在语义分割模型中,一般通过Backbone获得不同分辨率的特征图,然后将特征图融合生成预测结果,在此过程中,不可避免地需要将低分辨率特征图进行上采样提高其分辨率,本文统计了常用的上采样方法,并给出部分上采样算法的numpy实现代码,与opencv进行对比检验代码的正确性。部分代码给出pytorch使用示例。
内容
1. 插值
1、最近邻插值
2、双线性插值
3、其他插值方法
二、PixelShuffle
三、反池化(unpool)
四、转置卷积(deconvolution)
5. 附录
1. 插值
插值利用像素间的相互关系计算出插入的像素值,最简单常用的是最近邻插值和双线性插值(提供了numpy实现的代码),还有其他的插值方法本文不过多介绍。
1、最近邻插值
最近邻插值是最简单的插值方法。选择离目标点最近的点作为新的插入点,如下例所示:
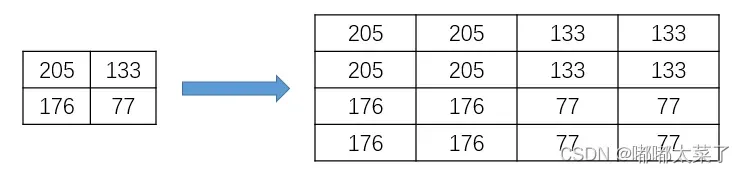
numpy实现及opencv对比:
import cv2
from math import floor
import numpy as np
def interpolate_nearest(image, size):
new_img = np.zeros(shape=size[::-1] + (image.shape[-1], )).astype('uint8')
scale_h = image.shape[0] / size[1]
scale_w = image.shape[1] / size[0]
for i in range(size[1]):
for j in range(size[0]):
new_img[i, j] = image[int(floor(i * scale_h)), int(floor(j * scale_w))]
return new_img
image = cv2.imread('512.png')
size = (256, 256) # w, h
my_resized_image = interpolate_nearest(image, size)
cv_resized_image = cv2.resize(image, size, image, 0, 0, cv2.INTER_NEAREST)
assert np.allclose(my_resized_image, cv_resized_image), "Image not equal between your implemented and opencv."
cv2.imshow("opencv", cv_resized_image)
cv2.imshow('my_op', my_resized_image)
cv2.waitKey(0)
影响:
2、双线性插值
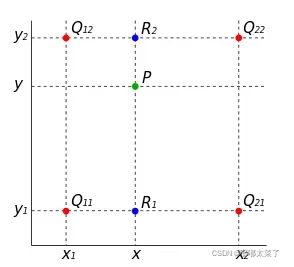
双线性插值根据插值位置与周围像素的距离计算当前的像素值,如下图P为待插值点,Q11、Q12、Q21、Q22为原像素点坐标,f(Q22)表示Q22位置的像素值。(深度学习中很多模型用这个)
为了计算P像素值,首先横向插值,计算R1,R2的像素值:
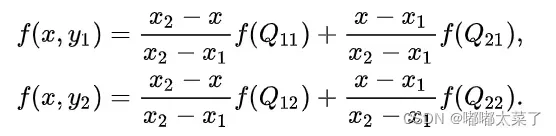
再纵向插值,根据上一步得到的R1和R2像素值,得到P的像素值:
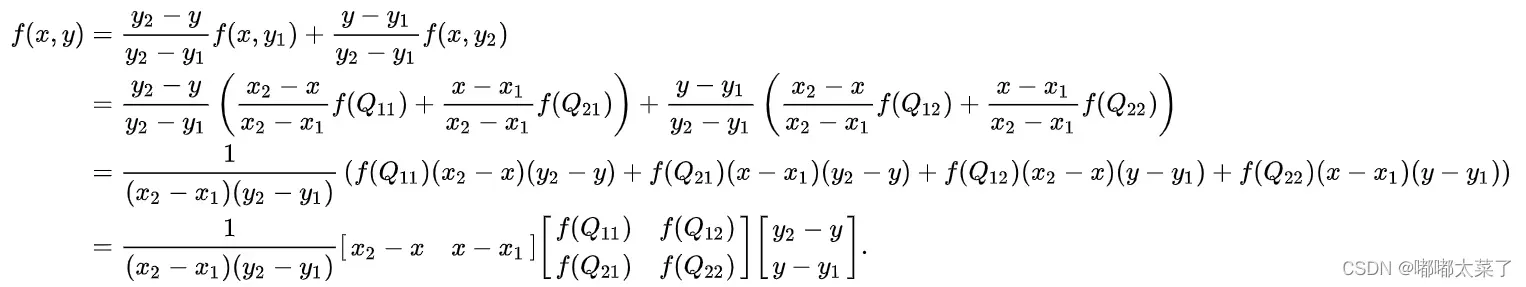
numpy实现:
import cv2
from math import floor
import numpy as np
def interpolate_linear(image, size):
h, w = image.shape[0:2]
w_new, h_new = size
h_scale = h / h_new
w_scale = w / w_new
h_index = np.linspace(0, h_new - 1, h_new)
w_index = np.linspace(0, w_new - 1, w_new)
wv, hv = np.meshgrid(w_index, h_index)
hv = (hv + 0.5) * h_scale - 0.5
wv = (wv + 0.5) * w_scale - 0.5
# hv = hv * h_scale
# wv = wv * w_scale
hv[hv < 0] = 0
wv[wv < 0] = 0
h_down = hv.astype('int')
w_down = wv.astype('int')
h_up = h_down + 1
w_up = w_down + 1
h_up[h_up > (h - 1)] = h - 1
w_up[w_up > (w - 1)] = w - 1
pos_00 = image[h_down, w_down].astype('int') # 左上
pos_01 = image[h_up, w_down].astype('int') # 左下
pos_11 = image[h_up, w_up].astype('int') # 右下
pos_10 = image[h_down, w_up].astype('int') # 右上
m, n = np.modf(hv)[0], np.modf(wv)[0]
m = np.expand_dims(m, axis=-1)
n = np.expand_dims(n, axis=-1)
a = pos_10 - pos_00
b = pos_01 - pos_00
c = pos_11 + pos_00 - pos_10 - pos_01
image = np.round(a * n + b * m + c * n * m + pos_00).astype('uint8')
return image
image = cv2.imread('512.png')
size = (256, 256) # w, h
my_resized_image = interpolate_linear(image, size)
cv_resized_image = cv2.resize(image, size, image, 0, 0, cv2.INTER_LINEAR)
print(np.mean(np.abs(my_resized_image.astype('int') - cv_resized_image.astype('int')))) # 线性插值四舍五入数值计算像素值可能差1
assert np.allclose(my_resized_image, cv_resized_image, atol=1), "Image not equal between your implemented and opencv."
cv2.imshow("opencv", cv_resized_image)
cv2.imshow('my_op', my_resized_image)
cv2.waitKey(0)
影响:
3、其他插值方法
还有许多插值方法,这里不一一列举,可以参考opencv文档。
二、PixelShuffle
对于一个维度为[N, C, H, W]的特征图,需要将其上采样R倍,得到维度为[N, C/(R^2), H*R, W*R]的特征图。实现起来颇为简单,只需要reshape即可,代码如下(和torch.nn.PixelShuffle对齐):
import torch
import numpy as np
def pixel_shuffle_np(x, up_factor):
n, c, h, w = x.shape
new_shape = (n, c // (up_factor * up_factor), up_factor, up_factor, h, w)
npresult = np.reshape(x, new_shape)
npresult = npresult.transpose(0, 1, 4, 2, 5, 3)
oshape = [n, c // (up_factor * up_factor), h * up_factor, w * up_factor]
npreslut = np.reshape(npresult, oshape)
return npreslut
np.random.seed(10001)
image = np.random.rand(2, 16, 224, 224)
scale = 4
np_image = pixel_shuffle_np(image, scale)
torch_pixel_shuffle = torch.nn.PixelShuffle(scale)
torch_image = torch_pixel_shuffle(torch.from_numpy(image))
assert np.allclose(np_image, torch_image.numpy()), "Implemented PixelShuffle is not the same with torch.nn.PixelShuffle."
三、反池化(unpool)
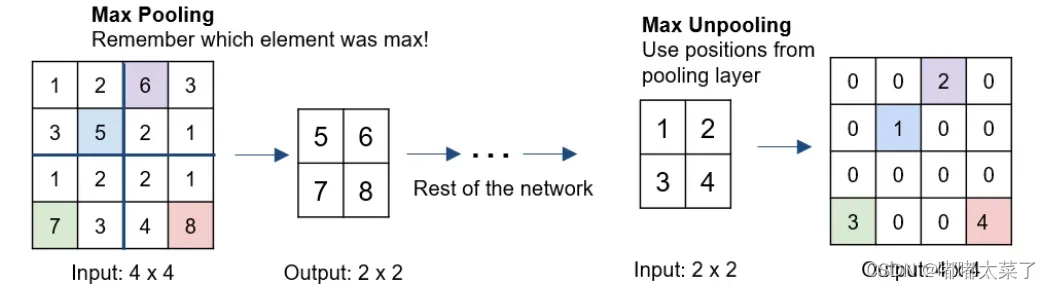
反池化过程如下图所示,对输入特征图进行池化时,保存最大值在原特征图中的索引,反池化时,将特征值放入对应索引中,其他位置填充0。
torch代码:
import torch
import numpy as np
inputs = np.array([1, 2, 6, 3, 3, 5, 2, 1, 1, 2, 2, 1, 7, 3, 4, 8], dtype='float').reshape([1, 1, 4, 4])
inputs = torch.from_numpy(inputs)
pool = torch.nn.MaxPool2d(2, stride=2, return_indices=True)
unpool = torch.nn.MaxUnpool2d(2, stride=2)
output, indices = pool(inputs)
output = unpool(output, indices)
print(output)
结果:

四、转置卷积(deconvolution)
上面介绍的方法都是没有参数的方法。有没有一种方法可以为不同的任务学习不同的参数?显然有,也就是转置卷积。
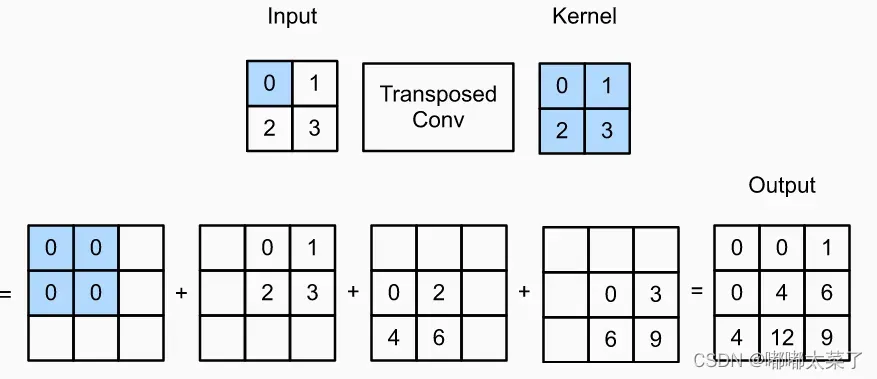
从一个简单的例子开始,如下图,输入为2×2,核大小为2×2,输入的每个数与核相乘,然后累加起来得到了3×3的输出,可以看到特征图变大了(3×3的输入经过2×2的卷积得到2×2的输出,转置卷积是卷积的逆操作)。
上面的转置卷积使得2×2的输入特征图变为3×3的输出特征图,能不能让输出特征图变得更大呢?显然可以,见下图,引入了步长后(下图的步长可以理解为输出特征图上的步长),输入特征图为2×2,核为2×2,输出特征图为4×4。
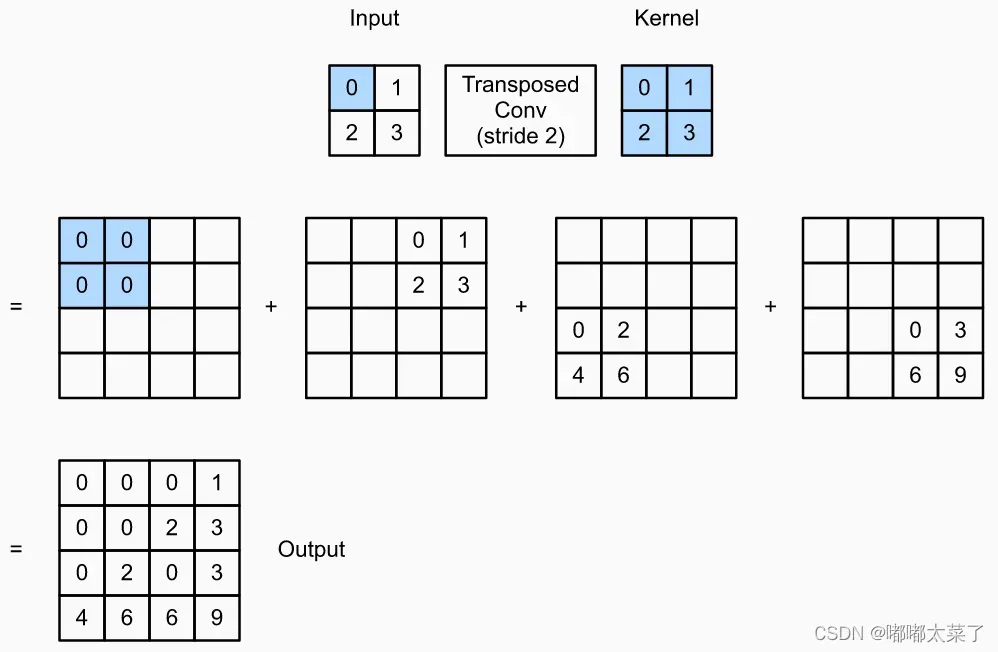
同理可以引入padding和dilation等参数,假设输入维度为,输出维度为
,转置卷积的维度计算公式为:
代码实践(输入特征图:[1, 3, 50, 50], 输出特征图: [1, 3, 98, 98]):
import torch
x = torch.rand(1, 3, 50, 50)
transpose_conv = torch.nn.ConvTranspose2d(3, 3, kernel_size=3, stride=2, padding=2, output_padding=1)
y = transpose_conv(x)
print(x.shape, y.shape)
# 输出:
# torch.Size([1, 3, 50, 50]) torch.Size([1, 3, 98, 98])5. 附录
所有示例代码
文章出处登录后可见!