概括
1、网络结构
3*3卷积滤波器,将深度推进到16~19层
一、简介
本文讨论了ConvNet架构设计的另一个重要方面—深度。修复了架构的其他参数,并通过增加更多的卷积层来稳步增加网络深度,因为在所有层中都应用了非常小的3*3卷积滤波器,所以增加这么多卷积层这种方法是可行的。
二、卷积网络的配置
所有的卷积网络层的的配置都参照的AlexNet原则做
1、结构
输入到卷积网络的是一个修复过的大小为224*224的RGB图像(图像预处理是将每个像素减去在训练集上计算的平均RGB值),处理后迭代更少,更快收敛,加速网络训练。
卷积层所用的过滤器为3×3大小(这是能抓住上下左右以及中间所有信息的最小的过滤器大小);有些卷积层中还使用了1×1大小的卷积滤波器(FC层之间的),可看作是输入通道的线性变换。卷积步幅固定为1像素,3×3卷积层的填充设置为1个像素。
池化层采用空间池化,空间池化有五个最大池化层,他们跟在一些卷积层之后,但是也不是所有的卷积层后都跟最大池化。最大池化层使用2×2像素的窗,步幅为2。
卷积层后跟三个FC层:第一、二个FC层有4096个通道,第三个FC层执行1000路ILSVRC分类因此包括1000个通道(通道对应每个类别)。所有网络的全连接层配置相同。
最后一层是softmax层,用来分类。
所有隐藏层都有ReLU非线性函数,网络除了第一个其他都不包含局部响应归一化(LRN)
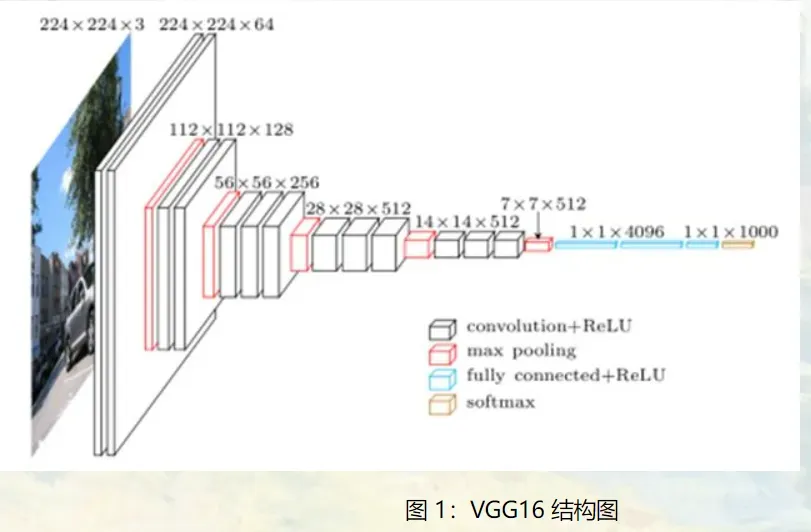
2、配置
A~E指代网络,所有配置都遵循第1节的设计
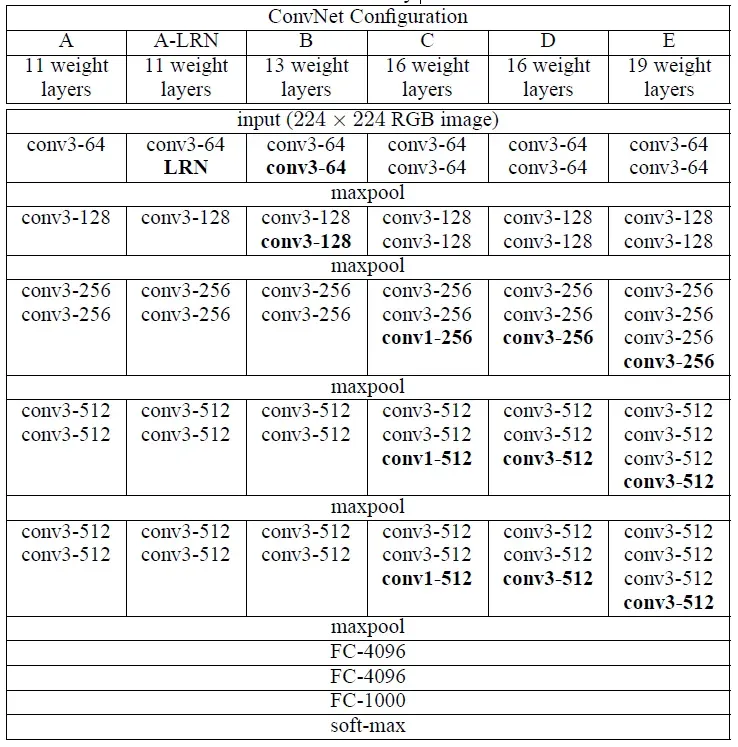
从左(A)到右(E),随着层数的增加,卷积层参数表示为conv<感受野尺寸>-<通道数量>
注意:层数只计算卷积层和全连接层,不考虑softmax和max-pooling
3、讨论
1、对比(第一个卷积层感受野大小):
AlexNet:11×11,步长为4
ZFNet:7×7,步长为2
VGGNet:3×3,步长为1
2、好的效益:两个3×3的卷积层堆叠(中间没有空间池化层)具有5×5的有效感受野;三个3×3卷积层堆叠有7×7有效感受野
3、为什么有好的效益:①合并了三个非线性ReLU层,不是只用一个,使得决策函数更具有判别性。
②减少了参数数量:27C2>>49C2
合并1×1卷积层是一种在不影响卷积层感受野情况下增加决策函数非线性性质的方法。
4、每个VGG网络都有3个FC层,5个池化层,1个softmax层。
5、在 FC 层中间采用 dropout 层,防止过拟合,如下图:
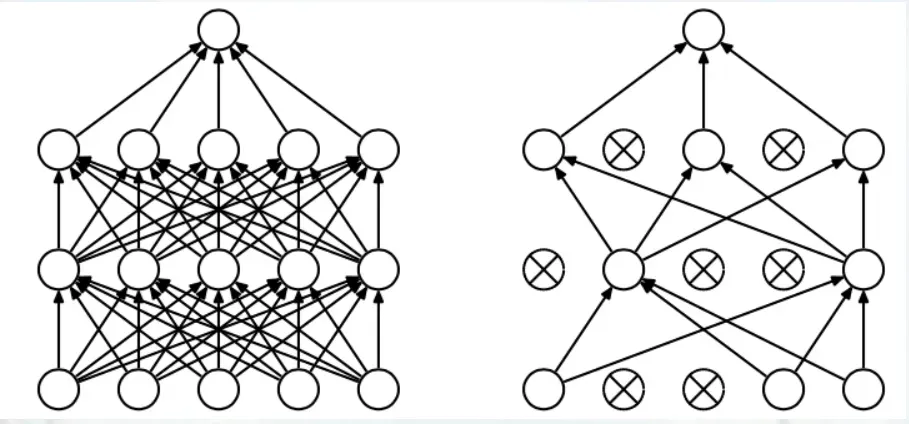
6、如今用得最多的是 VGG16(13 层 conv + 3 层 FC)和 VGG19(16 层 conv + 3 层 FC),注意算层数时不算 maxpool 层和 softmax 层,只算 conv 层和 fc 层。
3.1、Dropout详解
上图左边的为一个完全的全连接层,右边为应用 dropout 后的全连接层。
我们知道,典型的神经网络其训练流程是将输入通过网络进行正向传导,然后将误差进行反向传播。dropout 就是针对这一过程之中,随机地删除隐藏层的部分单元,进行上述过程。步骤为:
(1)、随机删除网络中的一些隐藏神经元,保持输入输出神经元不变;
(2)、将输入通过修改后的网络进行前向传播,然后将误差通过修改后的网络进行反向传播;
(3)、对于另外一批的训练样本,重复上述操作 (1)。
dropout 可以有效防止过拟合,原因是:
(1)、达到了一种投票的作用。对于单个神经网络而言,将其进行分批,即使不同的训练集可能会产生不同程度的过拟合,但是我们如果将其公用一个损失函数,相当于对其同时进行了优化,取了平均,因此可以较为有效地防止过拟合的发生。
(2)、减少神经元之间复杂的共适应性。当隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。也就是说,有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过 dropout 的话,就有效地组织了某些特征在其他特征存在下才有效果的情况,增加了神经网络的鲁棒性。
参考:VGG Net学习笔记 – 别再闹了 – 博客园)
3.分类框架
1、训练
1、卷积网络训练步骤大致跟随AlexNet,除了从多尺度训练图像中对输入进行采样,也就是说通过使用小批量梯度下降法优化多项式逻辑回归目标来进行训练。批量大小为:256,动量为:0.9。训练通过权重衰减(L2惩罚函数设置为5*10^-4)和Dropout正则化对前两层FC层作用(Dropout率设置为0.5)。学习率初始化设置为:0.01,然后当验证集准确率停止增加时学习率衰减为原来的0.1,总之学习率要减小三次,在370K次迭代(74epoch之后)停止学习。
推测与AlexNet相比,VGGnet有更多的参数和更大的深度,但是网络需要更少的周期就能达到收敛,这是因为:①更深层和更小的卷积层所施加的隐式正则化 ②某些层的预初始化
2、初始化权重:网络配置A随机初始化,然后对更深层次网络结构,将前四层卷积层和后三个FC层都按照A网络的初始化配置设置,中间层接着随机初始化。没有减少预初始化层的学习率,而是让它们随着学习的进程发生改变。
对于随机初始化,我们从一个均值为0方差为0.01的正态分布中对权重进行采样,偏置初始化为0
发现:使用随机初始化器可以在没有预训练的情况下初始化权重。
3、从重缩放的训练集图像中进行随机裁剪(每次SGD迭代每幅图像都要做一次裁剪)。为进一步增加训练集,输入图像需要做随机水平翻转和随机RGB颜色偏移。
训练图像重缩放:两种固定尺度的模型(①S=256,应用于AlexNet,ZFNet,Sermanet;②S=384)。
考虑两种设定训练规模S的方法:
方法一:给定一个卷积网络配置,首先使用S=256训练网络,为了加速S=384网络的训练,它使用S=256预训练的权重进行初始化,使用初始学习率为0.003。
方法二:多尺度训练,每个训练图像通过从某个范围中随机采样S来单独重缩放(范围为[256,512])
2、测试
全连接层等效替换为卷积层进行测试,原因是:
卷积层和全连接层的唯一区别就是卷积层的神经元和输入是局部联系的,并且同一个通道(channel)内的不同神经元共享权值(weight)。卷积层和全连接层的计算实际上相同,因此可以将全连接层转换为卷积层,只要将卷积核大小设置为输入空间大小即可:例如输入为7x7x512,第一层全连接层输出4096;我们可以将其看作卷积核大小为7×7,步长为1,没有填充,输出为1x1x4096的卷积层。这样的好处在于输入图像的大小不再受限制,因此可以高效地对图像作滑动窗式预测;而且全连接层的计算量比较大,等效卷积层的计算量减小了,这样既达到了目的又十分高效。
为什么卷积层可以“替代”全连接层?
卷积和全连接的区别大致是:卷积是局部连接,计算局部信息;全连接是全局连接,计算全局信息。 (但都使用点积运算)
但如果卷积核的kernel_size和输入feature maps的size一样,那么相当于该卷积核计算了全部feature maps的信息,则相当于是一个kernel_size∗1的全连接。在全连接层上,相当于是n∗m(其中n是输入的维度,m是输出的维度)的全连接,其计算是通过一次导入到内存中计算完成;如果是在最后一个feature maps上展开后进行的全连接,这里若不进行展开,直接使用output_size的卷积核代替,则相当于是n∗1的全连接(这里的n就是feature maps展开的向量大小,也就是卷积核的大小kernel_size∗kernel_size),使用m个卷积核则可以相当于n∗m的全连接层。
但是通过用卷积层代替全连接层,卷积核的计算是并行的,不需要同时读入内存,所以用卷积层代替全连接层可以增加模型的优化。
———————————————
版权声明:本文为CSDN博主「胥洪利」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42546496/article/details/87915453
为什么我们不能使用卷积层而不是全连接层,以便模型可以处理不同大小的输入?
因为卷积层的操作是通过卷积核,归根结底就是点积操作,需要提前设置参数的大小。
但如果这种操作用于处理不同size的输入,则实际上每次训练时,该层的参数size是不一样的,也就是模型不能得到训练。
尽管使用卷积层而不是全连接层来处理不同大小的输入的模型在整个过程中看起来不错,但从根本上说,该模型无法很好地训练。 (从被替换的卷积层开始,后续各层得到的输入分布其实一直在变化,所以波动会比较大。)
———————————————
版权声明:本文为CSDN博主「胥洪利」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42546496/article/details/87915453
3、实施细节
实施了许多重大修改使得可以在单个系统中安装的多个GPU上执行训练和评估,以及训练和评估多尺度的全尺寸(未裁剪)图像。通过将每批训练图像分成几个GPU批次,在每个GPU上并行处理来进行,计算GPU批次梯度后,对它们进行平均可以获得完整批次的梯度。梯度计算在GPU之家是同步的,因此结果与在单个GPU上训练的结果是一样是的,但是可以节约很多时间。
4.分类实验
数据集:ILSVRC,1000类,分成三份(训练集1,300,000张,验证集50,000张,测试集100,000张),其中测试集拿掉标签
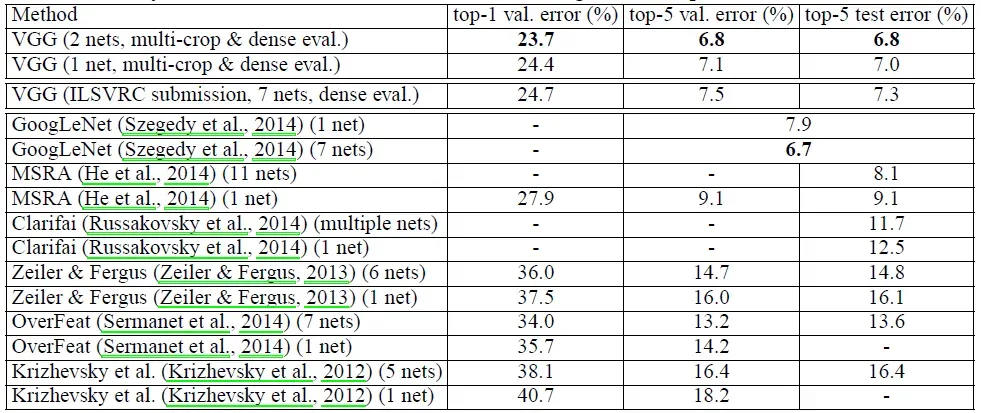
1、单尺度评估
用LRN方法不会提高模型A的性能(此时模型A没有任何归一化层),因此在更深的B~E层也不应用归一化方法。
随着网络的深入,分类误差减少,虽然额外的非线性有所帮助,但使用卷积滤波器捕获空间上下文的能力也很重要。具有小型卷积机的深度网络往往比具有大型卷积机的浅层网络表现更好。
使用尺度抖动增强训练集有助于捕获多尺度图像数据
2、多尺度评估
测试时缩放抖动会带来更好的性能。
3、多裁剪评估
多作物评价优于深度评价,这两种方法是互补的,即两种方法的组合优于其中任何一种
4、卷积网络融合
通过平均它们的soft-max类后验来结合一些模型的输出,这会提高他们的性能由于模型之间的互补性质。融合之后网络的错误率要比单个网络的错误率低0.几个百分点,且使用密集评估和多裁剪方法结合的方法会使得效果更佳。
五、结论
深度对网络正确率的影响是有益的,可以用传统的卷积神经网络架构(Lenet和AlexNet)在此基础上达到ImageNet的最佳性能
实践
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为*[Math Processing Error]3\times 33×3的卷积层后接上一个步幅为2、窗口形状为[Math Processing Error]2\times 2*2×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
能够
实践
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为*[Math Processing Error]3\times 33×3的卷积层后接上一个步幅为2、窗口形状为[Math Processing Error]2\times 2*2×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
版权声明:本文为博主秋天的风儿原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40635082/article/details/123015740