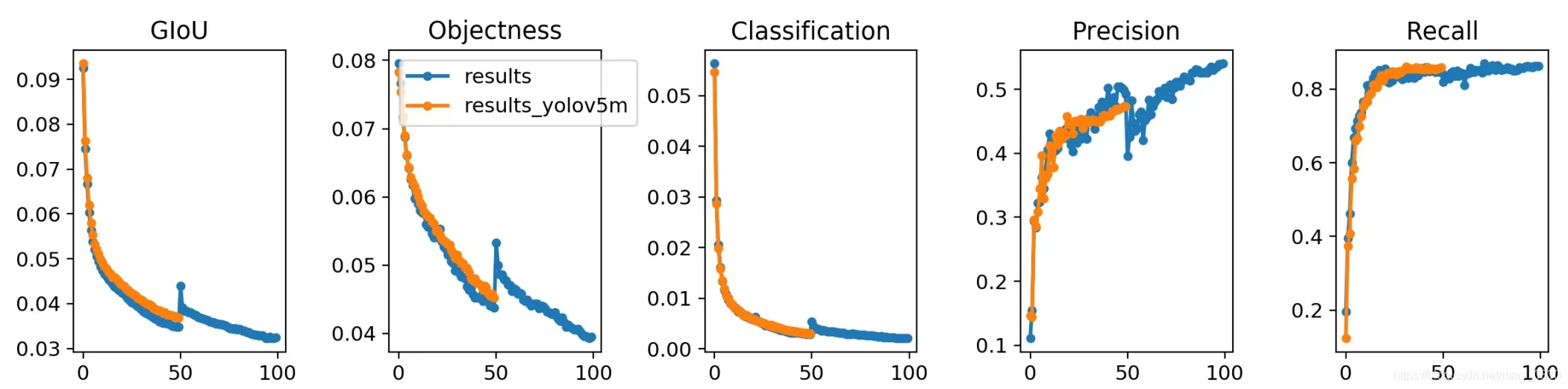
plot_results() # save as results.png
print('%g epochs completed in %.3f hours.\n' % (epoch - start_epoch + 1, (time.time() - t0) / 3600))
dist.destroy_process_group() if device.type != 'cpu' and torch.cuda.device_count() > 1 else None
torch.cuda.empty_cache()
return results
50 epochs completed in 11.954 hours.
版权声明:本文为博主Liaojiajia-2020原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/mary_0830/article/details/107076617