yolov7训练自己的数据集
- 前言
- 一、下载整个项目
- 通过git 下载
- 或者直接下载压缩包
- 二、安装所需环境
- 三、准备数据集
- 四、配置文件
- 五、下载权重文件
- 六、开始训练
- 七、推理
- 附录:遇到的问题
前言
继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。
YOLOV7主要的贡献在于:
1.
模型重参数化
YOLOV7将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中。
2.标签分配策略
YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略。
3.ELAN高效网络架构
YOLOV7中提出的一个新的网络架构,以高效为主。
4.带辅助头的训练
YOLOV7提出了辅助头的一个训练方法,主要目的是通过增加训练成本,提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中。
一、下载整个项目
通过git 下载
git clone https://github.com/WongKinYiu/yolov7.git
或者直接下载压缩包
二、安装所需环境
建议使用conda虚拟环境
conda create --name yolov7_env python=3.7
conda activate yolov7_env
pip install -r requirements.txt
三、准备数据集
生成训练、验证的TXT文件:
import os
def get_txtdata(path):
VOCdevkit_path = path
file_names = os.listdir(VOCdevkit_path+"/images")
train_num = 400
train_path = os.path.join(VOCdevkit_path,'train.txt')
val_path = os.path.join(VOCdevkit_path,'val.txt')
train_file = open(train_path, 'w')
val_file = open(val_path, 'w')
for name in file_names[0:train_num]:
img_path = os.path.join(VOCdevkit_path+"/Images",name)
train_file.write(img_path + '\n')
train_file.close()
for name in file_names[train_num:]:
img_path = os.path.join(VOCdevkit_path+"/Images",name)
val_file.write(img_path + '\n')
val_file.close()
if __name__=="__main__":
VOCdevkit_path = 'dataset2'
get_txtdata(VOCdevkit_path)
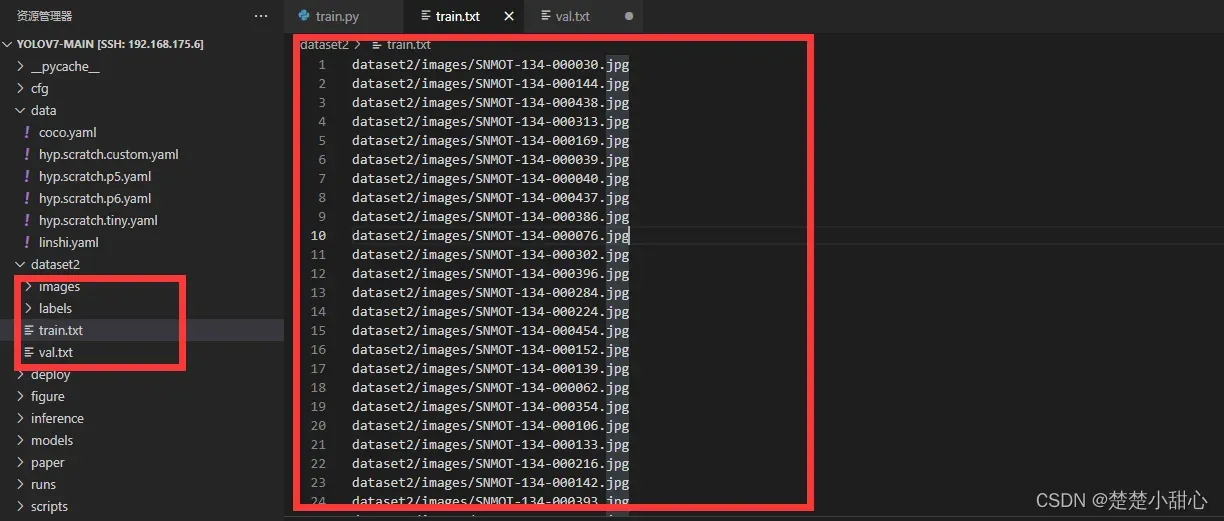
如图所示:
images:图片文件
labels:标签文件
train.txt:训练数据集的位置
val.txt:验证数据集的位置
四、配置文件
在data目录下新建一个yaml配置文件,按如图所示格式输入自己训练数据的信息
name:类别名字
nc:类别数量
train:训练集文件位置
val:验证集文件位置
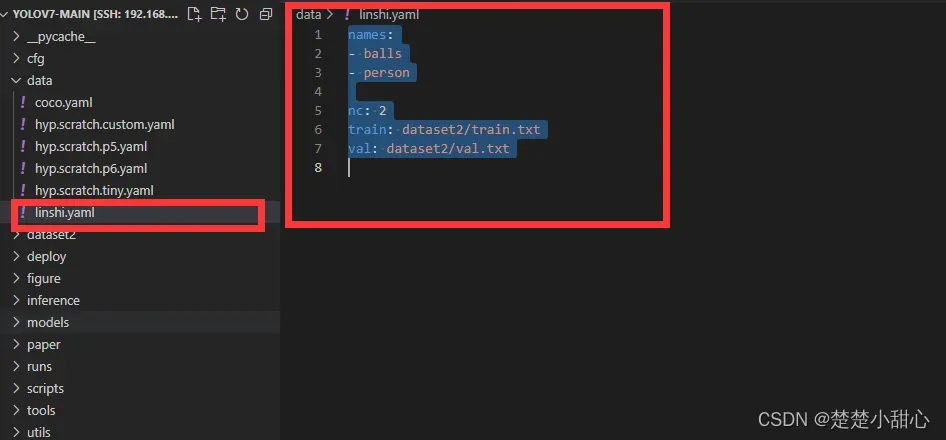
names:
- balls
- person
nc: 2
train: dataset2/train.txt
val: dataset2/val.txt
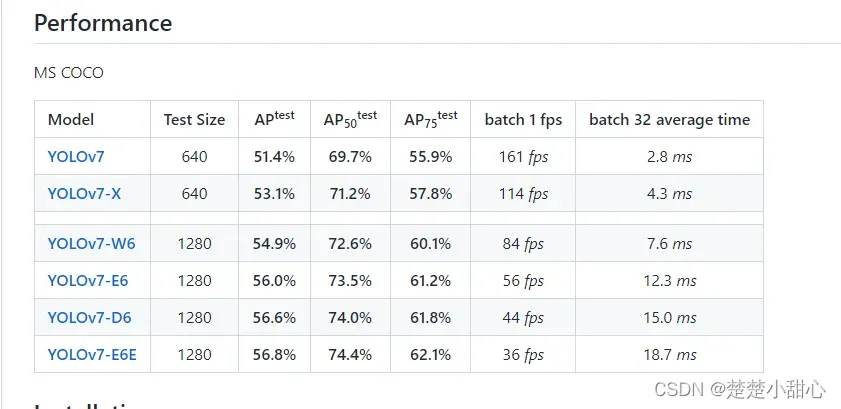
五、下载权重文件
如下图所示,官网下载,但是速度会比较慢。
项目已经上传到网盘,可以通过网盘下载(链接在评论中)。
六、开始训练
修改模型名字和配置文件位置
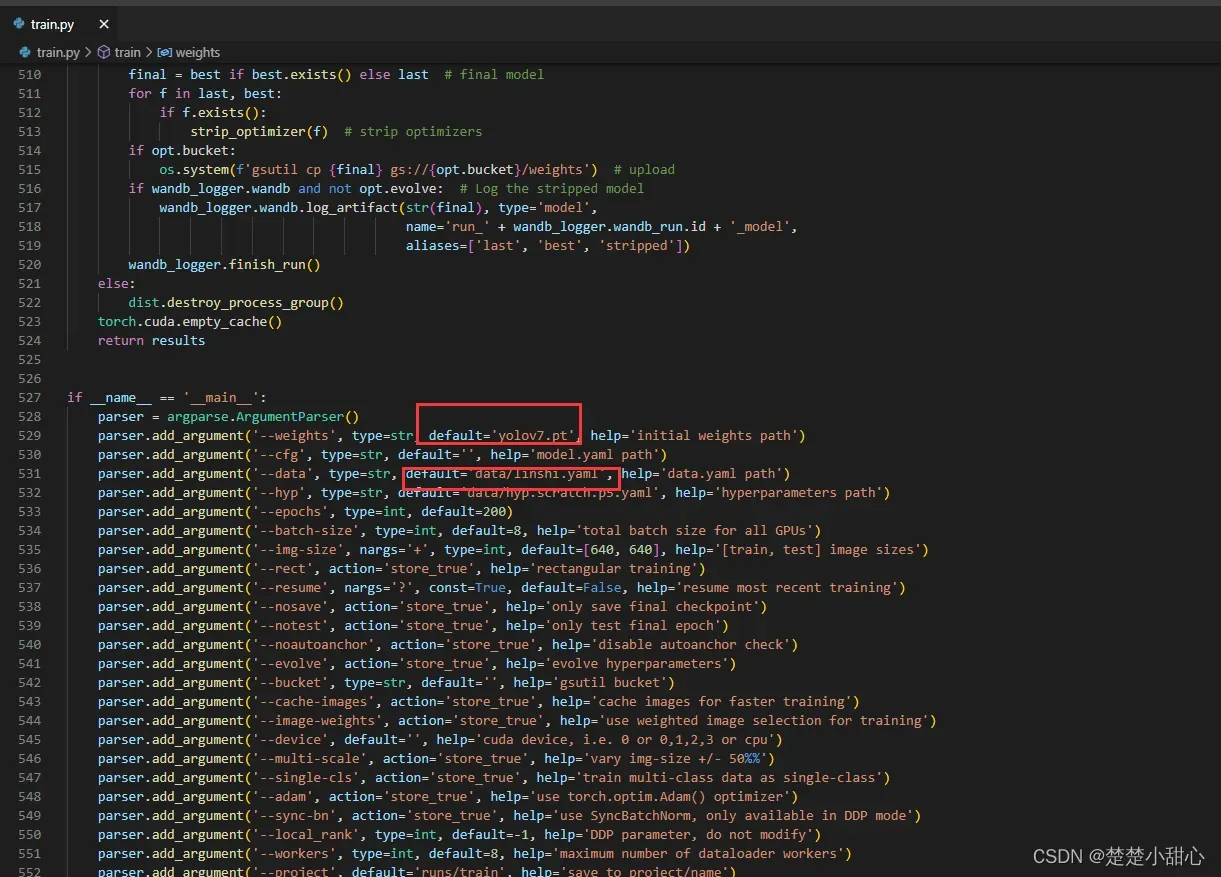
python3 train.py
七、推理
模型路径和图片路径需要换成自己的
python3 detect.py

附录:遇到的问题
运行train.py的时候报错
subprocess.CalledProcessError: Command 'git tag' returned non-zero exit status 128.
解决:
这是由于网络波动或者防火墙无法连接到github下载权重文件。
手动下载权重文件,并修改名字yolo7.pt–>yolov7.pt
parser.add_argument('--weights', type=str, default='yolov7.pt', help='initial weights path')
文章出处登录后可见!
已经登录?立即刷新