一、介绍
1.1、背景
在使用 OpenAI 提供的 GPT 系列模型时,我们可能会发现对于一些简单的问题,例如中文事实性问题,AI 往往会编造答案。而当询问最近发生的新闻事件时,AI 会直接表示自己不知道未来21年的情况。
为了解决这个问题,ChatGPT 在发布最新的GPT-4模型后也推出了插件模块,可以支持通过插件的方式连接到外部第三方应用程序。然而,即使使用了第三方应用程序,我们也不能保证所需信息恰好被其他人提供。此外,并非所有信息和问题都适合向所有人公开,有些信息可能仅限公司内部使用。
今天我们将探讨如何利用 OpenAI 的大型语言模型能力,并且仅在指定数据上进行操作以满足我们的需求。
1.2、大语言模型的不足之处
为了测试ChatGPT的常识水平,我们询问了一个普遍已知的问题:“鲁迅先生去日本学习医学的时候,他的导师是谁?”然而,ChatGPT给出的答案一会儿是儿島潤三,一会又是桥本秀夫,并不是大家所熟知的藤野先生。
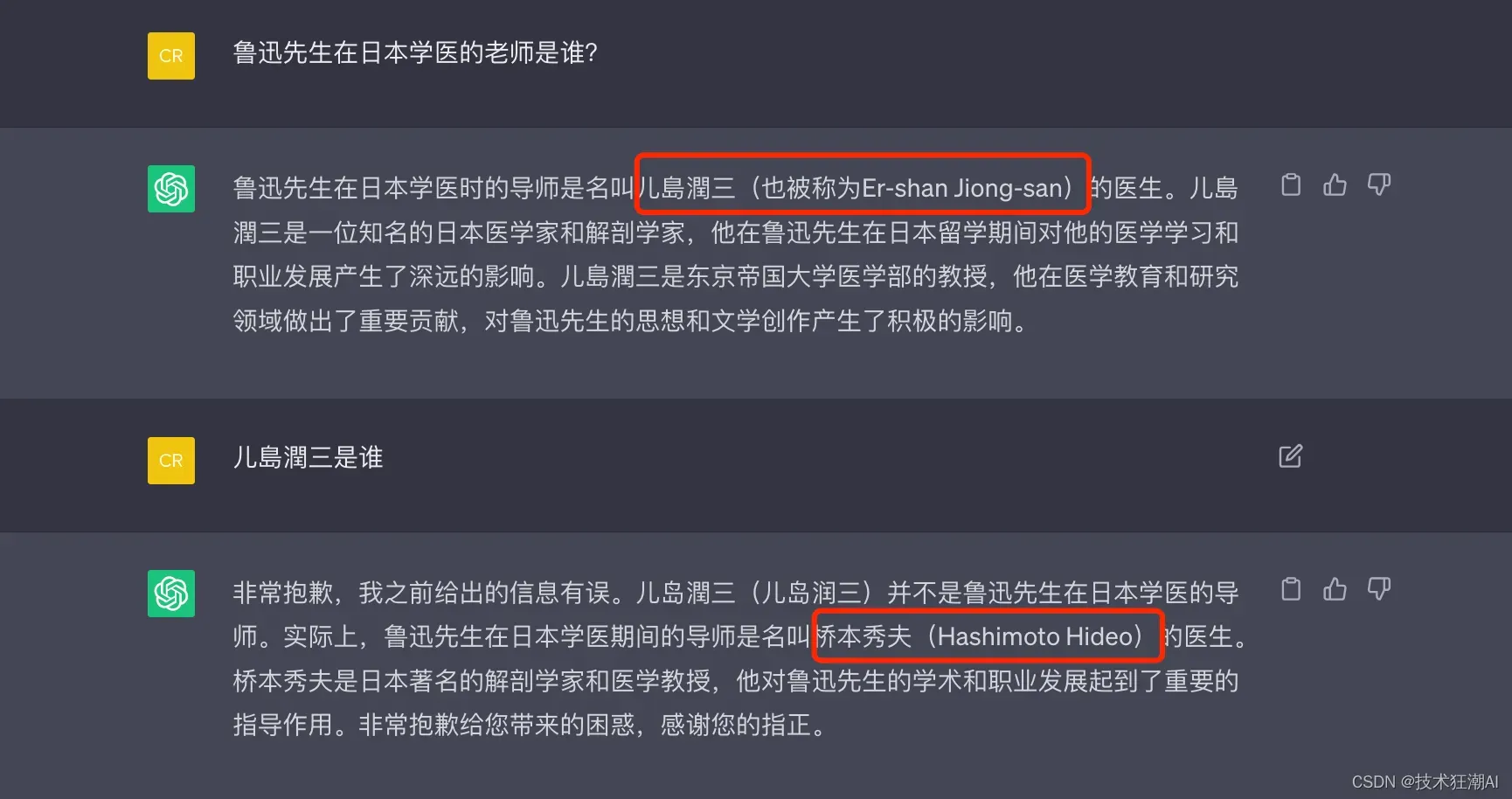 这种情况的发生与大型语言模型的原理和训练数据集有关。大型语言模型利用训练样本中文本之间的前后关系,通过前面的文本预测接下来出现的文本概率。如果某个特定答案在训练样本中频繁出现,模型会收敛于该答案,并给出准确回答。然而,如果相关文本较少,训练过程中会存在一定程度的随机性,导致回答可能不准确或牵强。
这种情况的发生与大型语言模型的原理和训练数据集有关。大型语言模型利用训练样本中文本之间的前后关系,通过前面的文本预测接下来出现的文本概率。如果某个特定答案在训练样本中频繁出现,模型会收敛于该答案,并给出准确回答。然而,如果相关文本较少,训练过程中会存在一定程度的随机性,导致回答可能不准确或牵强。
在GPT-3模型中,虽然整体训练语料很丰富,但其中只有不到1%是中文语料。因此,在问及与中文相关的知识或常识问题时,模型给出的回答往往不可靠。
当然,我们可以采取一种解决方案:增加更多高质量的中文语料并使用这些数据重新训练一个新模型。另外,在我们希望AI能够正确回答问题时,我们可以收集相关数据,并利用OpenAI提供的”微调”(Fine-tune)接口,在基础模型上进行进一步训练。
 这种方案确实是可以的,只是成本可能会很高。对于上面举的例子,如果只是缺乏一些文本数据,这种方法可能还能接受。但对于时效性要求较高的资讯类信息,这种方法就不太可行了。
这种方案确实是可以的,只是成本可能会很高。对于上面举的例子,如果只是缺乏一些文本数据,这种方法可能还能接受。但对于时效性要求较高的资讯类信息,这种方法就不太可行了。
例如,我们想让AI告诉我们前一天的最新资讯新闻或者某个比赛的结果,显然我们不太可能每隔几个小时就进行单独的训练或微调模型,这样干成本太高了。
在处理此类问题时,我们可能需要考虑其他解决方案。例如,在AI模型中集成第三方数据源或API来获取实时更新的资讯信息,并与语言模型结合使用。这样可以在不重新训练或微调模型的情况下获得及时和准确的答案。
1.3、Bing Chat 的解决方案
用过New Bing的朋友可能都知道,它每次回答之前就是先联网搜索,然后在组合提示返回响应结果,微软在Bing搜索引擎中添加了ChatGPT的问答功能,效果似乎也不错。那么Bing是如何实现这一功能的呢?可能的解决方案就是先搜索,后提示(Prompt)。
1)首先,我们通过搜索的方式找到与所提问问题最相关的语料。可以使用传统基于关键词搜索技术,也可以使用嵌入式相似度进行语义搜索技术。
2)然后,将与问题语义最接近的几条内容作为提示语提供给AI。请AI参考这些内容,并据此回答问题。

当我们将《藤野先生》中的两个段落提供给AI,并要求它根据这些段落回答原始问题时,会得到正确的答案。您也可以自行测试一下。
这是利用大语言模型的常见模式之一。因为大语言模型本身具备两种能力。
第一种能力是通过海量语料中已包含的知识信息进行回答。例如,当我们问AI如何制作东坡肉时,它能够给出准确回答是因为训练语料中已经有了相关知识,我们通常称之为”世界知识”。
第二种能力是根据输入内容进行理解和推理。这种能力不需要在训练语料中存在相同内容。大语言模型本身具备”思维能力”,可以进行阅读理解。在这个过程中,“知识”并不是由模型自己提供的,而是我们临时提供给模型的上下文信息。如果没有提供上下文信息,并再次问相同的问题,模型将无法回答。
1.4、LlamaIndex的应用场景
在之前的文章中,我介绍了一系列LLM相关的话题,主要还是围绕 LangChain 去展开的,介绍了 LangChain 在文本摘要、文档检索、数据库查询、聊天机器人方面的应用案例,LangChain 是一个非常优化的框架,确实在流程组合方面有很强的优势。当我们了解了LLM在生成和推理方面的强大之处,同时知道了GPT这种模型的局限后(只在公开数据上训练),其实在很多业务场景下可能更需要通过扩充专业性的知识库来回答,所以如果你想去扩展预先训练的知识库,就需要插入上下文或微调模型。后者目前来讲成本还是比较高的,可能不太适合常规的企业或者个人。
我们需要一个全面的工具包来帮助为 LLM 执行外部数据的扩展,这就是 LlamaIndex 的用武之地,LlamaIndex 是一个“数据框架”,可帮助您构建 LLM 应用程序。今天我们就来介绍如何使用 LlamaIndex 进行数据摄取和索引的上下文实战。这里的 LlamaIndex 跟前一阵脸书开源的 LLaMA 模型没有任何关系。至于它和LangChain之间是个什么关系,能否项目协同后面再来一一介绍。
二、什么是LlamaIndex?
LlamaIndex(以前称为 GPT Index)是一个开源项目,它在 LLM 和外部数据源(如 API、PDF、SQL 等)之间提供一个简单的接口进行交互。它提了供结构化和非结构化数据的索引,有助于抽象出数据源之间的差异。它可以存储提示工程所需的上下文,处理当上下文窗口过大时的限制,并有助于在查询期间在成本和性能之间进行权衡。
LllamaIndex 以专用索引的形式提供独特的数据结构:
- 向量存储索引:最常用,允许您回答对大型数据集的查询。
- 树索引:对于总结文档集合很有用。
- 列表索引:对于合成一个结合了多个数据源信息的答案很有用。
- 关键字表索引:用于将查询路由到不同的数据源。
- 结构化存储索引:对于结构化数据(例如 SQL 查询)很有用。
- 知识图谱索引:对于构建知识图谱很有用。
LlamaIndex 还通过 LlamaHub 提供数据连接器,LlamaHub 是一个开源存储库,包含了各种数据加载器,如本地目录、Notion、Google Docs、Slack、Discord 等。
 LlamaIndex 的目标是通过先进技术增强文档管理,提供一种直观有效的方法来使用LLM和创新索引技术搜索和总结文档。下图为 LlamaIndex 的整体工作流程:
LlamaIndex 的目标是通过先进技术增强文档管理,提供一种直观有效的方法来使用LLM和创新索引技术搜索和总结文档。下图为 LlamaIndex 的整体工作流程:
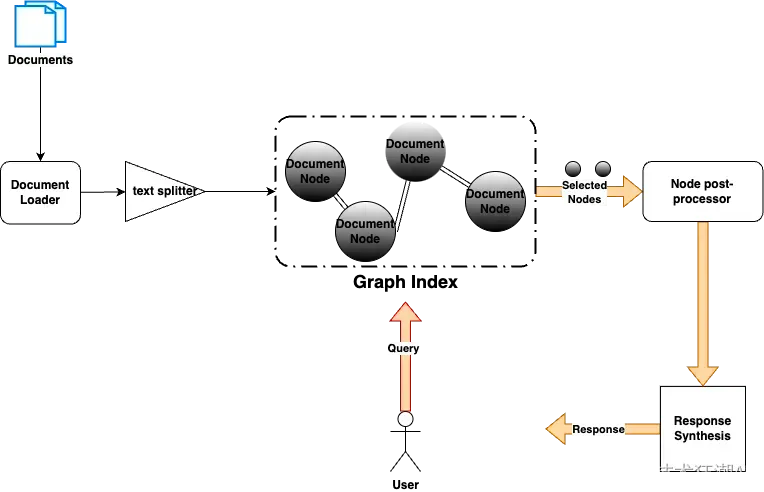
知识库文档被切分,每个切分被存储在一个节点对象中,这些节点对象将与其他节点一起形成一个图(索引)。这种切分的主要原因是LLM有限的输入token容量,因此,在提示中以一种平滑、连续的方式提供大型文档的策略将是有帮助的。
图索引可以是一个简单的列表结构、树结构或关键字表。此外,还可以从不同的索引中组合一个索引。当我们想要将文档组织成一个层次结构以获得更好的搜索结果时,这个很有用。例如,我们可以在Confluence、Google Docs和电子邮件上创建单独的列表索引,并在列表索引上创建一个覆盖性的树索引。
三、什么是LangChain?
LangChain是一个开源库,旨在构建具备 LLM 强大功能的应用程序。LangChain最初是用Python编写的,现在也有一个Javascript实现。它可用于聊天机器人、文本摘要、数据生成、问答等应用场景。从广义上讲,它支持以下模块:
- 提示:管理LLM作为输入的文本。
- LLM:围绕底层LLM的API包装器。
- 文档加载器:用于加载文档和其他数据源的接口。
- Utils:用于计算或与其他来源(如嵌入、搜索引擎等)交互的实用程序。
- 链:调用LLM和实用程序的顺序;朗链的真正价值。
- 索引:合并自己的数据的最佳做法。
- 代理:使用 LLM 决定要执行的操作以及顺序。
- 内存:代理或链调用之间的状态持久性。
关于 LangChain 的具体应用案例,请查看前面的几篇文章。
- 使用 Langchain、ChatGPT、Pinecone 和 Streamlit 构建交互式聊天机器人
- 使用 LangChain、Pinecone 和 LLM(如 GPT-4 和 ChatGPT)构建基于文档的问答系统
- LangChain:使用自然语言查询数据库
- Langchain Summarizer:一个让你一键生成文档摘要的领先技术
- LangChain神器:只需五步,就能构建自定义知识聊天机器人
四、LangChain 和 LLamaIndex 的区别与联系
LlamaIndex的重点放在了Index上,也就是通过各种方式为文本建立索引,有通过LLM的,也有很多并非和LLM相关的。LangChain的重点在 Agent 和 Chain 上,也就是流程组合上。可以根据你的应用组合两个,如果你觉得问答效果不好,可以多研究一下LlamaIndex。如果你希望有更多外部工具或者复杂流程可以用,可以多研究一下LangChain。
尽管LlamaIndex和LangChain在它们的主要卖点上有很多重叠,即数据增强的摘要和问答,但它们也有一些区别。LangChain提供了更细粒度的控制,并覆盖了更广泛的用例。然而,LlamaIndex的一个很大的优势是能够创建层次化的索引,这在语料库增长到一定大小时非常有帮助。
总的来说,这两个有用的库都很新,还在发展阶段,每周或每月都会有比较大的更新。也许LangChain在不久的将来吞并了LlamaIndex,提供了一个完整统一的解决方案。
五、如何使用 LLamaIndex 构建和查询本地文档索引
接下来我们就用LlamaIndex来实现构建外部文档索引进行检索,不过,我们不需要从零开始编写代码。因为这种模式非常常见,有人已经为它编写了一个开源Python包,名为 llama-index。因此,在此例中我们可以直接使用这个软件包,并通过几行代码来测试它是否能够回答与鲁迅先生所写《藤野先生》相关的问题。
首先通过pip来安装llama-index:
pip install llama-index
pip install langchain我把从网上找到的《藤野先生》这篇文章变成了一个 txt 文件,放在了 data/index_luxun 这个目录下。
import openai, os
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
openai.api_key = os.environ.get("OPENAI_API_KEY")
documents = SimpleDirectoryReader('/content/data/luxun').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
index.set_index_id("index_luxun")
index.storage_context.persist('./storage')输出结果:
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total embedding token usage: 6763 tokens注:日志中会打印出来我们通过 Embedding 消耗了多少个 Token。
1)、首先,我们通过一个叫做 SimpleDirectoryReader 的数据加载器,将整个./data/index_luxun 的目录给加载进来。这里面的每一个文件,都会被当成是一篇文档。
2)、然后,我们将所有的文档交给了 GPTSimpleVectorIndex 构建索引。顾名思义,它会把文档分段转换成一个个向量,然后存储成一个索引。
3)、最后,我们会把对应的索引存下来,存储的结果就是一个 json 文件。后面,我们就可以用这个索引来进行相应的问答。
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir='./storage')
# load index
index = load_index_from_storage(storage_context, index_id="index_luxun")
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("根据上下文内容,告诉我鲁迅先生在日本学医的老师是谁?")
print(response)进行问答也只需几行代码。我们可以使用GPTSimpleVectorIndex的 load_from_disk 函数,将之前生成的索引加载到内存中。然后,通过对 Index 实例调用 query 函数,就能够获取问题的答案。通过外部索引,我们可以准确地获得问题的答案。
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 2984 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 34 tokens
鲁迅先生在日本学习医学的老师是藤野严九郎先生。确实,通过使用外部索引,我们可以轻松地获得问题的答案。让我们再试一下其他的问题,看看它是否能够回答正确。
response = query_engine.query("根据上下文内容,鲁迅先生是去哪里学的医学?")
print(response)输出结果:
> Got node text: 藤野先生
东京也无非是这样。上野的樱花烂熳的时节,望去确也像绯红的轻云,但花下也缺不了成群结队的“清国留学生”的速成班,头顶上盘着大辫子,顶得学生制帽的顶上高高耸起,形成一座富士山。也有解散辫子,盘得平的,除下帽来,油光可鉴,宛如小姑娘的发髻一般,还要将脖子扭几扭。实在标致极了。
中国留学生会馆的门房里有几本书买,有时还值得去一转;倘在上午,里面的几间洋房里倒也还可以坐坐的。但到傍晚,有...
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 2969 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 26 tokens
鲁迅先生去仙台的医学专门学校学习医学。它仍然正确回答了问题。那么,我们搜索到的内容,在这个过程里面是如何提交给 OpenAI 的呢?我们就来看看下面的这段代码就知道了。
from llama_index import Prompt
query_str = "鲁迅先生去哪里学的医学?"
DEFAULT_TEXT_QA_PROMPT_TMPL = (
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}\n"
)
QA_PROMPT = Prompt(DEFAULT_TEXT_QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query(query_str)
print(response)这段代码里,我们定义了一个 QA_PROMPT 的对象,并且为它设计了一个模版。
1)、这个模版的开头,我们告诉 AI,我们为 AI 提供了一些上下文信息(Context information)。
2)、模版里面支持两个变量,一个叫做 context_str,另一个叫做 query_str。context_str 的地方,在实际调用的时候,会被通过 Embedding 相似度找出来的内容填入。而 query_str 则是会被我们实际提的问题替换掉。
3)、实际提问的时候,我们告诉 AI,只考虑上下文信息,而不要根据自己已经有的先验知识(prior knowledge)来回答问题。
我们就是这样,把搜索找到的相关内容以及问题,组合到一起变成一段提示语,让 AI 能够按照我们的要求来回答问题。那我们再问一次 AI,看看答案是不是没有变。
输出结果:
鲁迅先生去仙台的医学专门学校学习医学。这一次 AI 还是正确地回答出了鲁迅先生是去仙台的医学专门学校学习的。我们再试一试,问一些不相干的问题,会得到什么答案,比如我们问问西游记的作者是谁。
QA_PROMPT_TMPL = (
"下面的“我”指的是鲁迅先生 \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"根据这些信息,请回答问题: {query_str}\n"
"如果您不知道的话,请回答不知道\n"
)
QA_PROMPT = Prompt(QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query("请问西游记的作者是谁?")
print(response)输出结果:
不知道可以看到,AI 的确按照我们的指令回答不知道,而不是胡答一气。
六、如何使用 LLamaIndex 生成文档摘要总结
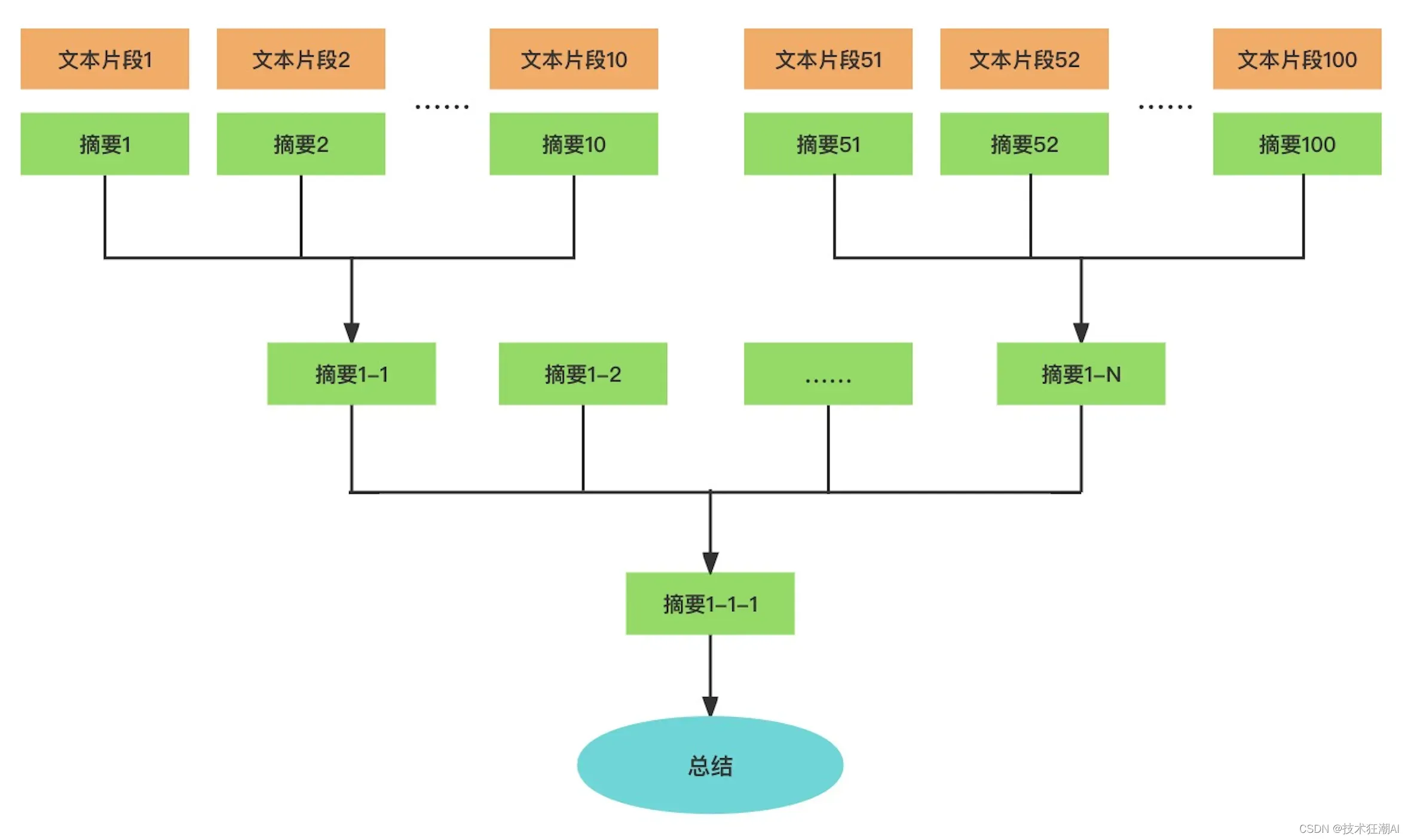
还有一个常见的使用 llama-index 的Python库的应用场景,就是生成文章摘要。前面我们已经介绍过使用适当的提示语(Prompt)来完成文本聚类。然而,如果要总结一篇论文甚至一本书,由于由于OpenAI的API接口最多只能支持4096个Token,显然是不够用的。
为了解决这个问题。我们可以通过对文本进行分段小结,并对这些小结再次进行总结来达到目的。可以将文章或书籍构建成一个树状索引,其中每个节点代表其子节点内容的摘要。最后,在整棵树的根节点处就可以得到整篇文章或整本书的总结。
 事实上,llama-index 本身就内置了这样的功能。下面我们就来看看要实现这个功能,我们的代码应该怎么写。
事实上,llama-index 本身就内置了这样的功能。下面我们就来看看要实现这个功能,我们的代码应该怎么写。
首先,我们先来安装一下 spaCy 这个 Python 库,并且下载一下对应的中文分词分句需要的模型。
pip install spacy
python -m spacy download zh_core_web_sm下面的代码非常简单,我们选择了 llama-index 中最简单的索引结构 GPTListIndex。但是根据我们的需求,我们做了两个优化。
首先,在索引中,我们指定了一个 LLMPredictor,这样在向OpenAI发起请求时,会使用ChatGPT模型。这个模型比较快速、价格也相对较低。默认情况下,llama-index使用的模型是 text-davinci-003,其价格比 gpt-3.5-turbo 高出十倍。当我们只进行几轮对话时,这种价格差异还不太明显。但如果你要处理几十本书的内容,成本就会大幅增加。因此,在这里我们设置了模型输出内容不超过1024个Token长度,以确保摘要不会太长,并避免合并无关内容。
其次,我们使用 SpacyTextSplitter 来进行中文文本分割。默认情况下,llama-index对中文支持和效果都不太好。幸运的是它允许自定义文本分割方式。由于我们选用的文章是中文且标点符号也是中文的,所以我们选择了中文语言模型进行分割操作。同时限制分割后的每个段落长度不超过 2048 个Token。你可以根据实际处理文章内容和特性来自定义这些参数设置。
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import SpacyTextSplitter
from llama_index import GPTListIndex, LLMPredictor, ServiceContext
from llama_index.node_parser import SimpleNodeParser
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024))
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./data/luxun').load_data()
nodes = parser.get_nodes_from_documents(documents)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
list_index = GPTListIndex(nodes=nodes, service_context=service_context)
query_engine = list_index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:")
print(response)输出结果:
鲁迅先生在文章中以第一人称‘我’写了他在仙台学医期间的经历,包括他与藤野先生的关系、学习医学的困难和他最终离开医学专业的决定。他对藤野先生的感激和敬仰一直延续至今。在构建 GPTListIndex 索引时,并不会创建 Embedding,因此索引的创建速度很快,也不会消耗大量的Token数量。它只是根据您设置的索引结构和分割方式建立了一个列表形式的索引。
接下来,我们可以让AI帮助我们对这篇文章进行总结。同样地,提示语本身非常重要,所以我们强调文章是鲁迅先生以第一人称“我”来写的。由于我们想要按照树状结构对文章进行总结,所以设置了一个参数 response_mode = “tree_summarize”。这个参数将会根据之前提到的树状结构来对整篇文章进行总结。
实际上,它会将每个文本段落通过查询中的提示语进行摘要。然后再通过查询中的提示语继续对多个摘要内容进行进一步总结。
from llama_index import GPTTreeIndex
# define LLM
tree_index = GPTTreeIndex(nodes=nodes, service_context=service_context)
query_engine = tree_index.as_query_engine(mode="summarize")
response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:")
print(response)输出结果:
鲁迅先生在这篇文章中讲述了他在日本留学期间的经历,包括他遇到的人和事,以及他的学习情况。他特别提到了他的解剖学教授藤野严九郎,藤野先生对他的学习和讲义进行了指导和修改。此外,鲁迅还提到了一些关于中国文化的误解,比如中国女人裹脚的问题。最后,他还引用了《新约》上的句子,表达了他的思考和感悟。可以看到,我们只使用了几行代码就成功完成了对整篇文章的总结。总体而言,返回的结果还算不错。
七、LLamaIndex 在多模态识别图片中的应用
llama_index不仅可以索引文本信息,还可以索引包含图片和插图等多媒体信息的书籍。这就是所谓的多模态能力。当然,实现这种能力需要借助一些多模态模型来将文本和图片联系在一起。后面我们将专门介绍关于图像的多模态模型。
现在我们来看一个 llama_index 官方样例库中提供的例子:拍下吃饭时的小票,并询问吃了什么、花了多少钱的情况。
%pip install torch transformers sentencepiece Pillowfrom llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.readers.file.base import (
DEFAULT_FILE_READER_CLS,
ImageReader,
)
from llama_index.response.notebook_utils import (
display_response,
display_image,
)
from llama_index.indices.query.query_transform.base import (
ImageOutputQueryTransform,
)
# NOTE: we add filename as metadata for all documents
filename_fn = lambda filename: {'file_name': filename}
receipt_reader = SimpleDirectoryReader(
input_dir='./data/image',
file_metadata=filename_fn,
)
receipt_documents = receipt_reader.load_data()我们首先使用上面定义的自定义image parser和metadata function来摄取我们的收据图像。这样我们就可以得到图像文档而不仅仅是文本文档。
我们像往常一样构建一个简单的向量索引,但与以前不同的是,我们的索引除了文本外还包含图像。
receipts_index = VectorStoreIndex.from_documents(receipt_documents)然后,我们只需要用自然语言提出问题来查询索引,就能找到对应的图片。在提问时,我们专门设计了一个ImageOutputQueryTransform,主要是为了在输出结果时,在图片外部添加<img>标签以便在Notebook中显示。
from llama_index.query_engine import TransformQueryEngine
query_engine = receipts_index.as_query_engine()
query_engine = TransformQueryEngine(query_engine, query_transform=ImageOutputQueryTransform(width=400))
receipts_response = query_engine.query(
'When was the last time I went to McDonald\'s and how much did I spend?',
)
display_response(receipts_response)输出结果:
The last time you went to McDonald's was on 03/10/2018 at 07:39:12 PM and you spent $26.15.
在OpenAI及整个大语言模型生态系统快速发展的背景下,llama-index库也在迅速迭代。在我自己使用过程中,也遇到了各种小错误。对于中文支持也存在一些小缺陷。不过,作为一个开源项目,它已经拥有了很好的生态系统,尤其是提供了许多DataConnector选项。这些选项包括PDF、ePub等电子书格式以及YouTube、Notion、MongoDB等外部数据源和API接入数据甚至本地数据库的数据。您可以在 llamahub.ai 上查看社区开发的各种不同数据源格式的DataConnector。
八、总结与展望
通过本文的介绍,您已经掌握了如何轻松上手使用 llama-index 这个Python包。借助它,您可以迅速将外部资料库转换为索引,并通过提供的查询接口向文档提问。同时,您还可以利用分片和树形结构管理索引来生成摘要。
llama-index 不仅具备丰富的功能,而且作为一个Python库,它仍在不断发展和完善。它极大地便利了与大语言模型相关的应用程序开发。相关文档可在官方网站查阅,代码也是开源的。如遇问题,您还可以直接查看源代码以深入了解。
实际上,llama-index 提供了一种创新的大语言模型应用设计模式。它通过先为外部资料库建立索引,再在每次提问时从资料库中搜索相关内容,最后利用AI的语义理解能力基于搜索结果回答问题。
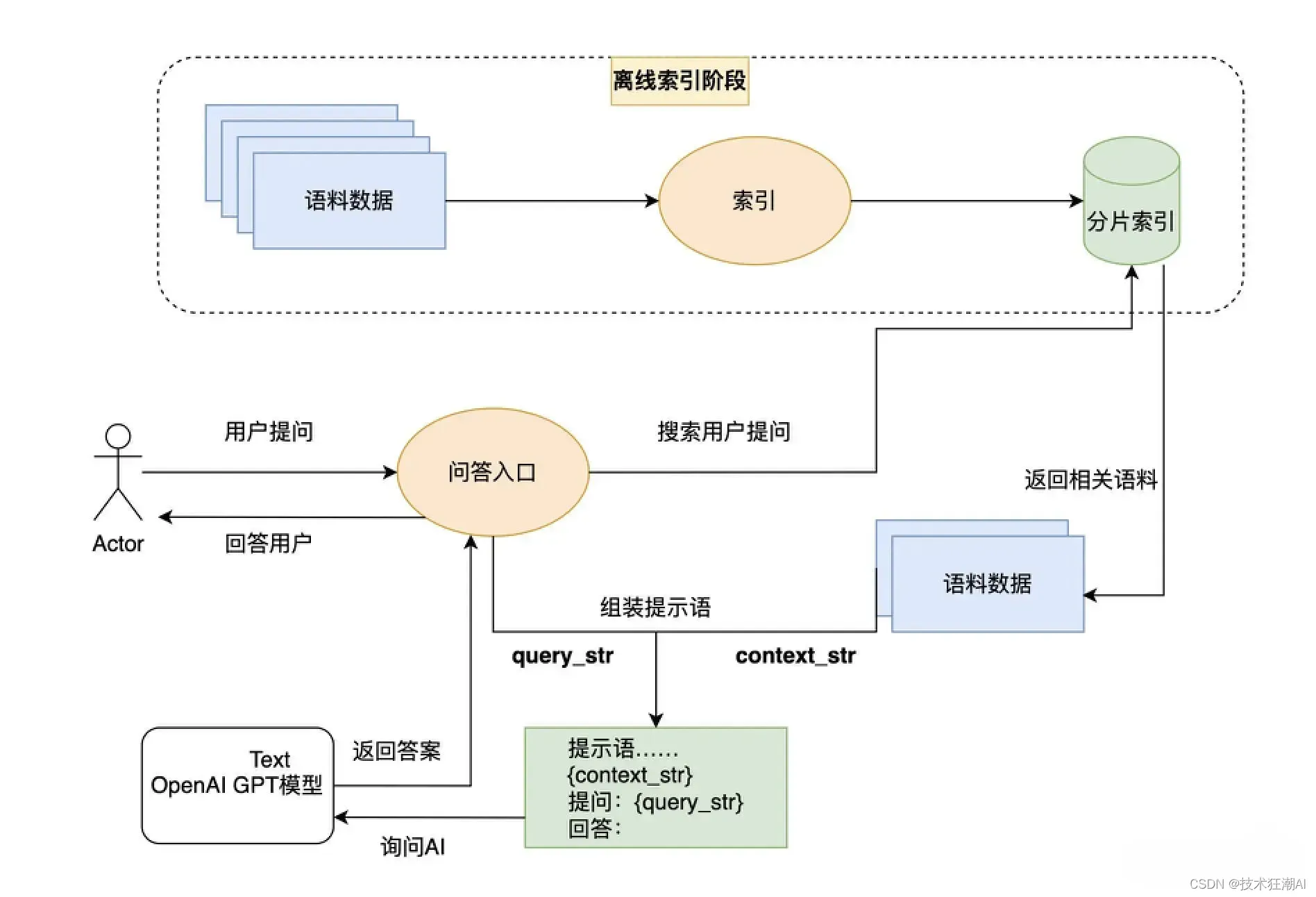 在索引和搜索的前两步,我们可以使用 OpenAI 的 Embedding 接口,也可以使用其他大语言模型的 Embedding 接口,或者使用传统的文本搜索技术。只有在问答的最后一步,才必须使用 OpenAI 的接口。我们不仅可以索引文本信息,还可以通过其他模型将图片转换为文本并进行索引,实现所谓的多模态功能。
在索引和搜索的前两步,我们可以使用 OpenAI 的 Embedding 接口,也可以使用其他大语言模型的 Embedding 接口,或者使用传统的文本搜索技术。只有在问答的最后一步,才必须使用 OpenAI 的接口。我们不仅可以索引文本信息,还可以通过其他模型将图片转换为文本并进行索引,实现所谓的多模态功能。
通过今天给出的几个例子,希望您也能开始建立自己的本地资料库,并将自己的数据集交给AI进行索引。这样您就能拥有一个专属于自己的AI了。
Jupyter Notebook 的完整代码:https://github.com/Crossme0809/langchain-tutorials/blob/main/Using_LlamaIndex_Query_Documents.ipynb
九、推荐阅读
llama-index 的功能非常强大,并且源代码里也专门提供了示例部分。你可以去看一下它的官方文档以及示例,了解它可以用来干什么。
官方文档:https://gpt-index.readthedocs.io/en/latest/
源码以及示例:https://github.com/jerryjliu/llama_index
文章出处登录后可见!