1. 大模型的挑战
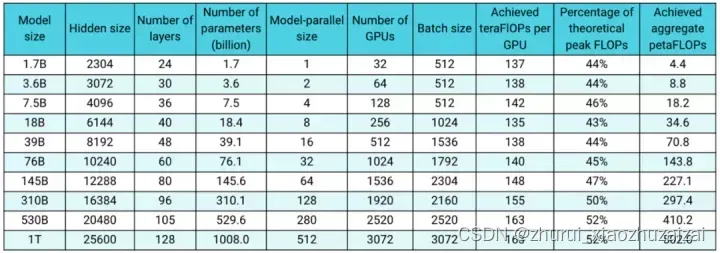
GPT-3 175B模型的参数如下:
网络层(Number of layers): 96
句子长度(Sequence length): 2048
隐藏层大小(Hidden layer size): 12288
词汇表(Vocabulary size):51200
总参数量:约175B
1.1 对显存的挑战
175B的模型,一个原生没有经过优化的框架执行,各部分大概需要的显存空间:
模型参数:700 GB (175B * 4bytes)
参数对应的梯度:700 GB
优化器状态:1400 GB
所以,一个175B模型共需要大概2.8 TB的显存空间,这对 GPU 显存是巨大的挑战:
1)模型在单卡、单机上存放不下。以NVIDIA A10080GB为例,存放此模型需要超过35块。
2) 必须使用模型并行,并且需要跨机器。主流的A100 服务器是单机八卡,需要在多台机器之间做模型切分。
1.2 对计算的挑战
基于Transformer 架构的模型计算量主要来自于Transformer层和 logit 层里的矩阵乘,可以得出每个迭代步大致需要的计算量:
B: 批大小,S:句子长度,l:Transformer 层数,h:隐藏层大小,V:词汇表大小
这是真实计算量的一个下限,但已是非常接近真实的计算量。关于此公式的详细说明,请参考 NVIDIA Paper(https://arxiv.org/abs/2104.04473)里的附录章节。
其中S=2048, l=96, h=12288, V=51200,在我们的实践中,B = 1536,一共需要迭代大约95000次。代入这次参数到上述公式,可以得到:
一次迭代的计算量:4.5 ExaFLOPS.
完整训练的计算量:430 ZettaFLOPS (~95K 次迭代)
这是一个巨大的计算量,以最新的NVIDIA A100的FP16计算能力 312 TFLOPS来计算,即使不考虑计算效率和扩展性的情况,需要大概16K A100*days的计算量。直观可以理解为16000块A100一天的计算量,或者一块A100 跑43.8年的计算量。
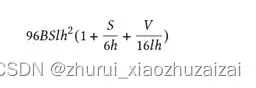
1.3 对通信的挑战
训练过程中GPU之间需要频繁的通信,这些通信源于模型并行和数据并行的应用,而不同的并行划分策略产生的通信模式和通信量不尽相同。
对于数据并行来说,通信发生在后向传播,用于梯度通信,通信类型为AllReduce,每次后向传播中的通信量为每个GPU上的模型大小。
对于模型并行来说,稍微复杂些。模型并行通常有横切和竖切两种,比如把一个模型按网络层从左到右横着摆放,横切即把每个网络层切成多份(Intra-layer),每个GPU上计算网络层的不同切块,也称为Tensor(张量)模型并行。竖切即把不同的网络层切开(Inter-layer),每个GPU上计算不同的网络层,也称为Pipeline (流水线)模型并行。
模型并行切分:上图为Pipeline模型并行切分,下图为Tensor模型并行切分
对于Tensor模型并行,通信发生在每层的前向和后向传播,通信类型为AllReduce,通信频繁且通信量比较大。
对于Pipeline 模型并行,通信发生在相邻的切分点,通信类型主要为P2P,每次通信数据量比较少但比较频繁,而且会引入额外的GPU 空闲等待时间。

2 目前的一些解决方式
- 分布式并行加速:
并行训练主要分为数据并行、模型并行、流水线并行、张量并行四种并行方式,通过上述四种主要的分布式并行策略来作为大模型训练并行的主要策略。- 算法模型架构:
大模型训练离不开Transformer网络模型结构的提出,后来到了万亿级稀疏场景中经常遇到专家混合模型MoE都是大模型离不开的新算法模型结构。- 内存和计算优化:
关于内存优化技术主要由激活Activation重计算、内存高效的优化器、模型压缩,而计算优化则集中体现在混合精度训练、算子融合、梯度累加等技术上。
Horovod、Tensorflow Estimator、PyTorch DDP等支持数据并行,
Gpipe、PipeDream、PipeMare等支持流水并行,
Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分
总训练速度 ∝ 单卡速度 * 加速芯片数量 * 多卡加速比
- 单卡速度
单卡速度既然是运算速度和数据IO的快慢来决定,那么就需要对单卡训练进行优化,于是主要的技术手段有精度训练、算子融合、梯度累加来加快单卡的训练性能。- 加速芯片数量
理论上,AI芯片数量越多,模型训练越快。但是,随着训练数据集规模的进一步增长,加速比的增长并不明显。如数据并行就会出现局限性,当训练资源扩大到一定规模时,由于通信瓶颈的存在,增加计算资源的边际效应并明显,甚至增加资源也没办法进行加速。这时候需要通讯拓扑进行优化,例如通过ring-all-reduce的通讯方式来优化训练模式。- 多卡加速比
多卡加速比既然由计算、通讯效率决定,那么就需要结合算法和集群中的网络拓扑一起优化,于是有了数据并行DP、模型并行MP、流水线并行PP相互结合的多维度混合并行策略,来增加多卡训练的效率。
目前最流行的模式有两种:
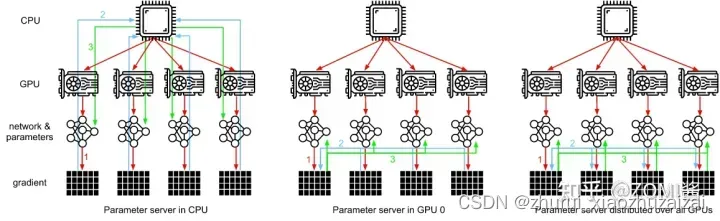
- 参数服务器模式(Parameter Server,PS)
- 集合通讯模式(Collective Communication,CC)
其中参数服务器主要是有一个或者多个中心节点,这些节点称为PS节点,用于聚合参数和管理模型参数。而集合通信则没有管理模型参数的中心节点,每个节点都是 Worker,每个Worker负责模型训练的同时,还需要掌握当前最新的全局梯度信息。
参数服务器架构Parameter Server,
PS架构包括两个部分,首先是把计算资源分为两个部分,参数服务器节点和工作节点:
1)参数服务器节点用来存储参数;
2)工作节点部分用来做算法的训练。
第二个部分就是把机器学习算法也分成两个方面,即1)参数和2)训练。
如图所示,PS架构将计算节点分为server与worker,其中,worker用于执行网络模型的前向与反向计算。而server则对各个worker发回的梯度进行合并并更新模型参数,对深度学习模型参数中心化管理的方式,非常易于存储超大规模模型参数。
但是随着模型网络越来越复杂,对算力要求越来越高,在数据量不变的情况下,单个GPU的计算时间是有差异的,并且网络带宽之间并不平衡,会存在部分GPU计算得比较快,部分GPU计算得比较慢。这个时候如果使用异步更新网络模型的参数,会导致优化器相关的参数更新出现错乱。而使用同步更新则会出现阻塞等待网络参数同步的问题。
GPU 强大的算力毋庸置疑可以提升集群的计算性能,但随之而来的是,不仅模型规模会受到机器显存和内存的制约,而且通信带宽也会由于集群网卡数量降低而成为瓶颈。
这个时候百度基于PS架构之上提出了Ring-All-Reduce新的通讯架构方式。
如图所示,通过异步流水线执行机制,隐蔽了 IO 带来的额外性能开销,在保证训练速度的同时,使训练的模型大小不再受制于显存和内存,极大提升模型的规模。而 RPC&NCCL 混合通信策略可以将部分稀疏参数采用 RPC 协议跨节点通信,其余参数采用卡间 NCCL 方式完成通信,充分利用带宽资源。
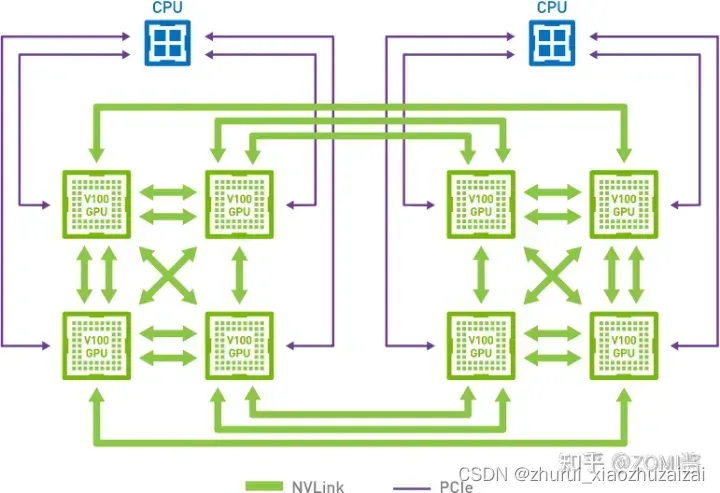
集合通讯模式(Collective Communication,CC),
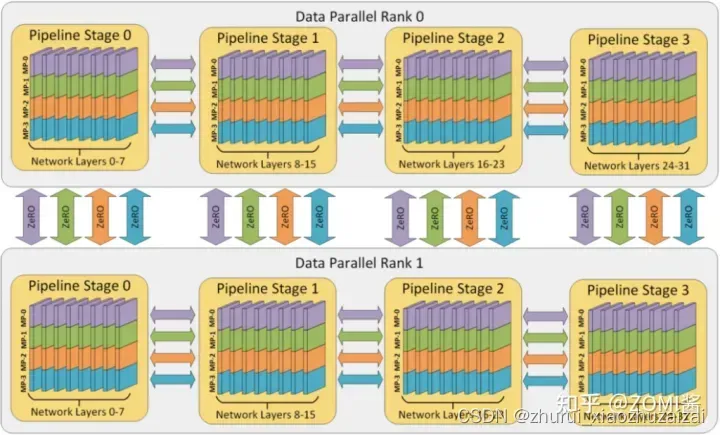
2.1 NVIDIA Megatron
优化的分布式框架NVIDIA Megatron和优化的分布式集群架构NVIDIA DGX SuperPOD
NVIDIA Megatron 是一个基于 PyTorch 的框架,用于训练基于 Transformer 架构的巨型语言模型
资料链接:
NVIDIA Megatron:超大Transformer语言模型的分布式训练框架 (一)
NVIDIA Megatron:超大Transformer语言模型的分布式训练框架 (二)
Megatron repro: https://github.com/nvidia/megatron-lm
GPT3-175B training scripts: https://link.zhihu.com/?target=https%3A//github.com/NVIDIA/Megatron-LM/blob/main/examples/pretrain_gpt3_175B.sh
2.2 DeepSpeed
Pytorch的分布式并行计算框架(Distributed Data Parallel,简称DDP),它也仅仅是能将数据并行,放到各个GPU的模型上进行训练。
DeepSpeed,它就能实现这个拆散功能,它通过将模型参数拆散分布到各个GPU上,以实现大型模型的计算,弥补了DDP的缺点,非常方便,这也就意味着我们能用更少的GPU训练更大的模型,而且不受限于显存。
介绍:大规模深度学习框架 DeepSpeed 使用指南
DeepSpeed 是一个深度学习优化库,它使分布式训练变得容易、高效和有效。
DeepSpeed为所有人提供了极端规模的模型训练,从在大型超级计算机上进行训练到在低端群集甚至在单个GPU上进行训练的人员:
极端规模:将当前的GPU群集与数百种设备结合使用,实现3D并行 DeepSpeed 可以有效地训练具有数万亿参数的深度学习模型。
极高的内存效率:DeepSpeed 的ZeRO-Offload 仅需一个 GPU,即可训练超过10B参数的模型,比现有技术大10倍,使数十亿参数的模型训练民主化,从而使许多深度学习科学家可以探索更大更好的模型。
pip install deepspeed
Github 链接 https://github.com/microsoft/DeepSpeed

2.3 Elephas
Elephas 是 Keras 的扩展,它可以使用 Spark 大规模运行分布式深度学习模型。 Elephas 保持了 Keras 的简单性和高可用性,从而允许对分布式模型进行快速原型制作,该模型可以在海量数据集上运行。 Elephas 当前支持许多应用程序,包括:深度学习模型的数据并行训练分布式超参数优化集成模型的分布式训练。
安装 pip install elephas
Github 链接https://github.com/maxpumperla/elephas
2.4 FairScale
FairScale 是 PyTorch 扩展库,用于在一台或多台机器/节点上进行高性能和大规模培训。该库扩展了基本的PyTorch功能,同时添加了新的实验功能。
FairScale支持:并行、分片训练、大规模优化、GPU内存优化、GPU速度优化
安装pip install fairscale
Github 链接https://github.com/facebookresearch/fairscale
2.5 TensorFlowOnSpark
通过将TensorFlow深度学习框架中的突出功能与Apache Spark和Apache Hadoop相结合,TensorFlowOnSpark可以在GPU和CPU服务器集群上实现分布式深度学习。
它支持在Spark集群上进行分布式TensorFlow训练和推理,其目标是最大程度地减少在共享网格上运行现有TensorFlow程序所需的代码更改量。
TensorFlowOnSpark由Yahoo开发,用于在Yahoo私有云中的Hadoop集群上进行大规模分布式深度学习。
安装【 for tensorflow>=2.0.0】 pip install tensorflowonspark
【 for tensorflow<2.0.0】 pip install tensorflowonspark==1.4.4
Github 链接 https://github.com/yahoo/TensorFlowOnSpark
2.6 Horovod
Horovod 是一个针对TensorFlow,Keras,PyTorch和Apache MXNet的分布式深度学习训练框架。
参考资料:分布式训练框架Horovod(一):基本概念和核心卖点
深度学习分布式训练框架 horovod – 弹性训练总体架构
2.7 veGiantModel
火山引擎:基于 Megatron和DeepSpeed
github:https://github.com/volcengine/veGiantModel
文章出处登录后可见!