数据分布
- 我们一般会有train(训练集),val(验证集),test(测试集)。
- 再训练时使用训练集和验证集,验证集用于选择模型参数,保证模型不会过拟合
- 测试集用于测试训练后的训练结果
交叉验证
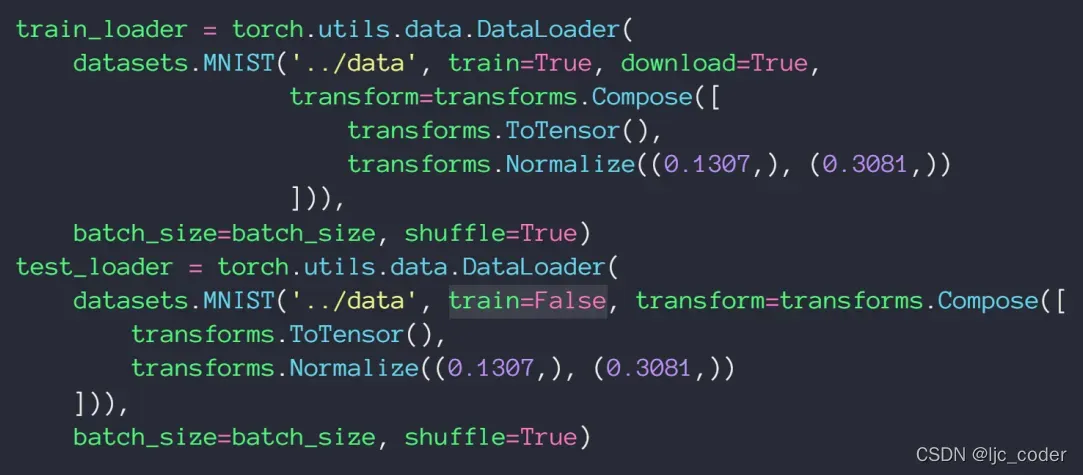
- pytorch中之支持把数据集划分为train和test两种(通过参数train=true、false),因此需要val 验证集时,一般通过random_split()函数分割

正则化
- 正则化用于避免过拟合
- 有L1正则化(损失函数上加一个一范数)
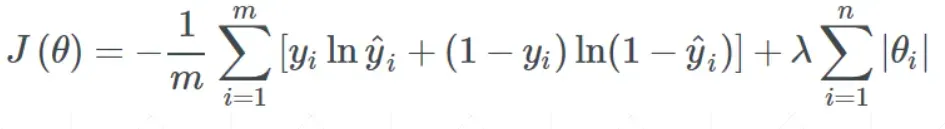
- L2正则化(损失函数上加一个二范数)
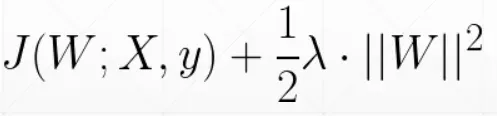
- 在pytorch中,对于L2正则化,可以直接设置参数weight_decay 的值,作为λ 的值

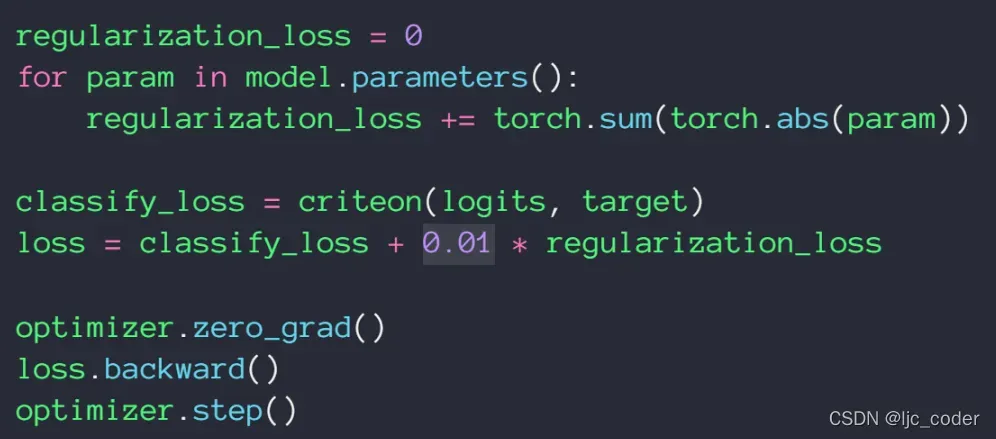
- 对于L1正则化,则需使用下例的方法,直接写出
动量(惯性),学习率衰减
- 一般需要加动量只需要像下例这样,增加一个momentum参数即可,但是Adam优化器没有这个参数,因为其内置了类似该参数的算法。

- 可以使用ReduceLROnPlateau()函数,监听loss,当运行‘min’个epoch,loss都没减少,就会自动减少learningrate值

- 也可以stepLR()函数,固定几个epoch减少固定的 lerarningrate 值

dropout
- 去除一些点特征点
- 在pytorch中实现非常简单

- 但要注意,在pytorch中Dropout的参数是保留(1-p)的概率,而tensorflow中的参数是保留的概率

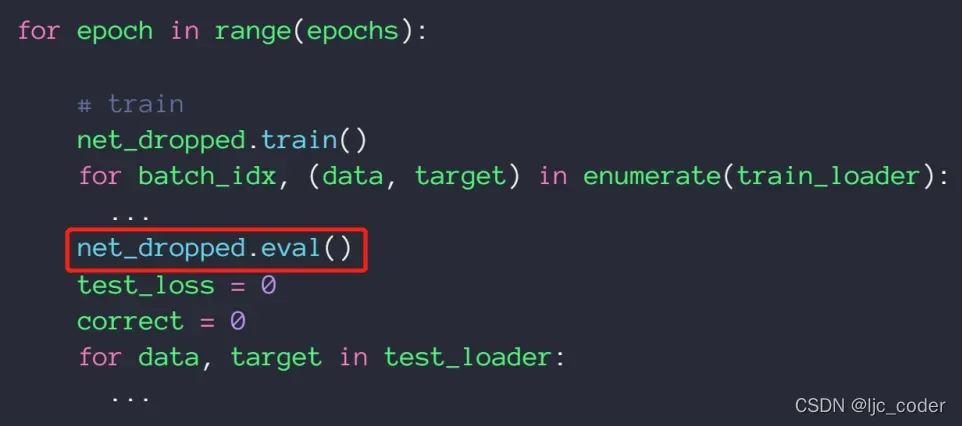
- 另外在test时,要用eval把dropout去掉,提高test结果
版权声明:本文为博主ljc_coder原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_52785249/article/details/123015105