文章目录
主要解决问题
这篇文章主要是要解决如何降低调用大语言模型的成本(ChatGPT)。大模型API调用成本主要是三方面的:1. prompt cost(输入的prompt);2. generation cost(输出的部分);3. 每次调用的固定开销(网费等)。不用的模型之前的差异化收费也不一样,比如ChatGPT 10M的token需要30美金,但是如果是调用GPT-J的话,只需要0.2美金。
如何基于query的难易程度,来调用差异化的模型?如何将相似的问题存起来,减少模型的调用?等等一些手段都可以用来减少GPT的调用,减少成本。作者提出了三种策略来减少开销:
- prompt adaptation;
- LLM approximation;
- LLM cascade;
结论就是能够减少98%的花销,或者是相同花销下,提升4%的性能。
采用什么方法

Prompt adaptation
LLM的调用开销与query的大小呈线性递增,因此减小prompt的长度就是一个可以去减少开销的点。
-
prompt selections:选择合适的,需要的QA示例:

-
query concatenation:多个query一起发送给chatgpt:

LLM approximation
如果大语言模型的调用很贵,那么一个简单的想法就是去近似这个大语言模型。不管是completion cache,还是fine-tuning都是可以的。

LLM cascade
不同的LLM APIs都具有他们各自的强项和弱项。
LLM cascade中两个比较关键的地方是:1. scoring function;2. LLM router。

在论文中,作者是采用DistiBERT去作为这个 scoring function。LLM router就是作者非常建议的设定这些阈值和顺序。当然这个也可以用大模型中的Reward Model去评分。
LLM的多样性同时会使得最终的性能有所提升,贵的LLM APIs也不一定见地好。
实验结论
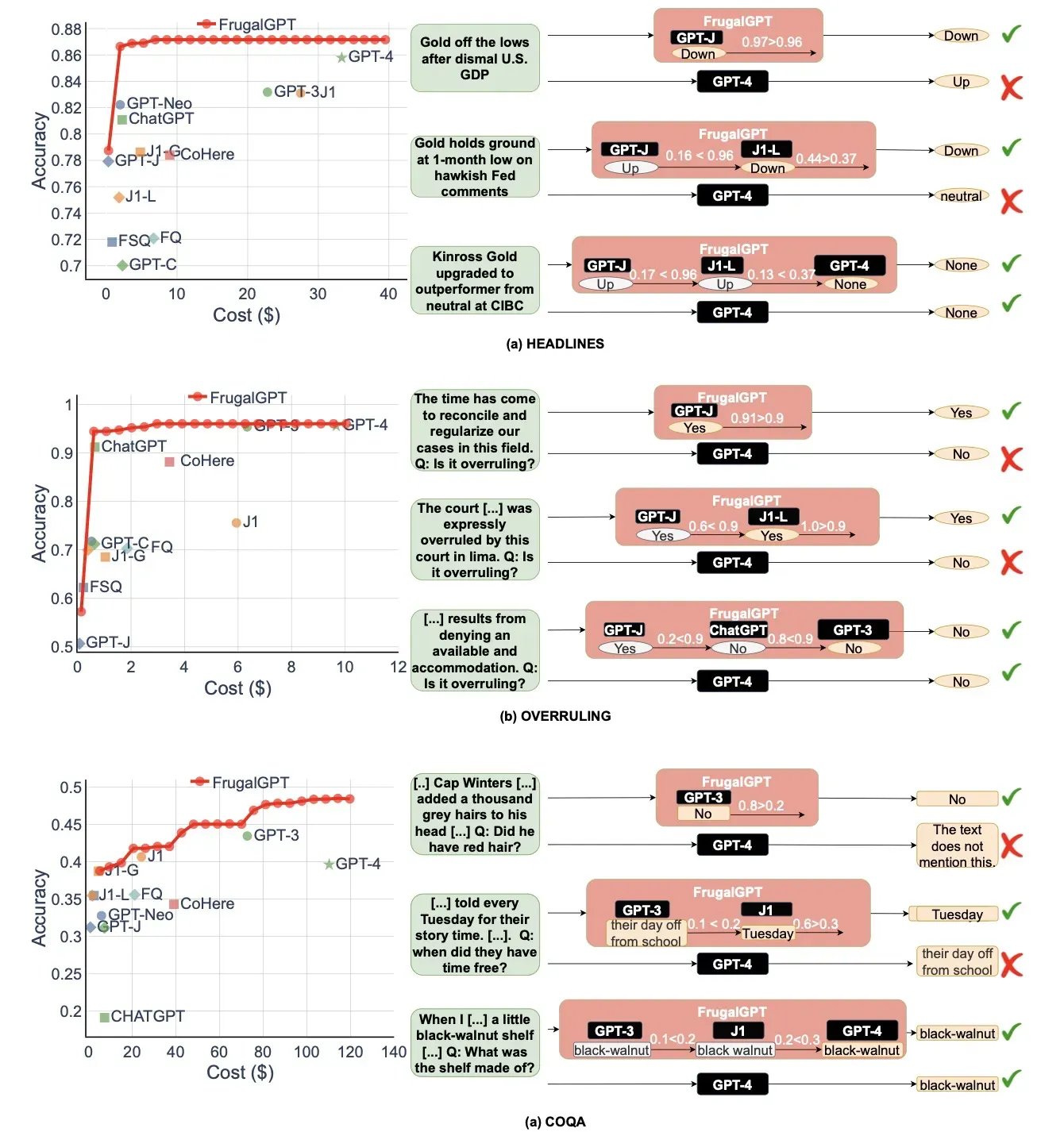
作者在一些特定的数据集上面做了实验,以下是一些Cost和Acc的曲线图。可以看到很少的钱就能够达到较为不错的效果。
讨论与展望
这里很重要的一点,时间开销作者这里并没有讨论。尤其是LLM cascade这块,如果前两次调用失败,那时间开销就比较长了。当然还有一些问题是LLM商业化应用的共性问题,安全,隐私,伦理,不确定性等等。
文章出处登录后可见!