本文将持续更新。
1. 基本GAN
1.1 GAN(2014)
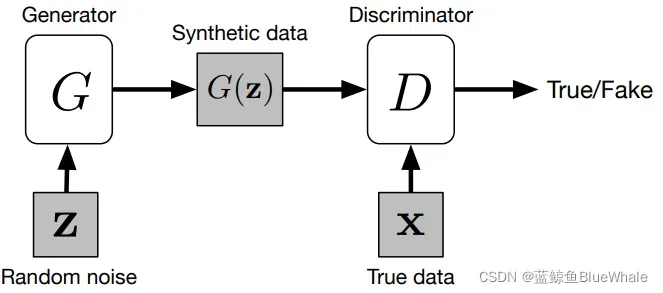
原始GAN由生成器和判别器
构成,生成器的目的就是将随机输入的高斯噪声映射成图像(“假图”),判别器则是判断输入图像是否来自生成器的概率,即判断输入图像是否为假图的概率。
GAN的训练是个动态的过程,是生成器与判别器
两者之间的相互博弈过程。生成器G要生成假图骗过判别器
,而判别器
要分辨生成器
生成的假图。GAN的损失函数如下:
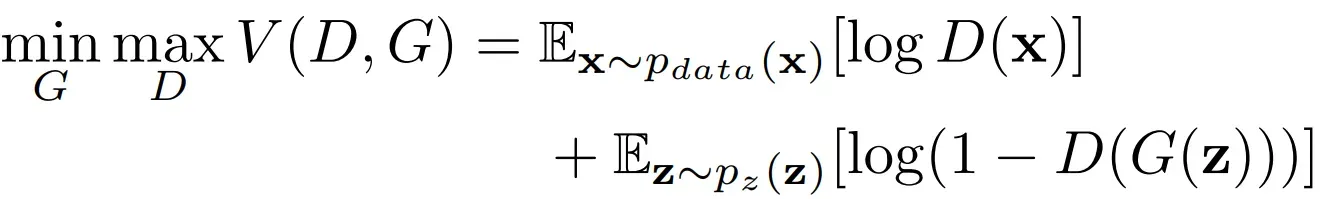
其中,代表生成器,
代表判别器,
代表真实数据,
代表真实数据的概率密度分布,
代表随机输入数据,即随机高斯噪声。
从上式可以看出,从判别器角度来看,判别器
希望能尽可能区分真实样本x和虚假样本
,因此
必须尽可能大,
尽可能小, 也就是
整体尽可能大。从生成器
的角度来看,生成器
希望自己生成的虚假数据
可以尽可能骗过判别器
,也就是希望
尽可能大,也就是
整体尽可能小。GAN的两个模块在训练相互对抗,最后达到全局最优。图源。
训练过程的代码示例如下。
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
1.2 CGAN(2015)
CGAN的主要贡献是在原始GAN的生成器与判别器中的输入中加入额外标签信息。额外信息
可以是任何信息,主要是标签。因此CGAN的提出使得GAN可以利用图像与对应的标签进行训练,并在测试阶段利用给定标签生成特定图像。其损失函数如下:
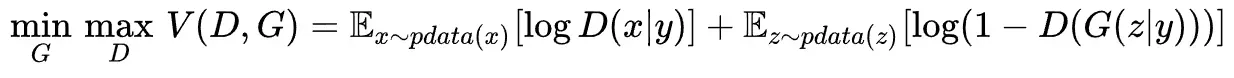
在CGAN的论文中,网络架构使用的MLP(全连接网络)。在CGAN中的生成器,我们给定一个输入噪声和额外信息
,之后将两者通过全连接层连接到一起,作为隐藏层输入。同样地,在判别器中输入图像
和 额外信息
也将连接到一起作为隐藏层输入。
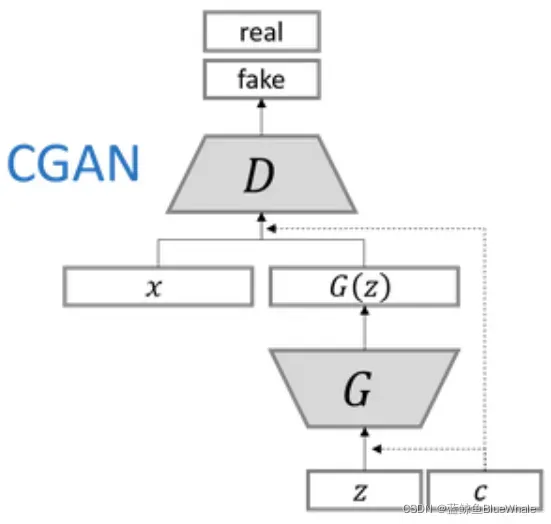
CGAN和GAN的区别如下:
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
# define labels and gen_labbels:
labels = Variable(labels.type(LongTensor))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# -----------------
# Train Generator
# -----------------
# input + genlabels
gen_imgs = generator(z, gen_labels)
validity = discriminator(gen_imgs, gen_labels)
# ---------------------
# Train Discriminator
# ---------------------
# input + labels or genlabels
validity_real = discriminator(real_imgs, labels)
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
1.3 DCGAN(2015)
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器与判别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面:
- DCGAN的生成器和判别器都舍弃了CNN的池化层,判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(或称转置卷积层)。
- 在判别器和生成器中在每一层之后都是用了BN层,有助于处理初始化不良导致的训练问题,加速模型训练,提升了训练的稳定性。
- 利用1*1卷积层替换到所有的全连接层。
- 在生成器中除输出层使用Sigmoid激活函数,其余层全部使用ReLu激活函数。
- 在判别器所有层都使用LeakyReLU激活函数,防止梯度稀疏。
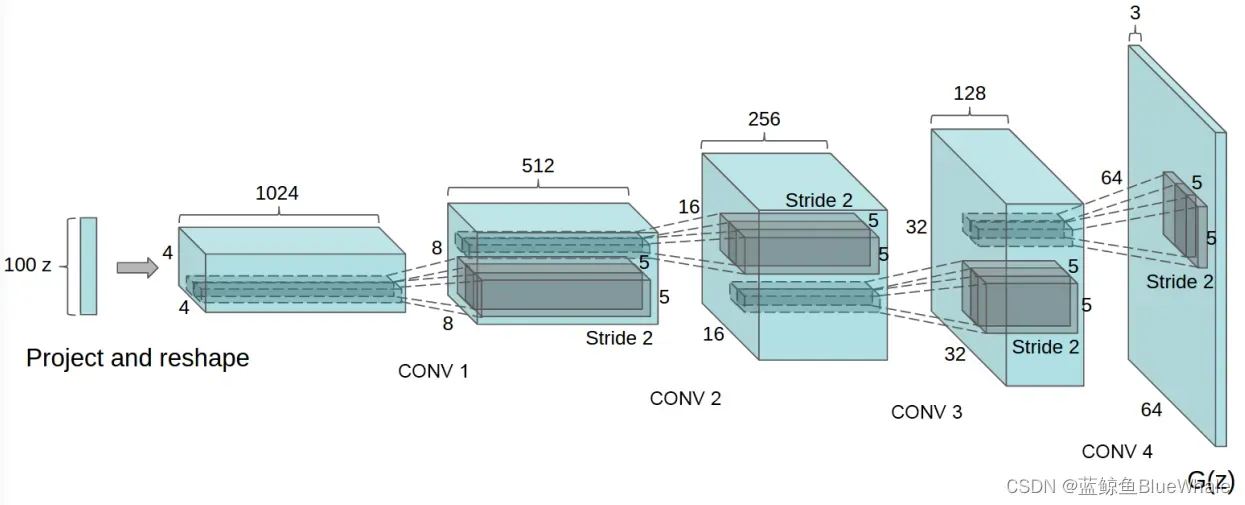
1.4 VAE-GAN(2016)
变分自编码器VAE是由一个编码器和一个解码器组成的结构,编码器可以将数据映射到一个低维的空间分布,而解码器可以将这个分布还原回原始数据,因此解码器是很像GAN中的生成器。VAE的目的也和GAN相似,都是希望构建一个从隐变量生成目标数据
的模型。
如果在VAE后面拼接上一个判别器D,这样的话,前两个模块就是VAE,后两个模块就是GAN:
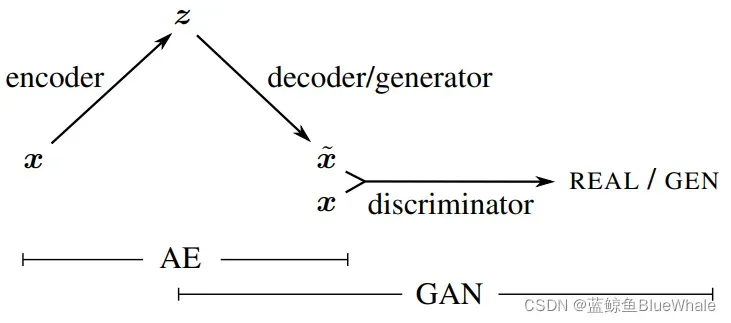
从VAE的角度,VAE解码产生的图片往往都比较模糊,GAN中的判别器来判别图片是不是真实的,可以来帮助VAE提高真实性。从GAN的角度,原本生成器输入都是随机的,训练起来比较难,而VAE可以提供生成器输入的大概空间分布,会变得准确高效一些。因此VAE和GAN相辅相成,都可达到更优秀的效果。
1.5 ACGAN(2017)
为了提供更多的辅助信息并允许半监督学习,可以向判别器添加额外的辅助分类器,以便在原始任务以及附加任务上优化模型。这种方法的体系结构如下图所示,其中C是辅助分类器。 添加辅助分类器允许我们使用预先训练的模型(例如,在ImageNet上训练的图像分类器)。
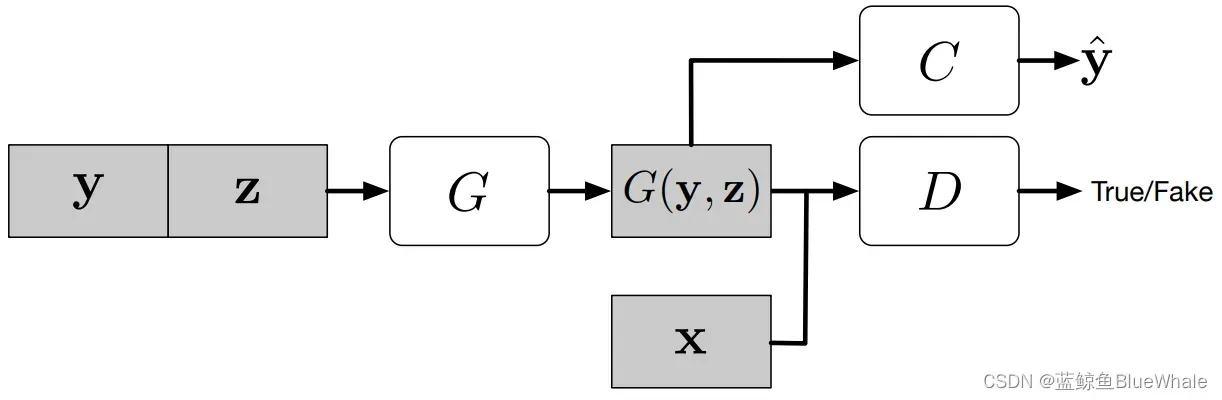
ACGAN和CGAN的代码的区别如下,在辨别器D中增加adv层和aux层,用来计算Label:
class Discriminator(nn.Module):
def __init__(self):
self.conv_blocks = ...
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.n_classes), nn.Softmax())
def forward(self, img):
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
label = self.aux_layer(out)
return validity, label
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
# -----------------
# Train Generator
# -----------------
# output the pred_label and add auxiliary_loss
validity, pred_label = discriminator(gen_imgs)
g_loss = 0.5 * (adversarial_loss(validity, valid) + auxiliary_loss(pred_label, gen_labels))
# ---------------------
# Train Discriminator
# ---------------------
# Loss for real images
real_pred, real_aux = discriminator(real_imgs)
d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2
# Loss for fake images
fake_pred, fake_aux = discriminator(gen_imgs.detach())
d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, gen_labels)) / 2
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
# Calculate discriminator accuracy
pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)
gt = np.concatenate([labels.data.cpu().numpy(), gen_labels.data.cpu().numpy()], axis=0)
d_acc = np.mean(np.argmax(pred, axis=1) == gt)
1.6 styleGAN(2018)
StyleGAN也可以算作图像生成领域的应用,但是由于它主要改变网络结构,因此我们将它归类于第一章。
StyleGAN提出了一个新的生成器结构如下:
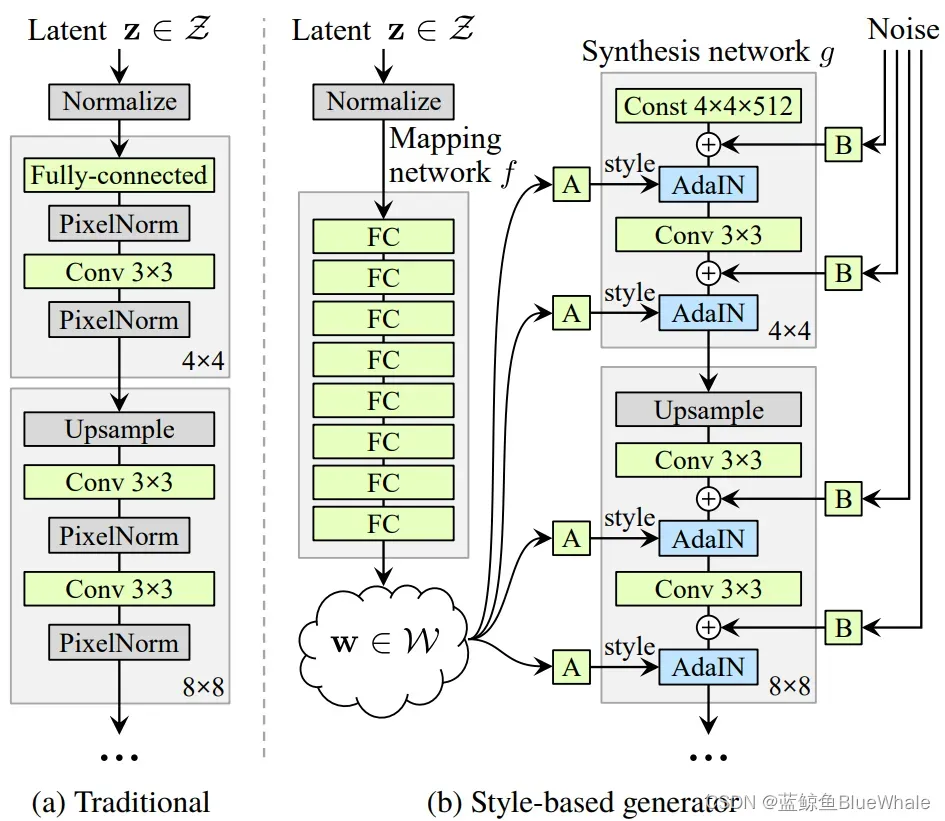
不同于以往的GAN论文把输入给生成器的输入层的做法,StyleGAN在生成器各层都注入噪音,且摒弃了输入层, 转而添加了一个从
到
的非线性映射网络,将输入
用了8层全连接层做了个非线性变换,得到
。
图中,和
的维度都是512维,
是一个仿射变换,
是每个通道的高斯噪声的系数,而AdaIN则是:
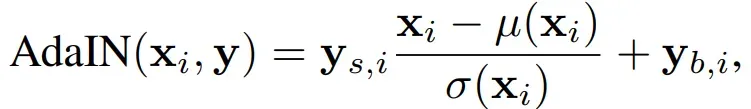
图中,则是
经过
变换之后得到的style:
,
对的个数与每一层特征图的通道数相同,对应每一层归一化所需的scale和shift。
为进一步促使style局部化图像转换的控制效果,作者采用了mixing regularization。利用生成器中8层卷积的非线性变换,提前计算两个图像的变换结果,然后在生成过程中随机取
或者
的值进行操作。结果如下,可以看到横轴和纵轴上的原始图像不同程度地影响了生成的图像。

2. GAN在图像生成领域的应用
2.1 Pix2Pix(2017)
Pix2Pix可以称之为用CGAN做image translation的鼻祖,先看一下他的效果:

一般训练过程如下:
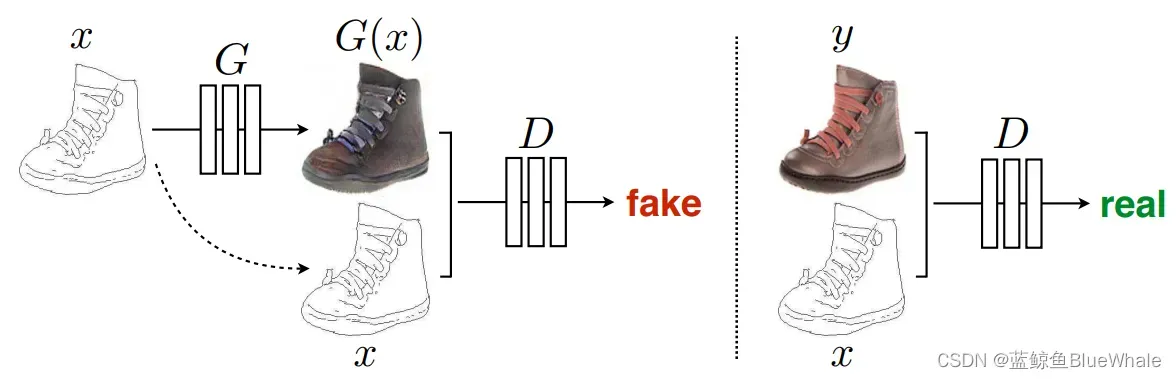
我们将CGAN的结构放在下面以方便对比。可以看到,Pix2Pix采用CGAN的结构,将图片作为CGAN的条件(相当于是一个”鞋“的标签),输入到
和
中。
的输入是
(其中,
是需要转换的图片,
是随机噪声),输出是生成的图片
。
则需要分辨出
和
。
Pix2Pix使用的生成器用到的是Unet结构,输入的轮廓图
编码再解码成真是图片,判别器D用到的是作者自己提出来的条件判别器PatchGAN。损失函数如下:
- CGAN损失函数:
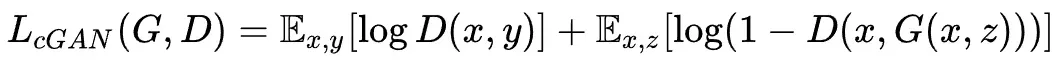
- 与ground truch的loss:
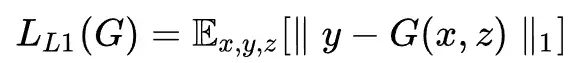
- 最终损失:
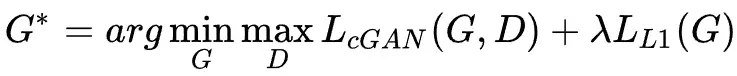
但是,Pix2Pix的一个限制在于网络学习的是到
之间的一对一映射。这样的一个明显的缺点就是对数据集的限制:需要大量对应的图片,例如同一个地方的黑夜和白天的图片。
代码:
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs, A is label
real_A = Variable(batch["B"].type(Tensor))
real_B = Variable(batch["A"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
# same process as CGAN
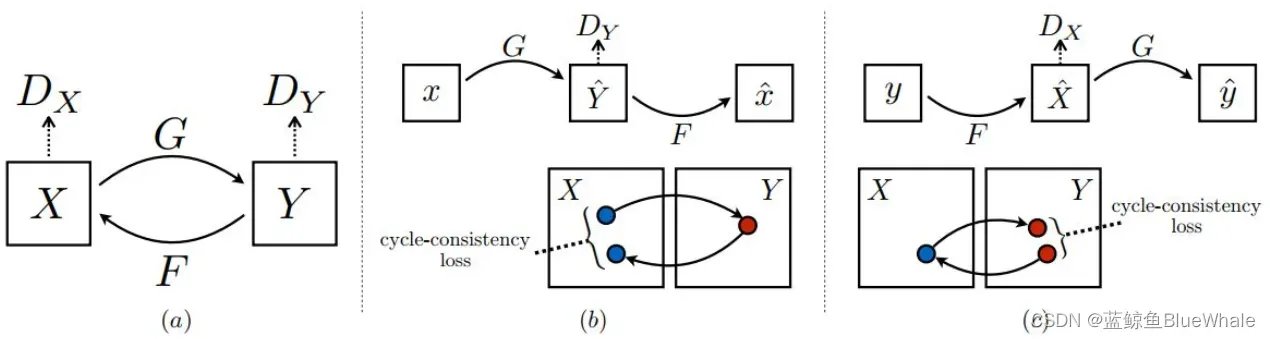
2.2 cycleGAN(2017)
相比于Pix2Pix需要两个域中有相同数据的训练样本。CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移,效果如下:

CycleGAN由两个判别器(和
)和两个生成器(
和
)组成,生成器
和
分别是
到
和
到
的映射,两个判别器
和
对转换后的图片进行判别。双判别器的目的是为了建立一对一的映射,避免所有的
都被映射到同一个
,例如所有男人的图像都映射到刘亦菲的图像上。起到同样作用的是cycle-consistency loss,用数据集中其他的图来检验生成器,防止
和
过拟合。
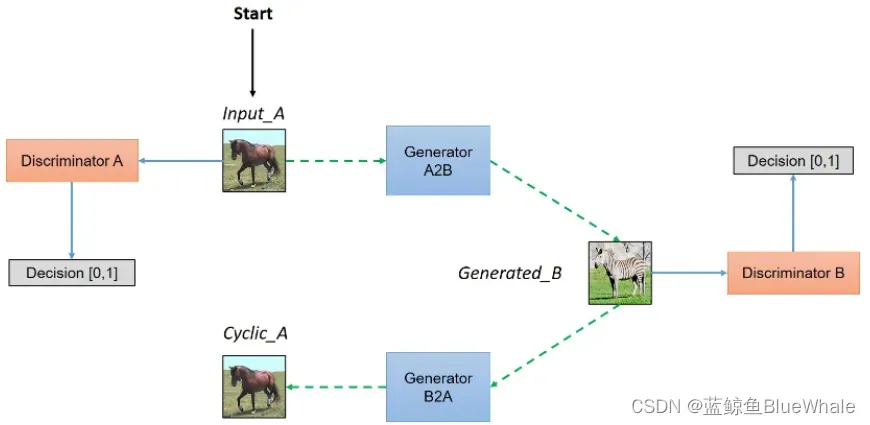
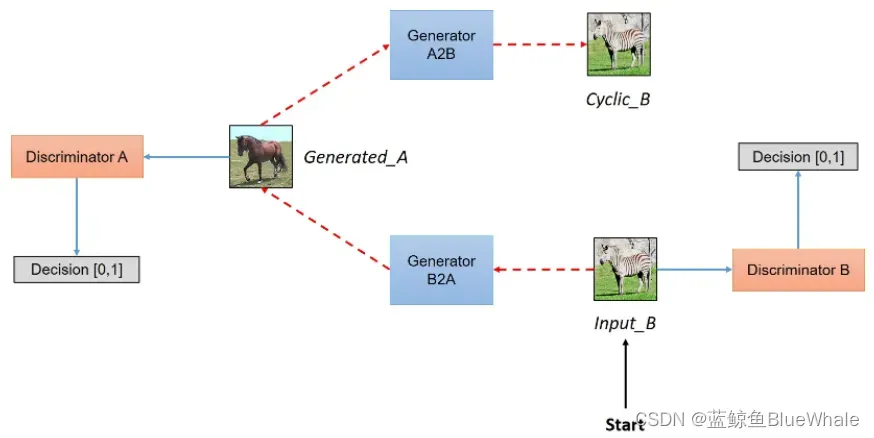
CycleGAN的训练过程如下,两张图分别表示从域到
域的图像生成和从
域到
域的图像生成。其中Input_A表示输入的真实图像,Generated_B表示由表示由Input_A转换得到的图像,Cyclic_A表示由Input_A转换一圈得到的图像。反之亦然。图源。
损失函数包含:
- 对抗性损失函数
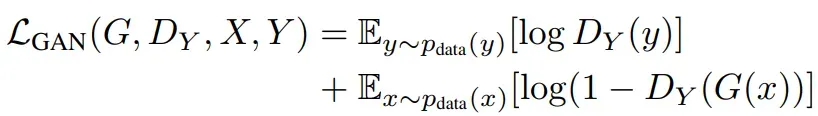
和双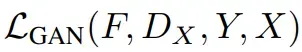
- Cycle Consistency 损失
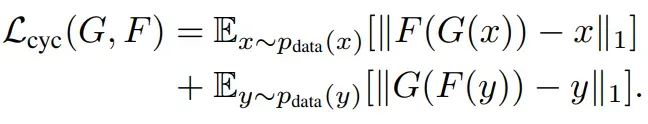
- 总体损耗
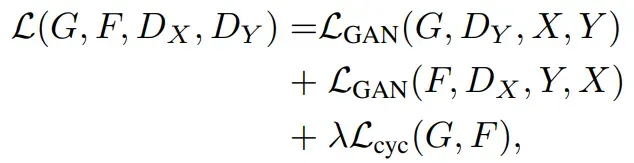
代码显示如下:
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *D_A.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *D_A.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity loss
loss_id_A = criterion_identity(G_BA(real_A), real_A)
loss_id_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_id_A + loss_id_B) / 2
# GAN loss
fake_B = G_AB(real_A)
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
fake_A = G_BA(real_B)
loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle loss
recov_A = G_BA(fake_B)
loss_cycle_A = criterion_cycle(recov_A, real_A)
recov_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recov_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss
loss_G = loss_GAN + opt.lambda_cyc * loss_cycle + opt.lambda_id * loss_identity
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator A
# -----------------------
optimizer_D_A.zero_grad()
# Real loss
loss_real = criterion_GAN(D_A(real_A), valid)
# Fake loss (on batch of previously generated samples)
fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
# Total loss
loss_D_A = (loss_real + loss_fake) / 2
loss_D_A.backward()
optimizer_D_A.step()
# -----------------------
# Train Discriminator B
# -----------------------
optimizer_D_B.zero_grad()
# Real loss
loss_real = criterion_GAN(D_B(real_B), valid)
# Fake loss (on batch of previously generated samples)
fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
# Total loss
loss_D_B = (loss_real + loss_fake) / 2
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
2.3 starGAN(2018)
Pix2Pix模型解决了paired数据的图像翻译问题;CycleGAN解决了Unpaired数据下的图像翻译问题,但它们都是单领域的转换,而StarGAN则应用于多领域,即在同一种模型下做多个图像翻译任务,效果如下:

如下图所示,当多领域转换时,对于每一个领域转换,如果都需要重新训练一个模型去解决,这样的行为就太低效了,而StarGAN将多领域转换用统一框架实现。
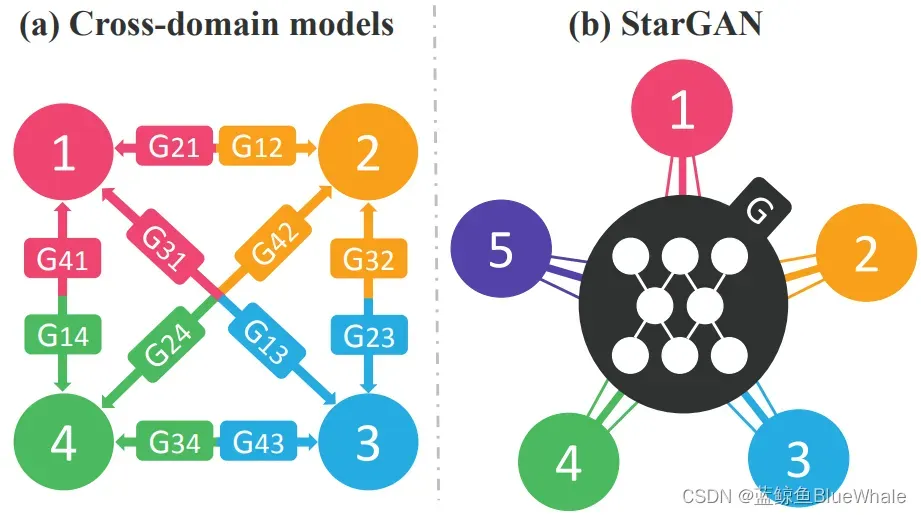
由于StarGAN时在多数据集下训练,而数据集之间有可能出现虽然类别不相交,但内容相交的情况。比如CelebA数据集合RaFD数据集,前者拥有肤色,年龄的类别。而后者拥有表情的类别。但前者的图像很多也是有表情的,这就导致前一类的图像在后一类的标记是不可知的。
为了解决这个问题,在模型输入中加入了Mask,即如果来源于数据集B,那么将数据集A中的标记全部设为0,示意图如下: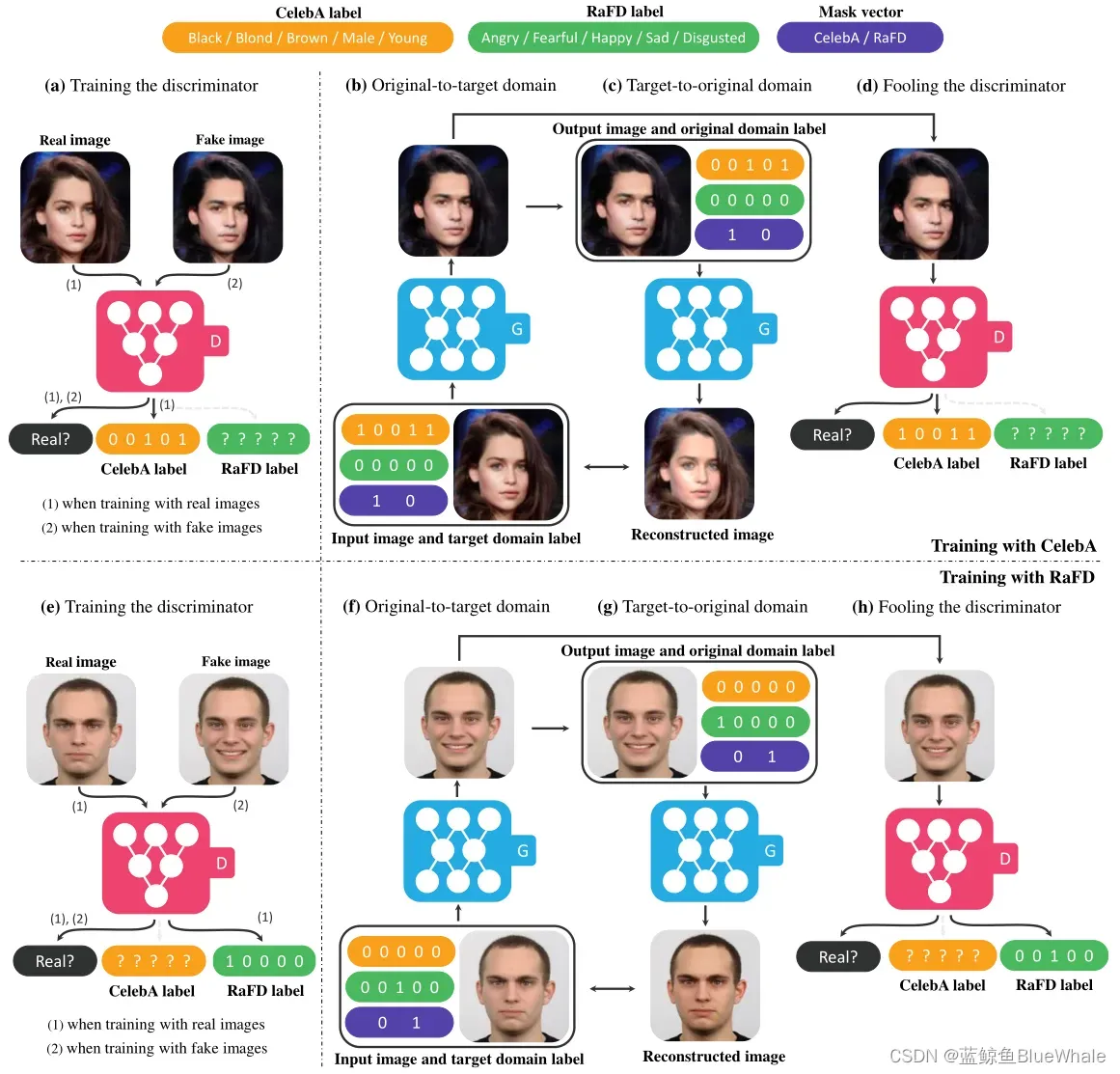
starGAN使用的损失函数如下:
- 防止损失
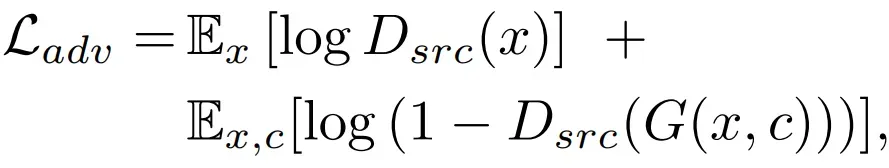
- D分类损失,使用真实图像在原始领域进行
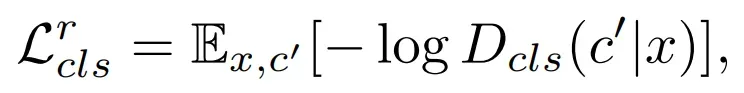
- G分类损失,使用生成图像在目标领域进行
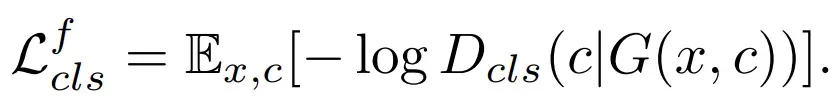
- 重建函数,与CycleGAN类似
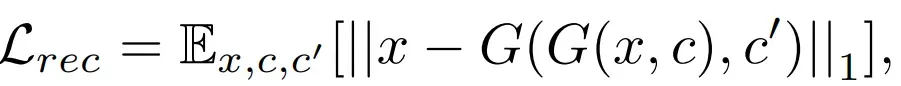
- 总体损耗
代码如下。表示多领域的方法主要在于加入了sampled_c。
for epoch in range(opt.epoch, opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
# Sample labels as generator inputs
sampled_c = Variable(Tensor(np.random.randint(0, 2, (imgs.size(0), c_dim))))
# Generate fake batch of images
fake_imgs = generator(imgs, sampled_c)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real images
real_validity, pred_cls = discriminator(imgs)
# Fake images
fake_validity, _ = discriminator(fake_imgs.detach())
# Gradient penalty
gradient_penalty = compute_gradient_penalty(discriminator, imgs.data, fake_imgs.data)
# Adversarial loss
loss_D_adv = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
# Classification loss
loss_D_cls = criterion_cls(pred_cls, labels)
# Total loss
loss_D = loss_D_adv + lambda_cls * loss_D_cls
loss_D.backward()
optimizer_D.step()
optimizer_G.zero_grad()
# Every n_critic times update generator
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
# Translate and reconstruct image
gen_imgs = generator(imgs, sampled_c)
recov_imgs = generator(gen_imgs, labels)
# Discriminator evaluates translated image
fake_validity, pred_cls = discriminator(gen_imgs)
# Adversarial loss
loss_G_adv = -torch.mean(fake_validity)
# Classification loss
loss_G_cls = criterion_cls(pred_cls, sampled_c)
# Reconstruction loss
loss_G_rec = criterion_cycle(recov_imgs, imgs)
# Total loss
loss_G = loss_G_adv + lambda_cls * loss_G_cls + lambda_rec * loss_G_rec
loss_G.backward()
optimizer_G.step()
2.4 SPADE(2019)
SPADE又名GauGAN,可以根据用户画的简单图像得到合成的实际图像,在合成时用户还可以选择合成图像的风格,得到非常多样的合成结果,如下图所示。
SPADE通过语义分割图生成原始图像,作者发现将语义分割图直接作为生成网络的输入进行计算时,这些生成网络中常用的传统BN层容易丢失输入语义图像中的信息, 因此提出了新的归一化层Spatially-Adaptive Normalization(SAN)来解决这个问题。
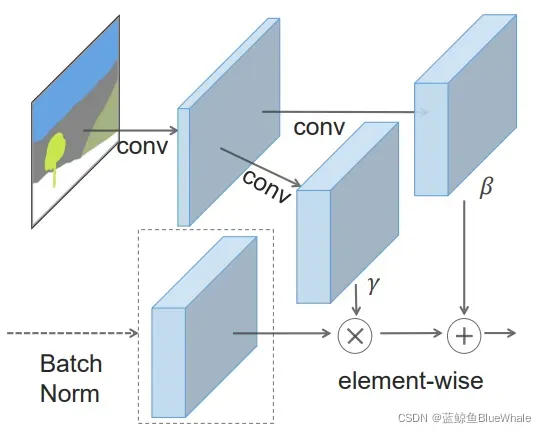
SAN是在BN的基础上做了修改,修改内容就在于γ和β计算的不同,如下图所示。在BN中和
的计算是通过网络训练得到的,而SAN中γ和β是通过语义图像计算得到的。
SAN的计算过程如下。在BN中,和
是向量一维的,其中每个值对应输入特征图的每个通道。而在SAN中,
和
是三维矩阵,除了通道维度外,还有宽和高维度,因此下式中
和
下标包含
三个符号,这也是spatially-adaptive的含义,翻译过来就是在空间上是有差异的,或者叫自适应的。而BN的
和
的下标只有
,也就是通道,这种不区分空间维度的计算方式就比较容易丢失输入图像的信息。
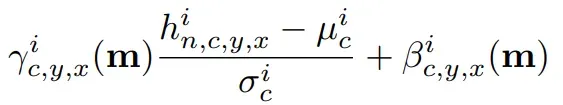
公式中的均值和标准差
的计算如下,这部分和BN中的计算一样。
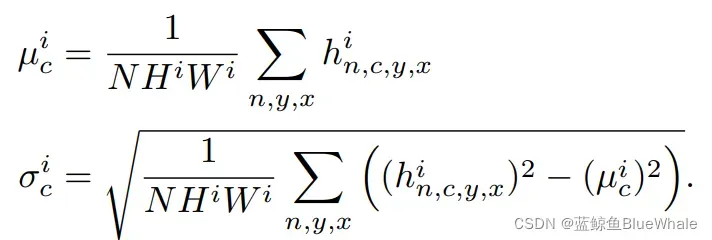
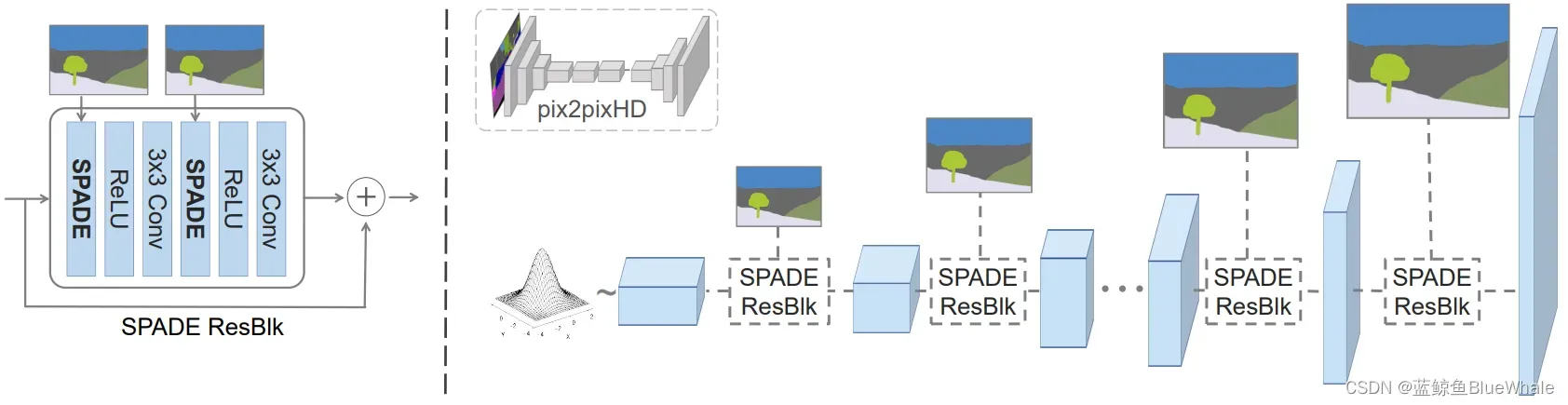
在网络结构方面,下图是SPADE算法中生成器的网络结构示意图,生成器采用堆叠多个SPADE ResBlk实现(右图),其中每个SPADE ResBlk的结构如左图所示,SAN层中的和
参数通过输入的语义图像计算得到。
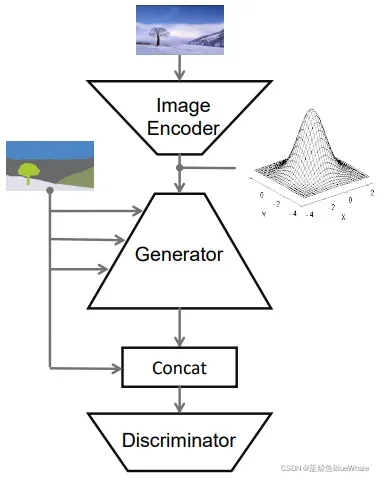
关于SPADE算法是如何实现多样化输出的。下图是SPADE算法的整体示意图,生成器的输入是一个向量,这个向量可以是随机值,这样生成的图像也是随机的;同样,这个向量也可以通过一个编码网络和一张风格图像计算得到,编码网络将输入图像编码成向量,这个向量就包含输入图像的风格,这样就能得到多样化风格输出的效果了。
参考:
- An Introduction to Image Synthesis with Generative Adversarial Nets
- DCGAN论文详解
- GAN在图像生成应用综述(论文解读)
- 完整code
- [GAN笔记] pix2pix
- 生成对抗网络系列(4)——pix2pix
- 深度学习《VAE-GAN》
- Understanding and Implementing CycleGAN in TensorFlow
- CycleGAN原理以及代码全解析
- CycleGAN算法原理
- StarGAN-多领域图像翻译
- 论文阅读-人脸生成_StyleGAN
- SPADE(GauGAN)算法笔记
版权声明:本文为博主蓝鲸鱼BlueWhale原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44579633/article/details/123223402