🦄crf可谓是NER任务小能手了,所以搞NER就得玩玩crf。
⭐torch官方tutorials部分提供的crf链接:点击进入,
该链接里是结合了bi-lstm和crf的代码教程(适合学习CRF原理),不过我看了下这只支持CPU的。
⭐我使用的是pytorch-crf库,该crf可支持GPU加速处理(即支持批处理的数据)。
pytorch-crf文档链接:点击进入。
但是,文档中的解释很少,有些地方不清楚。百度和谷歌发现没有库的使用示例,于是尝试自己搭建模型,可以使用。
🚀这里附上我写的一个完成NER任务的bi-lstm+crf模型,
github地址:https://github.com/XFR1998/study-NER
首先是实例化crf层:
import torch
from torchcrf import CRF
num_tags = 5 # NER数据集中
crf = CRF(num_tags=num_tags,
batch_first=True)
用了批处理(padding)需要做mask:
注意,若是用了批处理,需要做mask。因为每个批次你都有做padding的话,通过mask可以将这些padding的部分mask掉,预测(解码)最优序列时将不会对这些mask的部分做预测。
一开始不太确定,就问了下作者应该是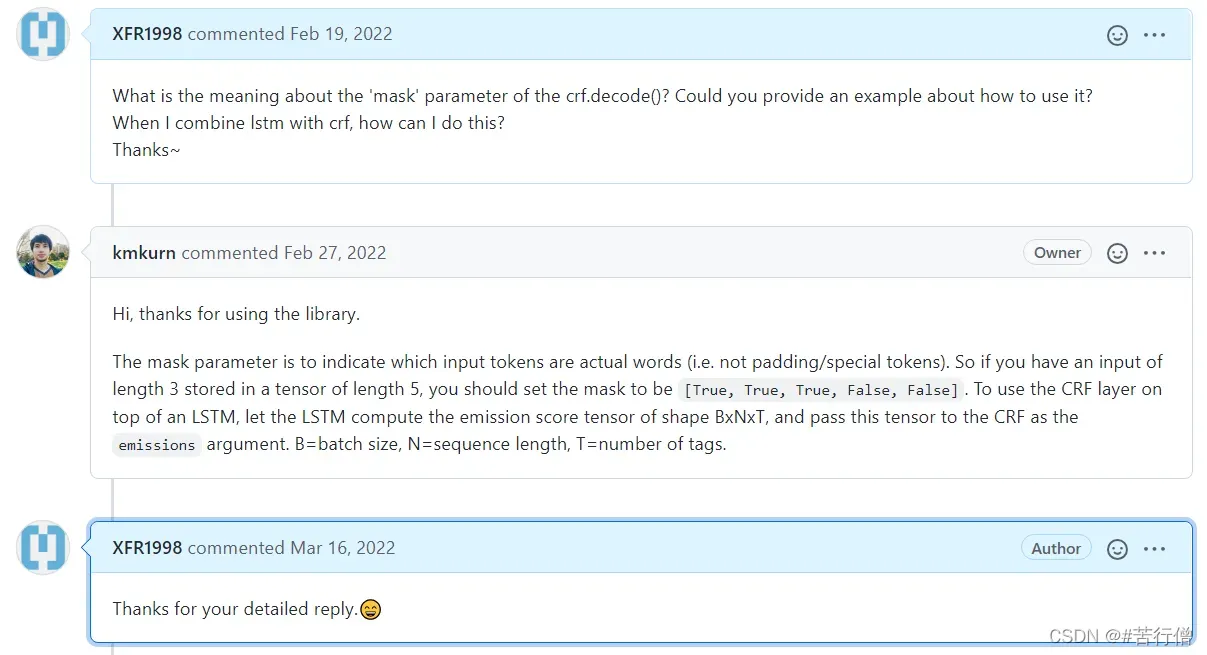
如文本为:“the dog is so cool
那mask向量(mask_tensor)就为:[1, 1, 1, 1, 0, 0]
有2个地方需要mask:
1.crf层的输出:
因为crf的得分输出是正的,得分越高说明选出的最优标注序列路径有准,那我们可以将其取负,作为我们的损失函数进行反向传播:
【其中的emissions参数指的是发射得分,比如我们可以在lstm层后输出每个token的特征,并将其出入一个全连接层(输出维度为标签数量),这样每个token对应一个关于各标签的得分分布,所有token构成的这个张量就是emissions了,主要也就将lstm和crf衔接了起来。如下图所示的结构。】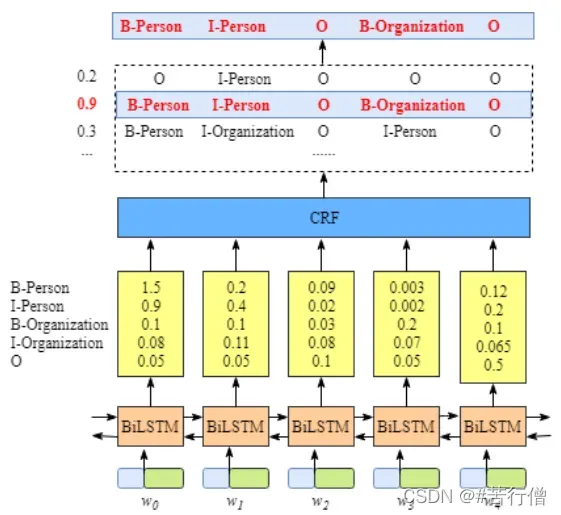
# 当然这个crf层可以写在模型中,在forward中计算返回损失即可
loss = crf(emissions=lstm_feats,
tags=label_tensor,
mask=mask_tensor)
loss.backward()
2.crf的解码,解码出最优序列:
这样解码出的out就是批次里每条文本对应的最优标注序列了。
out = self.crf.decode(emissions=lstm_feats,
mask=mask_tensor)
文章出处登录后可见!