文章目录

收录于CVPR2021 Image Matching Workshop,github地址:https://github.com/ufukefe/DFM
相识
图像配准(Image Registration)是计算机视觉领域中的一项重要任务,其旨在将不同角度/时间/模态等条件下获取的两张或多张图像进行匹配、叠加。图像匹配的核心在于找到每两幅图像间的对应关系(可以通过这个对应关系进行相互映射),更具体地说,是要找到图像点间的匹配关系,如下图所示:

该图展示了不同视角、光照、模态下的图像匹配关系可视化
目前采用深度学习进行图像配准的工作分为两个类型,一种是基于传统的图像匹配流程【特征检测、特征描述、特征匹配、转换参数估计】,这些工作专注于提升其中某个或几个模块的性能,例如SuperPoint、SuperGlue和D2-Net等;另一种是采用集成方式,直接输入两张图像得到对应关系,而不需要设计具体的检测、描述、匹配模块,代表工作有NCNet和Patch2Pix。
在实际应用中,基于传统匹配流程方法的性能通常受限于最差模块的表现[木桶效应],不同模块在不同场景下都有可能出错,而集成的方法可以避免这个问题。最近基于集成的方法也证明了,使用现成的模型【预训练的分类模型】作为特征提取器的有效性,从而简化了流程的简易性。
预训练的分类模型具有较好的语义抽象能力,它们在目标检测、图像分割上的成功也证明了其具有良好的定位能力
DFM这篇论文的核心动机在于:结合简单有效的策略,无需任何训练,直接使用现成特征提取器就能在图像配准任务中达到非常好的表现。论文主要采用两种策略:hierarchical search + coarse-to-fine,简单地说就是先基于深层语义特征计算匹配关系进行初步对齐,然后对初步对齐后的图像在不同层次特征上进行由粗到细地匹配,无需任何训练就能达到与SOTA方法相匹配甚至更优的性能。
相知
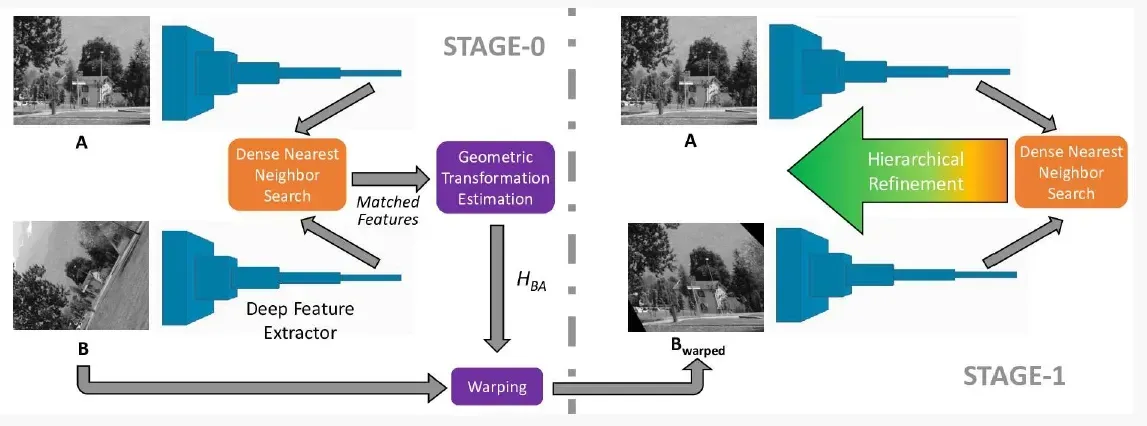
DFM采用如上图所示的两阶段结构进行图像匹配,采用预训练模型(例如在ImageNet预训练的VGG-19)提取深层特征图,计算匹配关系进行初步变换,然后在下一阶段采用coarse-to-fine的策略进行层次匹配。具体地说,在第0阶段(图左),使用深层特征空间的低分辨率特征图执行密集最近邻搜索(Dense Nearest Neighbor Search, DNNS),得到粗略转换关系以进行图像变换(warping)。在第1阶段(图右),使用参考图像和变换后的图像提取得到层次特征,从深层到浅层依次进行匹配优化(Hierarchical Refinement)。下面介绍DNNS和层次优化的细节:
a. 密集最近邻搜索DNNS
DNNS进行特征图间的密集匹配,即给定特征图Fa和Fb,DNNS对Fb进行搜索以找到Fa每个元素的最佳匹配。这个匹配过程会采用ratio test并进行双向匹配,raito test的意思是为每个元素找到最近邻和次近邻,只有最近邻距离/次近邻距离的比值小于设定阈值才算作一对成功匹配。此外,还需要进行双向匹配,即Fb相对Fa的匹配对也必须是Fa相对Fb的匹配对才行。
b. 层次优化 Hierarchical Refinement
深层的特征虽然对几何变换、亮度变换都非常鲁棒,但是它的定位准确性较差。因此直接根据深层匹配结果进行上采样会影响性能。一种简单的想法是,在浅层特征图上进行DNNS找到匹配对,但这会存在两个问题:
- 浅层特征图分辨率更大,导致DNNS计算量增加;
- 由于感受野的限制,浅层特征缺乏判别性语义特征,并存在一定重复性,这会导致误配。
Patch2Pix为了解决第二个问题,选择将各层次特征上采样至原始分辨率统一比较,但这加重了第一个问题。而DFM选择了一种coarse-to-fine的策略来解决这两个问题,也叫做层次优化(Hierarchical Refinement,HRA)。
具体来说,层次优化就是从深层到浅层逐步细化匹配结果。在HRA算法的每一步中,其会根据第n层的匹配结果去得到n-1层的匹配结果,HRA的核心思想在于:通过第n层的匹配结果来限制n-1层的搜索范围,即在有限的范围进行DNNS搜索。具体流程如下图所示:
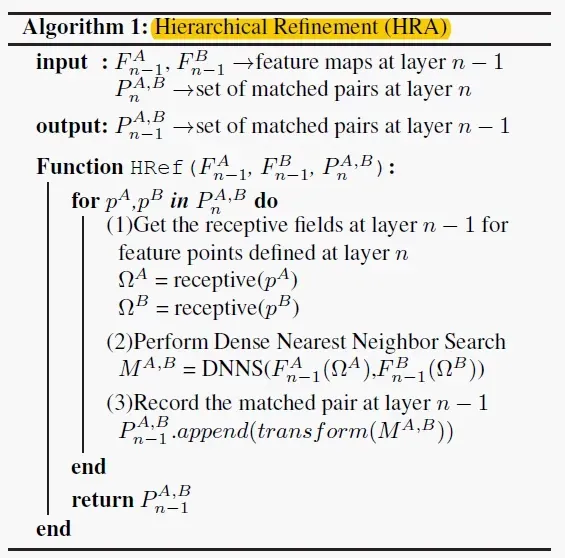
给定图像A、B在第n层的匹配结果数学公式: 以及第n-1层的特征图数学公式:
,遍历数学公式:
中每对匹配点。对于每对匹配点:① 先找到特征点相对n-1层的感受野数学公式:
;② 在对应感受野范围中执行DNNS找寻匹配点;③ 将找到的匹配点加入n-1层的匹配结果中。最后返回第n-1层的匹配结果数学公式:
。
在层次优化的每一步,都在筛选正常匹配、剔除异常匹配,从而最后得到精确的匹配。需要注意的是,经过每一步HRA,匹配对可能增多也可能减少。
讨论:为什么需要两阶段而不采用单阶段(即直接进行层次优化),而要先进行粗变换?
作者解释说网络浅层特征对于几何变换缺少鲁棒性,如果当场景中物体出现严重几何变换效果就会很差。即使能在深层特征图中能够找到正常的匹配也可能会因为浅层的失真导致错误匹配。
部分实验结果
(1)MMA评估
MMA反映了模型的预测匹配结果与实际匹配结果在不同距离阈值(1-10个像素点)下的平均匹配准确率(数据集提供了真实的homographies)
下图展示了DFM与其他方法在HPatches数据集上的MMA性能对比(并且区分了HPatches数据集中的光照和视角两种情况进行报告),可以看到DFM存在几组不同的报告,这是在匹配过程中设置了不同的ratio test,而s0+s1是两阶段过程,s0是单阶段过程。
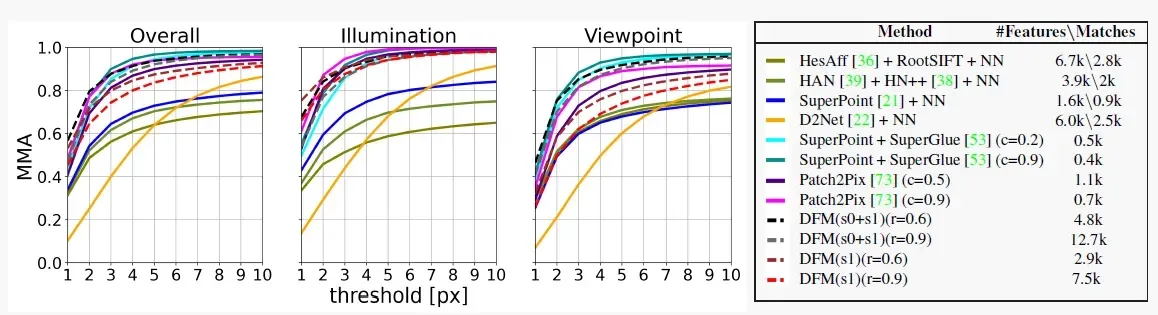
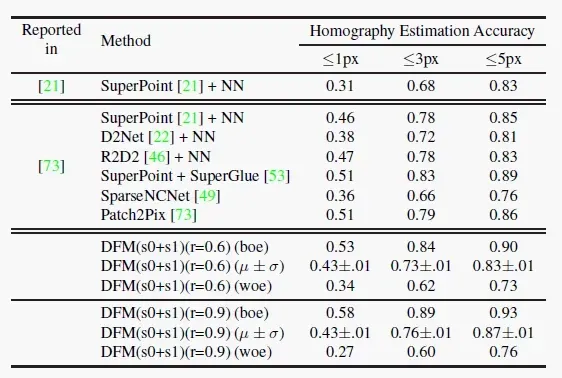
MMA的评估存在很多问题,比如它没有考虑到生成匹配对的数量、以及匹配区域的多样性等。如果一个方法为每幅图像生成了一组正确匹配对,那它的MMA将会是100%,但这显然无法应用到下游任务中。因此采用了一种新的评估方式,将参考图像根据匹配对估计的homography进行投影变换,计算四个角与真实图像之间的平均像素距离,报告在不同距离阈值下的平均准确率。
下图展示了不同方法在Homograhpy Estimation评估方式下的性能,可以看到DFM的效果还是很不错的。
回顾
本论文针对图像配准问题提出了一种新的基于深度学习的方法DFM,该方法无需任何训练,直接采用预训练的分类模型当做特征提取网络。为了同时兼顾语义信息和像素定位的准确性,DFM采用两阶段的方式,先用富含深层语义信息的特征信息进行粗略的变换,然后再通过从深到浅、由粗到细的层级匹配找到最终的匹配对。
相比之前基于稀疏特征的方法,这种方式能够提供更多精确的匹配对,这将有利于后续的应用。不过使用预训练模型会依赖原始模型训练的图像域,比如目前常用的模型都是ImageNet数据集上预训练的模型,如果下游任务与自然场景中差距较大可能会效果较差。
文章出处登录后可见!