Transformer中的编码器不止一个,而是由一组N个编码器串联而成,一个编码的输出作为下一个编码器的输入,如下图所示,每一个编码器都从下方接收数据,再输出给上方,以此类推,原句中的特征会由最后一个编码器输出,编码器模块的主要功能就是提取原句中的特征
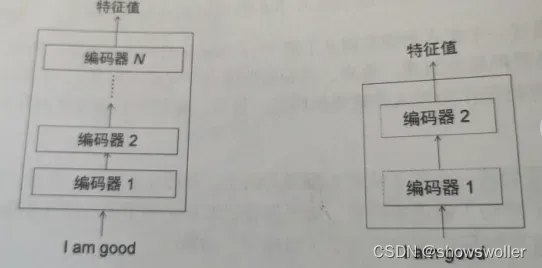
我们又可以将编码器中的结构进行细分
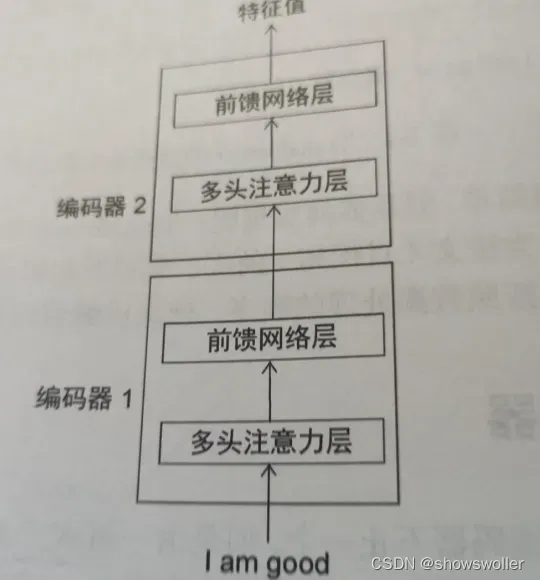
由上图可知,每一个编码器的构造都是相同的,并且包含两个部分
1:多头注意力层
2:前馈网络层
下面我们对其进行讲解
一、自注意力机制
让我们通过一个例子来快速理解自注意力机制
a dog ate the food because it was hungry
想必大家都能看懂这句英文的意思,句中的it可以指代dog也可以指代food,我们自然是很好理解,但是对于计算机而言该如何决定呢?自注意力机制有助于解决这个问题
以上句为例,我们的模型首先需要计算出单词A的特征值,其次计算dog的特征值,以此类推,当计算每个词的特征值时,模型都需要遍历每个词与句子中其他词的关系,模型可以通过词与词之间的关系来更好的理解当前词的意思
比如当计算it的特征值时,模型会将it与句子中的其他词一一关联,以便更好的理解它的意思
如下图所示,it的特征值由它本身与句子中其他词的关系计算所得,通过关系连线,模型可以明确知道原句中it所指代的是dog而不是food,这是因为it与dog的关系更紧密,关系连线相较于其他词也更粗

自注意力机制首先将每个词转化为其对应的词嵌入向量,这样原句就可以由一个矩阵来表示

矩阵X的维度为【句子长度×词嵌入向量维度】通过矩阵X,我们可以再创建三个新的矩阵,分别是
查询矩阵Q
健矩阵K
值矩阵V
为了创建他我们需要先创建另外三个权重矩阵,用X分别乘它们得到上述三个矩阵
值得注意的是,权重矩阵的初始值完全是随机的,但最优值则需要通过训练获得,我们取得的权值越优,则上述三个矩阵也越精确

因为每个向量的维度均为64,所以对应矩阵的维度为【句子长度×64】
自注意力机制会使该词与给定句子中的所有词联系起来,包括四个步骤,下面一一介绍
1:计算查询矩阵与键矩阵的点积,其目的是为了了解单词1与句子中的所有单词的相似度

2:第二步将查询矩阵与键矩阵除以键向量维度的平方根,这样做的目的是为了获得稳定的梯度
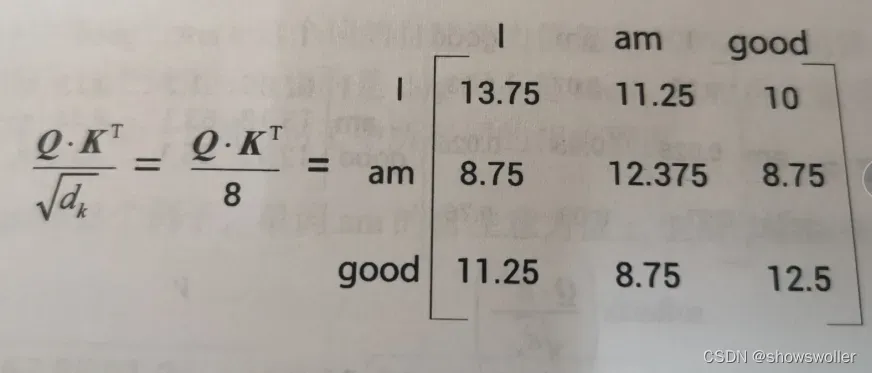
3:目前所得的相似度分数尚未被归一化,我们需要使用softmax函数对其进行归一化处理,使数值分布到(0,1)之间

4:至此我们计算了查询矩阵与键矩阵的点积,得到了分数,然后softmax将分数归一化,自注意力机制的最后一步使计算注意力矩阵Z

注意力矩阵就是值向量与分数加权之后求和所得到的结果
下面是自注意力机制的流程图
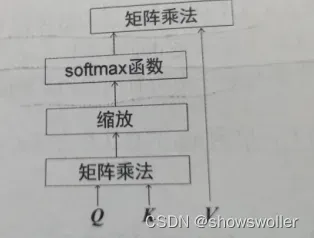
自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再除以键向量维度的平方根对结果进行缩放
二、多头注意力层
多头注意力是指我们可以使用多个注意力头,而不是只用一个,也就是说我们可以利用计算注意力矩阵Z的方法,来求得多个注意力矩阵
如果某个词实际上是由其他词的值向量控制,而这个词的含义又是模糊的,那么这种控制关系是有用的,否则这种控制关系会造成误解,为了确保结果准确,我们不能依赖单一的注意力矩阵,而应该计算多个注意力矩阵,并将其结果串联起来,使用多头注意力的逻辑如下:
使用多个注意力矩阵,而非单一的注意力矩阵,可以提高注意力矩阵的准确性
三、通过位置编码来学习位置
Transformer网络并不遵循递归循环的模式,因此我们不是逐字的输入句子,而是将句子中的所有词并行的输入到神经网络中,并行输入有助于缩短训练时间,同时有利于学习长期依赖,但是这样没有保留词序,因此这里引入了一种叫做位置编码的技术,位置编码是指词在句子中的位置的编码
位置编码矩阵P的维度与输入矩阵X的维度相同,在将输入矩阵传给Transformer之前,我们将其包含位置编码,只需要将P+X即可,然后再作为输入传给神经网络,这样依赖,输入矩阵不仅有词的嵌入值,还有词在句子中的位置信息
Transformer论文的作者使用正弦函数来计算位置编码
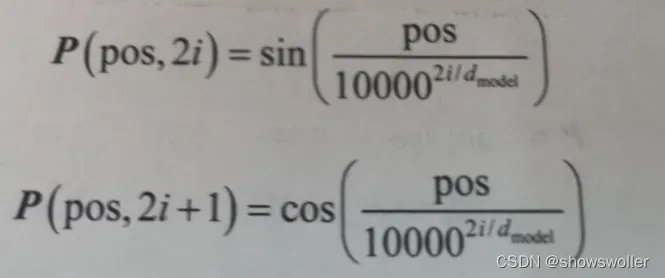
四、前馈网络层
前馈网络层由两个有ReLU激活函数的全连接层组成,前馈网络的参数在句子的不同位置上是相同的,但在不同的编码器模块上是不同的
五、叠加和归一组件
在编码器中还有一个重要的组成部分,即叠加和归一组件,它同时连接一个子层的输入和输出
叠加和归一组件实际上包含一个残差连接与层的归一化,层的归一化可以放置每层的值剧烈变化,从而提高了模型的训练速度
总结
编码器总结如下
1:将输入转换为输入矩阵,并将位置编码加入其中,再将结果作为输入传入底层的编码器
2:编码器1接收输入并将其送入多头注意力层,该子层运算后输入注意力矩阵
3:将注意力矩阵输入到下一个子层,即前馈网络层,前馈网络层将注意力矩阵作为输入,并计算出特征值作为输出
4:接下来,把从编码器1中得到输出作为输入,传入下一个编码器
5:编码器2进行同样的处理,再将给定输入的句子的特征值作为输出
这样可以将N个编码器一个接一个的叠加起来,从最后一个编码器得到输出将是给定输入句子的特征值,让我们把从最后一个编码器得到的特征值表示为R
我们把R作为输入传个解码器,解码器将基于这个输入生成目标句子
创作不易 觉得有帮助请点赞关注收藏~~~
文章出处登录后可见!