文章目录
【半监督医学图像分割 2023 CVPR】UCMT 论文翻译
论文题目:Co-training with High-Confidence Pseudo Labels for Semi-supervised Medical Image Segmentation
中文题目:基于高置信度伪标签的联合训练半监督医学图像分割
论文链接:https://arxiv.org/abs/2301.04465
论文代码:https://github.com/Senyh/UCMT
发表时间:2023年1月
论文团队:东北大学&福建师范大学&阿尔伯塔大学
引用:Shen Z, Cao P, Yang H, et al. Co-training with High-Confidence Pseudo Labels for Semi-supervised Medical Image Segmentation[J]. arXiv preprint arXiv:2301.04465, 2023.
引用数:
摘要
高质量的伪标签对于半监督语义分割是必不可少的。 一致性正则化和基于伪标记的半监督方法利用来自多视图输入的伪标记进行协同训练。
然而,这种协同训练模型往往在训练过程中早期收敛到一致,从而导致模型退化到自我训练模型。
另外,多视点输入是通过对原始图像的扰动或增强而产生的,这不可避免地会在输入中引入噪声,导致低置信度的伪标签。
针对这些问题,我们提出了一种基于不确定性指导的协同均值教师(UCMT)算法,用于具有高置信度伪标签的半监督语义分割。
具体而言,UCMT由两个主要部分组成:
1)协同均值教师(CMT)用于鼓励模型分歧并在子网络之间进行协同训练;
2)不确定性引导区域混合(UMIX)用于根据CMT的不确定性映射操作输入图像,并促进CMT产生高置信度的伪标签。
UCMT结合了UMIX和CMT的优点,在协同训练分割中保留了模型的不一致性,提高了伪标签的质量。
在包括二维和三维模式的四个公共医学图像数据集上进行了广泛的实验,证明了UCMT相对于现有技术的优越性。
1. 介绍
语义分割是医学图像分析的关键。 基于深度学习的分割模型依靠大量的标记数据取得了很大的进展[1,2]。
然而,标记这种像素级注释是费力的,需要专家知识,特别是在医学图像中,导致标记数据昂贵或根本不可用。 与此相反,未标记的数据价格低廉,且相对容易获得。
在这种情况下,半监督学习(SSL)通过从有限数量的标记数据和任意数量的未标记数据中挖掘信息,以缓解标记稀缺性问题,成为主要的数据高效策略[3]。
一致性正则化[4]和伪标记[6]是半监督语义分割的两种主要方法。
目前,通过子网络间的交叉监督,将一致性正则化和伪标记相结合,在半监督分割中表现出了很好的性能[6,7,8,5,9]。 这些方法的一个关键缺陷是子网络往往很早就收敛到一致情况,导致协同训练模型退化为自训练[10]。
在协同训练中,子网络之间的不一致性是至关重要的,用不同的参数初始化或用不同的视图训练的子网络具有不同的偏差(即不一致性),以确保它们提供的信息是相互补充的。
影响这些方法性能的另一个关键因素是伪标签的质量。
更重要的是,这两个因素是相互影响的。 直观地说,高质量的伪标签应该具有低的不确定性[11]。
然而,通过不同的扰动或增强来增加协同训练子网络之间的不一致程度,会导致它们的训练方向相反,从而增加伪标签的不确定性。
为了研究不一致性和伪标签质量对基于协同训练的半监督分割的影响,我们进行了一个试点实验来说明这些相关性。 如图1所示,与均值教师(MT)[4][图1(a)]相比,交叉伪监督(CPS)[5][图1(b)]具有较高的模型分歧[(d)]和较低的不确定性[图1(e)]在半变量分割上产生较高的性能[图1(f)]。
注意,两个分支的骰子损失是计算来衡量分歧的。
问题是:如何有效地改善协同训练子网络与伪LA质量之间的不一致
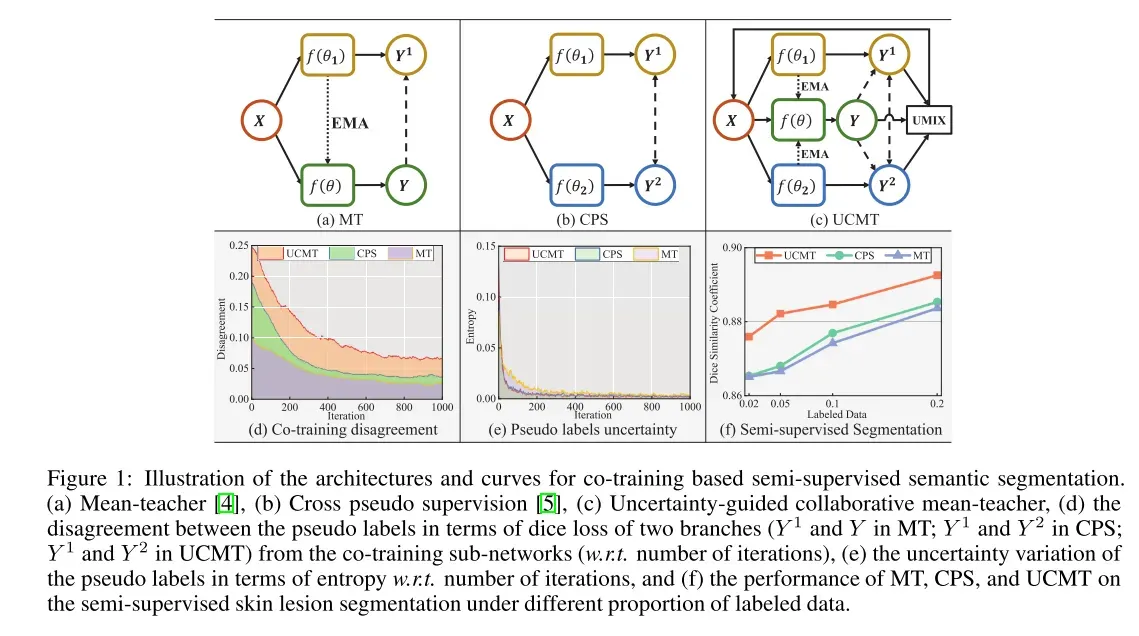
本文主要研究了两个主要目标:同时保持模型的不一致性和高置信度的伪标签。
为此,我们提出了不确定性引导的协同均值教师(UCMT)框架,该框架能够基于更高置信度的伪标签(图1(e)),保留协同训练分割子网络之间更高的不一致性(图1(d)),从而在相同的骨干网和任务设置下实现更好的半监督分割性能(图1(f))。
具体而言,UCMT包括两个主要部分:
1)协同均值教师(CMT)和2)不确定性引导区域混合(UMIX),
其中UMIX根据CMT的不确定性映射操作输入图像,而CMT则在UMIX图像的伪标签监督下进行协同训练。
受协同教学[12,10,5]的启发,我们在协同训练框架中引入了第三个组件教师模型,作为正则化器来构造CMT以获得更有效的SSL。
教师模型通过对学生模型的平均作为自我集成,作为第三部分指导两个学生模型的培养。
此外,我们开发了UMIX来构造高可信度的伪标签,并执行区域退出来学习鲁棒的半监督语义分割模型。 UMIX不是随机区域擦除或交换[13,14],而是根据分割模型的认知不确定性对原始图像及其对应的伪标签进行处理,不仅降低了伪标签的不确定性,而且扩大了训练数据的分布。
最后,通过结合UMIX和CMT的优点,本文提出的UCMT方法在多个基准数据集上的半监督分割中显著地改善了现有的(SOTA)结果。 例如,UCMT和UCMT(U-Net)的DICE SIMIL分别达到88.22%和82.14%
概括地说,我们的贡献主要包括:
- 我们指出了现有的基于协同训练的半监督分割方法存在的问题:子网络之间的不一致性不足和伪标签置信度较低。 为了解决这一问题,我们设计了一个不确定性指导协作模型教师来保持与高置信度伪标签的协同训练,其中我们将CMT和UMIX结合到一个半监督医学图像分割的整体框架中。
- 为了避免在新样本中引入噪声,我们提出了一种不确定性引导的区域混合算法UMIX,该算法鼓励分割模型产生高可信度的伪标签,并扩大训练数据分布。
- 我们在四个公共医学图像分割数据集上进行了广泛的实验,包括二维和三维场景,以研究我们方法的有效性。 综合结果表明,我们的方法每个组成部分的有效性和UCMT优于现有的技术。
2. 相关工作
2.1 半监督学习
半监督学习旨在通过利用通常与无监督学习相关的信息来提高监督学习的性能,反之亦然[3]。
SSL的一种常见形式是在监督学习的目标函数中引入一个正则化项,以利用未标记的数据。
从这个角度来看,基于SSL的方法可以分为两条主线,即伪标记和一致性正则化。
伪标记试图生成类似于groud truth的伪标记,对其进行模型训练,如监督学习[6]。 一致性正则化使模型的输出在不同扰动下对输入保持一致[4]。
目前最先进的方法已经将这两种策略结合起来,并在半光滑图像分类中显示出优越的性能[16,17]。 在此基础上,我们探索了更有效的一致性学习算法用于半监督语义分割。
2.2 半监督分割
与图像分类相比,语义分割对像素级标注的要求更高,代价也更大。 半监督语义分割继承了半监督图像分类的主要思想。
一致性正则化和伪标记相结合,主要是利用伪标记在子网络之间进行交叉监督,已经成为自然图像[7,5]和医学图像[18,19,20,21]半监督语义分割的主流策略。
具体地说,这些组合方法加强了不同扰动下预测的一致性,例如输入扰动[22,23]、特征扰动[7]和网络扰动[4,5,20,21]。 另外,基于对抗性学习的方法,使来自标记数据的模型预测分布与来自未标记数据的模型预测分布一致,也可以被视为一致性正则化的一种特殊形式[24,25]。 然而,这种交叉监管模式可能会早期收敛为共识,从而退化为自我训练模式。 我们假设扩大基于高置信度伪标签的协同训练模型的不一致性可以提高SSL的性能。 因此,我们提出了一种新的SSL框架,即UCMT,以生成更准确的伪标签,并保持半监督医学图像分割的协同训练。
2.3 不确定性引导的半监督语义分割
模型不确定性(认知不确定性)可以指导SSL模型从伪标签中捕获信息。 利用模型不确定性的两个关键问题是如何获取和利用模型不确定性。 目前,估计模型不确定性的策略主要有两种:1)使用Monte Carlo Dropout[26],2)计算不同预测之间的方差[27]。 对于半监督语义分割,以往的研究利用模型的不确定性来重新加权训练损失[18]或选择对比样本[15]。 然而,这些方法都需要手动设置阈值,以忽略低置信度伪标签,其中固定阈值难以确定。 本文通过对相同输入的CMT预测的熵来获得认知不确定性,并利用这种不确定性来指导区域混合,以便从未标记的数据中逐步挖掘信息。
3. 方法
3.1 问题的定义
在介绍我们的方法之前,我们首先定义了半监督分割问题,并给出了本文中使用的一些符号。 训练集包含一个标记集
和一个未标记集
,其中
表示第
个标记/未标记图像,
是标记图像的基本真值,
和
分别是标记和未标记样本的个数。 给定训练数据
,半监督语义分割的目标是学习一个在未知测试集上表现良好的模型
。
3.2 总览
为了避免协同训练对自训练的影响,我们建议在训练过程中鼓励模型分歧,并保证伪标签具有较低的不确定性。
基于这种动机,我们提出了一种基于不确定性指导的协同均值教师半监督图像分割方法,该方法包括:1)协同均值教师和2)不确定性指导的区域混合。
如图1(d)所示,CMT和UCMT逐渐扩大了协同训练子网络之间的分歧。
同时,CMT配备了UMIX,保证了伪标签的低不确定性。
借助这些条件,我们可以安全地维持协同训练状态,从而提高SSL对未标记数据挖掘的有效性。
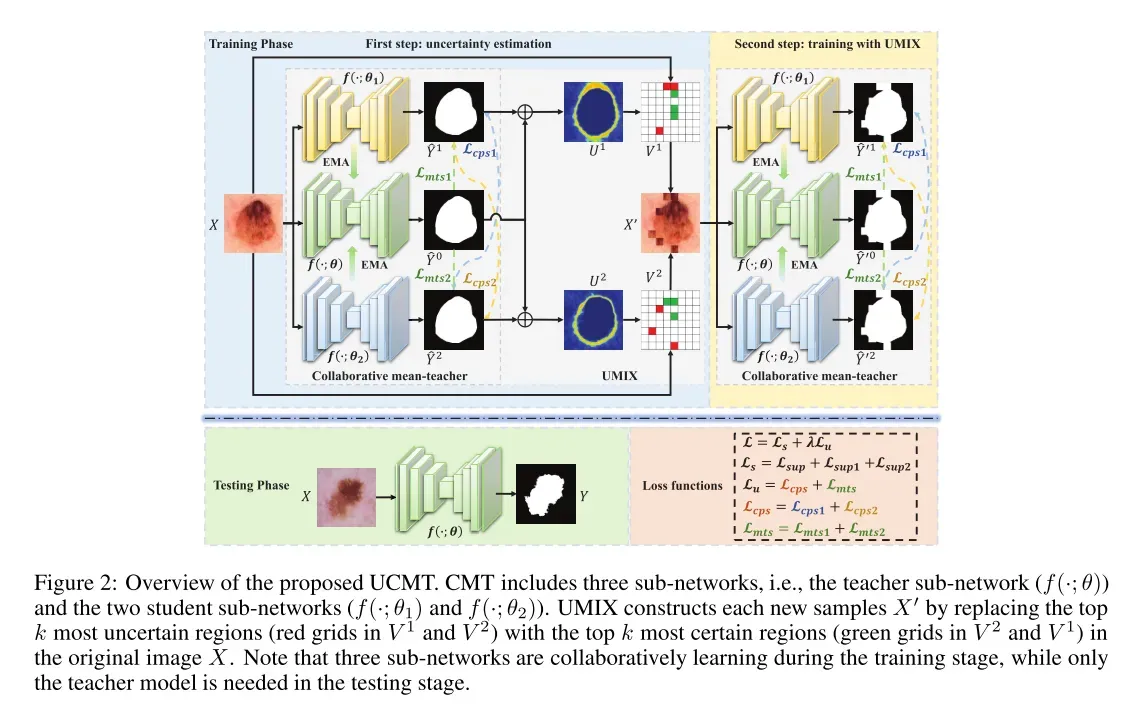
CMT及UMIX的详情分别载于第3.3及3.4节。 图2说明了拟议的UCMT的示意图。
UCMT的训练阶段一般分为两个步骤。
第一步,利用原始标记和未标记数据对CMT进行训练,得到不确定度图; 然后,我们使用MUMIX生成基于不确定性映射的新样本。
在第二步中,我们使用UMIX样本重新训练CMT。 UCMT训练过程的细节如算法1所示。
虽然UCMT包括三个模型,即一个教师模型和两个学生模型,但在测试阶段只需要教师模型。
3.3 协作式均值教师
目前基于一致性学习的SSL算法,如Mean-Teacher[4]和CPS[5],建议在多模型体系结构中执行伪标签之间的一致性正则化,而不是在单个模型中执行。 然而,在训练过程中,双网络SSL框架可能会提前收敛到一致,协同训练退化到自训练[10]。 为了解决这个问题,我们通过在协同培训体系结构中引入一个“仲裁者”,即教师模型[5],设计了协作平均教师(CMT)框架,以指导两个学生模型的培训。
如图2所示,CMT由一个教师模型和两个学生模型组成,其中教师模型是学生模型平均值的自集成。
对于有标记的数据,这些模型都是通过监督学习优化的。 对于无标记数据,有两个关键因素:1)两个学生模型之间的协同训练;2)教师对学生模型的直接监督。 形式上,CMT的数据流图可以说明为2,
其中是标记或未标记数据的输入图像,
是预测的分割图,参数θ、θ1和θ2的
分别表示教师模型和学生模型。 这些模型具有相同的体系结构,但对网络扰动的初始化权重不同。
为了探索标记和未标记的数据,训练UCMT的总损失L包括两个部分,即有监督损失和无监督损失
其中λ是平衡有监督和无监督学习损失的正则化参数。 我们采用一个高斯渐升函数来逐渐增加系数,即λ(t)=λm×exp[-5(1-ttm)2],其中λm缩放加权函数的最大值,t表示当前迭代,tm是训练中的最大迭代。
监督学习路径。 对于标记的数据,监督损失被制定为,
其中可以是任何有监督的语义分割损失,如交叉熵损失和骰子损失。 注意,我们在实验中选择骰子损失作为它在医学图像分割中的引人注目的性能。
无监督学习路径。 无监督损失LU作为一个正则化项,为标记和未标记数据挖掘潜在的知识。 LU包括两个学生模型之间的交叉伪监督LCPS和从教师引导学生模型的平均教师监督LMTS,具体如下:
交叉伪监管。 LCPS的目的是促进两个学生相互学习,加强他们之间的一致性。 LCPS=LCPS1+LCPS2鼓励两个学生子网络f(·;θ1)和f(·;θ2)的双向交互,如下所示,
均值–教师监督。 为了避免两个学生交叉督导的错误方向,我们引入了教师模式来指导学生模式的优化。 具体地说,教师模型通过学生模型平均值的指数移动平均值(EMA)来更新:
其中T表示当前的训练迭代。 α是控制参数更新速率的均方根衰减,我们在实验中设置α=0.999。 平均教师监督损失LMTS=LMTS1+LMTS2由两个分支计算:
3.4 不确定性指导混合
尽管CMT可以促进协同训练的不一致性,但它也稍微增加了伪标签的不确定性,如图1所示。
另一方面,随机区域退出可以扩大训练分布,提高模型的泛化能力[13,14]。
然而,这种对输入图像的随机扰动不可避免地在新样本中引入噪声,从而恶化了SSL伪标签的质量。
一个子网络可能会向其他子网络提供一些不正确的伪标签,从而降低它们的性能。
为了克服这些缺陷,我们提出了UMIX算法,在CMT产生的不确定性映射的指导下对图像进行处理。 UMIX的主要思想是用输入图像中的前k个最确定(高置信度)区域替换前k个最不确定(低置信度)区域来构造新的样本。
例如,如图2所示,我们从不确定性图U中获得最不确定的区域(红色网格)和最确定的区域(绿色网格)。然后,我们用输入图像X中的绿色区域替换红色区域,以构造新的样本X’。
形式上,Umix构造了一个新的样本x’=Umix(x,u1,u2;k,1/r),方法是用x中的前k个最确定的区域(V1和V2中的红色网格)替换前k个最不确定的区域(V2和V1中的绿色网格),其中每个区域的大小为图像大小的1/r。
为了保证不确定度评估的可靠性,我们通过对教师和学生模型的输出进行积分来获得不确定映射,而不是执行Monte Carlo dropout估计模型[26,18]设计的t个随机前向传递,这相当于从以前和当前的迭代中采样预测。 这一过程可制定为:
其中m=1,2表示学生模型的索引,c表示类索引。
4. 实验和结论
5. 总结
提出了一种用于半监督医学图像分割的不确定性引导协作均值教师。 我们的主要思想在于保持与高置信度伪标签的协同训练,以提高SSL模型从未标记数据中挖掘信息的能力。 在四个公共数据集上的大量实验证明了该思想的有效性,并表明所提出的UCMT可以达到最先进的性能。 在未来的研究中,我们将更加深入地研究协同训练的潜在机制,以实现更有效的半监督图像分割。
文章出处登录后可见!