AIGC实战——WGAN
- 0. 前言
- 1. WGAN-GP
- 1.1 Wasserstein 损失
- 1.2 Lipschitz 约束
- 1.3 强制 Lipschitz 约束
- 1.4 梯度惩罚损失
- 1.5 训练 WGAN-GP
- 2. GAN 与 WGAN-GP 的关键区别
- 3. WGAN-GP 模型分析
- 小结
- 系列链接
0. 前言
原始的生成对抗网络 (Generative Adversarial Network, GAN) 在训练过程中面临着模式坍塌和梯度消失等问题,为了解决这些问题,研究人员提出了大量的关键技术以提高GAN模型的整体稳定性,并降低了上述问题出现的可能性。例如 WGAN (Wasserstein GAN) 和 WGAN-GP (Wasserstein GAN-Gradient Penalty) 等,通过对原始生成对抗网络 (Generative Adversarial Network, GAN) 框架进行了细微调整,就能够训练复杂GAN。在本节中,我们将学习 WGAN 与 WGAN-GP,两者都对原始 GAN 框架进行了细微调整,以改善图像生成过程的稳定性和质量。
1. WGAN-GP
WGAN (Wasserstein GAN) 是提高 GAN 训练稳定性方面的一次巨大进步,在经过一些简单改动后 GAN 就能够实现以下两个特点:
- 与生成器的收敛度和生成样本质量相关的损失度量
- 优化过程的稳定性得到提高
具体来说,WGAN 针对判别器和生成器提出了一种新的损失函数 (Wasserstein Loss),用这种损失函数代替二元交叉熵就可以让 GAN 的收敛更加稳定。
在本节中,我们将构建一个 WGAN-GP (Wasserstein GAN-Gradient Penalty),利用 CelebA 数据集训练模型以生成人脸图像。
1.1 Wasserstein 损失
首先我们来回顾一下二元交叉嫡, 在训练 DCGAN 判别器和生成器时采用了这种损失函数:
为了训练 GAN 的判别器 D,我们根据以下两者计算损失:真实图像的预测 与标签
之间的误差,以及生成图像的预测
与标签
之间的误差。因此,对于
GAN 的判别器来说,损失函数最小化的过程可以表示为:
为了训练 GAN 的生成器 G,我们根据生成图像的预测 与标签
的误差计算损失。因此,对于
GAN 的生成器来说,将损失函数最小化的过程可以表示为:
接下来,我们比较上述损失函数与 Wasserstein 损失函数。
Wasserstein 损失 (Wasserstein Loss) 是用于 Wasserstein GAN (WGAN) 的一种损失函数。与传统的二元交叉熵损失函数不同,Wasserstein 损失引入了标签 1 和 -1,将判别器的输出从概率值转变为分数 (score),因此,WGAN 的判别器通常也被称为评论家 (critic),并要求判别器是 1-Lipschitz 连续函数。
具体来说,Wasserstein 损失使用标签 和
代替
和
,同时还需要移除判别器最后一层的
Sigmoid激活函数,如此一来预测结果 就不一定在
范围内了,它可以是
范围内的任何值。
Wasserstein 损失的定义如下:
在训练 WGAN 的判别器 D 时,我们将计算以下损失:判别器对真实图像的预测 与标签
之间的误差,判别器对生成图像的预测
与标签
之间的误差。因此,对于
WGAN 判别器,最小化损失函数的过程可以表示为:
换句话说,WGAN 判别器试图最大化其对真实图像的预测和生成图像的预测之间的差异,且真实图像的得分更高。
而对于 WGAN 生成器 G 的训练,我们根据判别器对生成图像的预测 与标签
计算损失。因此,对于
WGAN 生成器,最小化损失函数可以表示为:
换句话说,WGAN 生成器试图生成被判别器以极高分数判定为真实图像的图像(即,令判别器认为它们是真实的)。
1.2 Lipschitz 约束
由于我们允许判别器输出 范围内的任意值,而不是按照
Sigmoid 函数那样将输出限制在 范围内,因此
Wasserstein 损失可能会非常大。因此,为了使 Wasserstein 损失函数正常工作,需要对判别器进行额外约束,即 1-Lipschitz 连续性约束。判别器是一个将图像转换为预测的函数 D,如果对于任意两个输人图像 和
,判别器函数
D 满足以下不等式,则该函数为 1-Lipschitz 连续:
其中, 表示两个图像的平均像素之差的绝对值,
表示判别器预测之间的绝对值。这意味着判别器的预测变化速率在任何情况下都是有界的(即梯度的绝对值不能大于
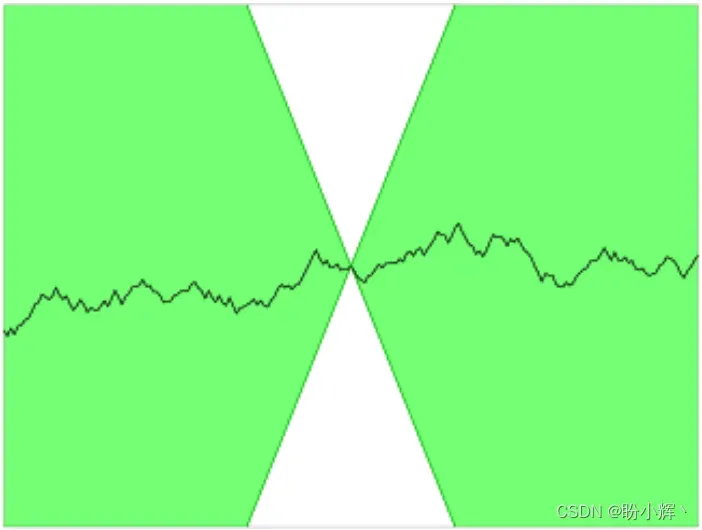
1)。可以在下图中的 Lipschitz 连续的一维函数中看到,无论将圆锥放在任何位置,曲线都不会进入圆锥内部。换句话说,曲线上任何一点的上升或下降速度都是有限的。
1.3 强制 Lipschitz 约束
在原始的 WGAN 论文中,作者通过在每个训练结束后将判别器的权重裁剪到一个较小范围内 来强制执行
Lipschitz 约束。
由于我们裁剪了判别器的权重,判别器的学习能力大大降低,因此,事实上,权重裁剪并不是一种理想的强制 Lipschitz 约束的方式。一个强大的判别器对于 WGAN 的成功至关重要,因为如果没有准确的梯度,生成器无法学习如何调整其权重以产生更好的样本。
因此,研究人员提出了许多其他方法来强制执行 Lipschitz 约束,并提高 WGAN 学习复杂特征的能力。其中一种方法是带有梯度惩罚 (Gradient Penalty) 的 Wasserstein GAN。
通过在判别器的损失函数中包含一个梯度惩罚项来直接强制执行 Lipschitz 约束,如果梯度范数偏离 1 时,该项会惩罚模型,从而使训练过程更加稳定。
接下来,将这个额外的梯度惩罚项加入到判别器损失函数中。
1.4 梯度惩罚损失
下图展示了 WGAN-GP 判别器的训练过程,与原始判别器的训练过程进行比较,我们可以看到关键的改进是将梯度惩罚损失作为整体损失函数的一部分,并与来自真实图像和生成图像的 Wasserstein 损失一起使用。
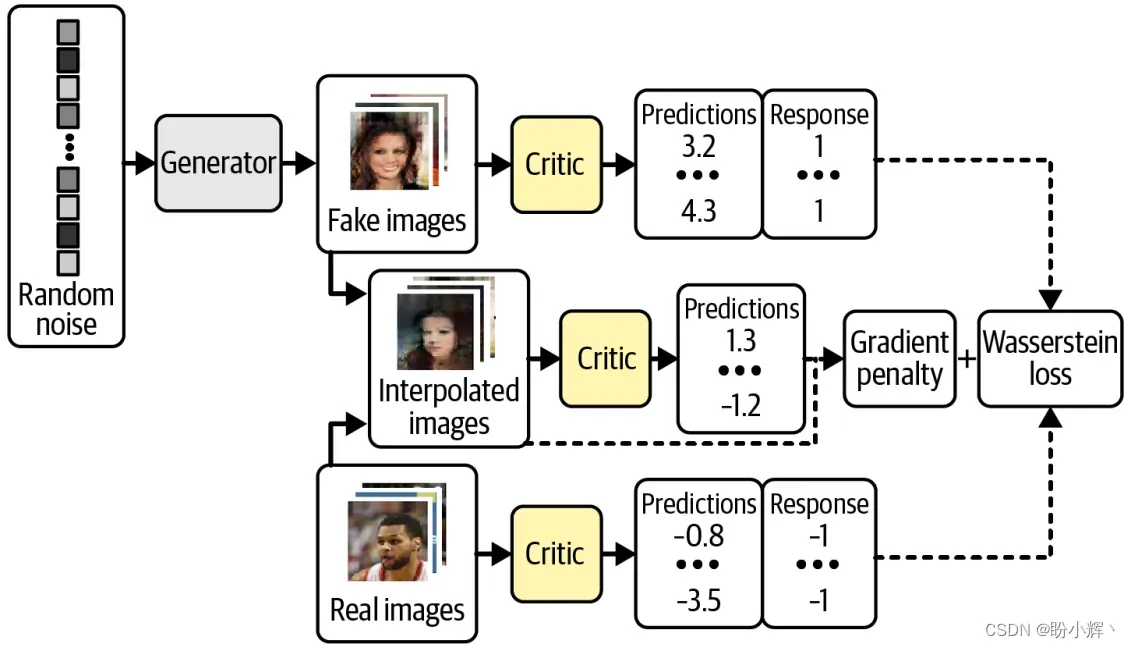
梯度惩罚损失衡量了预测关于输入图像的梯度范数与 1 之间的平方差。模型倾向于找到能够使梯度惩罚项最小化的权重,从而鼓励模型符合 Lipschitz 约束。
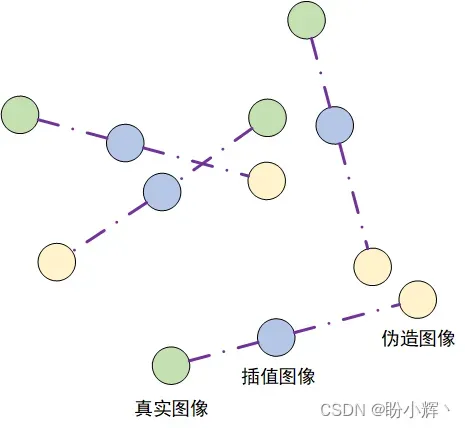
在训练过程中,每一处的计算梯度是非常困难的,因此WGAN-GP 只在少数几个点处评估梯度。为了确保平衡的,我们使用一组插值图像,在真实图像与伪造图像之间的随机位置逐像素进行插值 (Interpolation) 以生成一些图像。
使用 Keras 计算梯度惩罚项:
def gradient_penalty(self, batch_size, real_images, fake_images):
# 批数据中的每个图像都会得到一个 0~1 之间的随机数字,存储到向量 alpha 中
alpha = tf.random.normal([batch_size, 1, 1, 1], 0.0, 1.0)
# 计算一组插值图像
diff = fake_images - real_images
interpolated = real_images + alpha * diff
with tf.GradientTape() as gp_tape:
gp_tape.watch(interpolated)
# 使用判别器对每个插值图像进行评分
pred = self.critic(interpolated, training=True)
# 计算插值图像 (y_pred) 的预测对于输入 interpolated_samples) 的梯度
grads = gp_tape.gradient(pred, [interpolated])[0]
# 计算这个向量的 L2 范数(即欧几里得长度)
norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1, 2, 3]))
# 函数返回 L2 范数与 1 之差的平方的均值
gp = tf.reduce_mean((norm - 1.0) ** 2)
return gp
1.5 训练 WGAN-GP
使用 Wasserstein 损失函数的一个优点是,不再需要担心平衡判别器和生成器的训练。事实上,在使用 Wasserstein 损失时,必须在更新生成器之前将判别器训练到收敛,以确保生成器更新的梯度准确无误。这与标准 GAN 相反,标准 GAN 中重要的是不要让判别器变得过强。
因此,使用 Wasserstein GAN,我们可以简单地在生成器更新之间多次训练判别器,以确保它接近收敛。通常每次生成器更新一次,判别器更新三到五次。
了解了 WGAN-GP 的两个关键概念 (Wasserstein 损失和梯度惩罚项)后,使用 Keras 实现 WGAN-GP:
def train_step(self, real_images):
batch_size = tf.shape(real_images)[0]
# 对判别器进行三次更新
for i in range(self.critic_steps):
random_latent_vectors = tf.random.normal(
shape=(batch_size, self.latent_dim)
)
with tf.GradientTape() as tape:
fake_images = self.generator(
random_latent_vectors, training=True
)
fake_predictions = self.critic(fake_images, training=True)
real_predictions = self.critic(real_images, training=True)
# 计算判别器的 Wasserstein 损失
c_wass_loss = tf.reduce_mean(fake_predictions) - tf.reduce_mean(real_predictions)
# 计算梯度惩罚项
c_gp = self.gradient_penalty(batch_size, real_images, fake_images)
# 判别器损失函数是 Wasserstein 损失和梯度惩罚的加权和
c_loss = c_wass_loss + c_gp * self.gp_weight
c_gradient = tape.gradient(c_loss, self.critic.trainable_variables)
# 更新判别器的权重
self.c_optimizer.apply_gradients(
zip(c_gradient, self.critic.trainable_variables)
)
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
with tf.GradientTape() as tape:
fake_images = self.generator(random_latent_vectors, training=True)
fake_predictions = self.critic(fake_images, training=True)
# 计算生成器的 Wasserstein 损失
g_loss = -tf.reduce_mean(fake_predictions)
gen_gradient = tape.gradient(g_loss, self.generator.trainable_variables)
# 更新生成器的权重
self.g_optimizer.apply_gradients(
zip(gen_gradient, self.generator.trainable_variables)
)
self.c_loss_metric.update_state(c_loss)
self.c_wass_loss_metric.update_state(c_wass_loss)
self.c_gp_metric.update_state(c_gp)
self.g_loss_metric.update_state(g_loss)
return {m.name: m.result() for m in self.metrics}
在训练 WGAN-GP 之前,需要注意的最后一点是判别器不应该使用批量归一化。这是因为批归一化会在同一批图像之间创建相关性,从而使梯度惩罚损失的效果降低。实验证明,即使在判别器中没有批归一化, WGAN-GP 仍然可以输出出色的结果。
2. GAN 与 WGAN-GP 的关键区别
总而言之,标准 GAN 和 WGAN-GP 之间存在以下:
WGAN-GP使用Wasserstein损失WGAN-GP使用1表示真实图像标签,使用-1表示伪造图像的标签- 判别器的最后一层没有使用
sigmoid激活 - 在判别器的损失函数中包含梯度惩罚项
- 每训练一次生成器更新权重,需要多次训练判别器
- 判别器中没有批归一化层
3. WGAN-GP 模型分析
训练 25 个 epoch 后,WGAN-GP 模型的生成器能够生成合理图像:

该模型已经学习到了面部的重要高级特征,且没有出现模式坍塌的迹象。
如果我们将 WGAN-GP 的输出与变分自编码器 (Variational Autoencoder, VAE) 的输出进行比较,可以看到 WGAN-GP 生成的图像通常更清晰。总的来说,VAE 倾向于产生颜色边界模糊的图像,而 GAN 产生的图像更加清晰合理。GAN 通常比 VAE 更难训练,需要更长的时间才能获得满意的数据质量。
小结
在本节中,我们学习了如何使用 Wasserstein 损失函数以解决经典 GAN 训练过程中的模式坍塌和梯度消失等问题,使得 GAN 的训练更加可预测和可靠。WGAN-GP 通过在损失函数中添加一个令梯度范数指向 1 的项,为训练过程施加 1-Lipschitz 约束。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
文章出处登录后可见!