什么是unet
一个U型网络结构,2015年在图像分割领域大放异彩,unet被大量应用在分割领域。它是在FCN的基础上构建,它的U型结构解决了FCN无法上下文的信息和位置信息的弊端
Unet网络结构
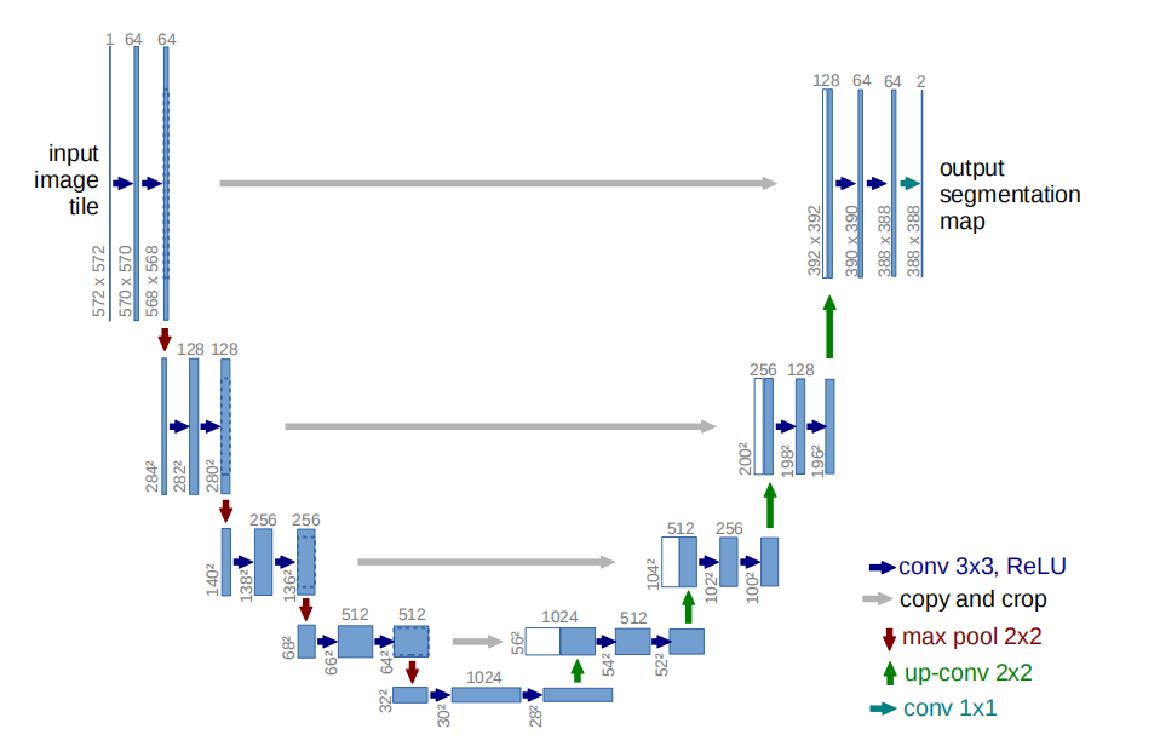
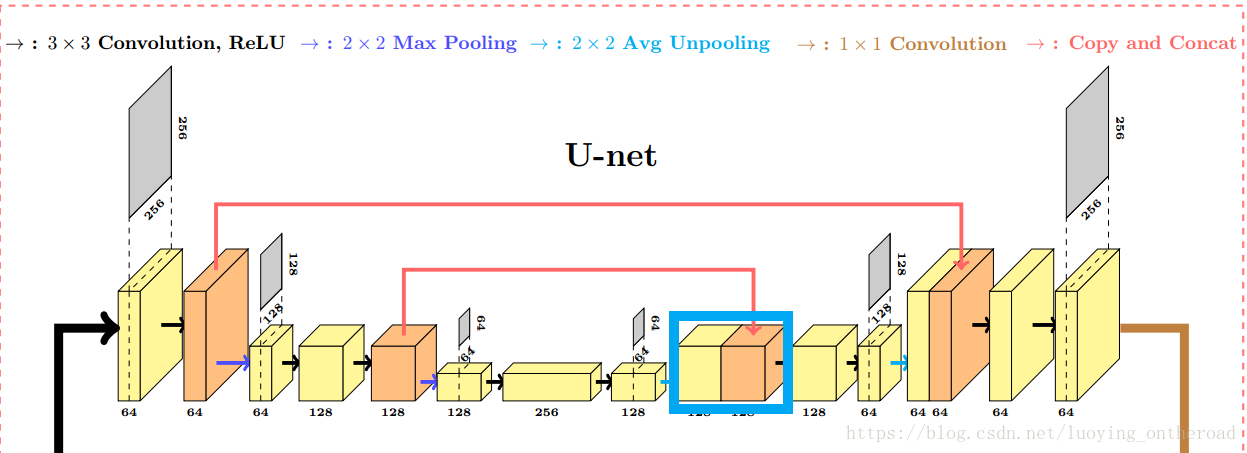
主干结构解析
左边为特征提取网络(编码器),右边为特征融合网络(解码器)
高分辨率—编码—低分辨率—解码—高分辨率
特征提取网络
高分辨率—编码—低分辨率
前半部分是编码, 它的作用是特征提取(获取局部特征,并做图片级分类),得到抽象语义特征
由两个3×3的卷积层(RELU)再加上一个2×2的maxpooling层组成一个下采样的模块,一共经过4次这样的操作
特征融合网络
低分辨率—解码—高分辨率
利用前面编码的抽象特征来恢复到原图尺寸的过程, 最终得到分割结果(掩码图片)
由一层反卷积+特征拼接concat+两个3×3的卷积层(ReLU)反复构成,一共经过4次这样的操作,与特征提取网络刚好相对应,最后接一层1*1卷积,降维处理,即将通道数降低至特定的数量,得到目标图,具体内容可以参考这篇文章 一文读懂卷积神经网络中的1×1卷积核
FCN与UNet特征融合操作对比解析
FCN是通过特征图对应像素值的相加来融合特征的
torch代码:
concat1 = out1+out2
# 其中out1与out2都是torch中的tensor格式
unet是通过同维度矩阵拼接来融合特征的
torch代码:
concat2 = torch.cat([convt1,conv4],dim=1)
# dim = 1 意味着在第1维度方向(第1维也就是列为4的方向)进行叠加
# 对于更高维的数据,也就是在dim = x 时,即x所对应维度方向进行叠加
UNet主要创新点
-
采取将低级特征图与后面的高级特征图进行融合操作
-
完全对称的U型结构使得前后特征融合更为彻底,使得高分辨率信息与低分辨率信息在目标图片中增加
-
结合了下采样时的低分辨率信息(提供物体类别识别依据)和上采样时的高分辨率信息(提供精准分割定位依据),此外还通过融合操作(跳跃结构)填补底层信息以提高分割精度.(分辨率就是图片的尺寸)
对高层语义特征与底层空间信息的理解
越底层的特征蕴含的空间信息(分割定位特征)更多,语义特征(就是类别判断特征,像素点可以分到哪一个类别中去)更少,越高级的特征蕴含的空间信息更少,语义特征更多
- 底层特征图片更偏向于组成图像的基本单元,如点,线,边缘轮廓

-
高层抽象的特征就更抽象,更近似于表示的是图像的语义信息

注:图片来源于神经网络可视化论文《Visualizing and Understanding Convolutional Networks》
UNet与FCN的比较
1.编解码结构
-
它们的结构都用了一个比较经典的思路,也就是编码和解码(encoder-decoder)结构,该结构早在2006年就被Hinton提出来发表在了nature上。当时这个encoder-decoder结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。这样的话我们存一幅图的时候就只需要存一个特征和一个解码器即可。同理,这个思路也可以用在原图像去噪,做法就是在训练的阶段在原图人为地加上噪声,然后放到这个编码解码器中,目标是可以还原得到原图。在UNet与FCN的目标任务中,是得到一张Mask掩码图,实现端到端(由图得到图),这与Hinton提出的编解码操作不谋而合。
-
和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的解码器部分相对简单,只用了一个反卷积的操作,之后并没有跟上卷积结构。
2.全卷积结构
- UNet和FCN一样, 是全卷积形式, 没有全连接层(即没有固定图的尺寸)——全连接层输入是提前固定好的,所以容易适应很多输入尺寸大小
3.跳跃结构,即特征融合操作
- UNet相比FCN,跳跃结构更多,更彻底,每一层下采样都与后面每一次上采样对应,一个经验的解释(大量实验)就是跳级连接能够保证特征更加精细
- UNet是拼接操作,而FCN是加操作
模型torch代码解析
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data
import torch
"""
构造上采样模块--左边特征提取基础模块
"""
class conv_block(nn.Module):
"""
Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
# 在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return x
"""
构造下采样模块--右边特征融合基础模块
"""
class up_conv(nn.Module):
"""
Up Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
"""
模型主架构
"""
class U_Net(nn.Module):
"""
UNet - Basic Implementation
Paper : https://arxiv.org/abs/1505.04597
"""
# 输入是3个通道的RGB图,输出是0或1——因为我的任务是2分类任务
def __init__(self, in_ch=3, out_ch=2):
super(U_Net, self).__init__()
# 卷积参数设置
n1 = 64
filters = [n1, n1 * 2, n1 * 4, n1 * 8, n1 * 16]
# 最大池化层
self.Maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# 左边特征提取卷积层
self.Conv1 = conv_block(in_ch, filters[0])
self.Conv2 = conv_block(filters[0], filters[1])
self.Conv3 = conv_block(filters[1], filters[2])
self.Conv4 = conv_block(filters[2], filters[3])
self.Conv5 = conv_block(filters[3], filters[4])
# 右边特征融合反卷积层
self.Up5 = up_conv(filters[4], filters[3])
self.Up_conv5 = conv_block(filters[4], filters[3])
self.Up4 = up_conv(filters[3], filters[2])
self.Up_conv4 = conv_block(filters[3], filters[2])
self.Up3 = up_conv(filters[2], filters[1])
self.Up_conv3 = conv_block(filters[2], filters[1])
self.Up2 = up_conv(filters[1], filters[0])
self.Up_conv2 = conv_block(filters[1], filters[0])
self.Conv = nn.Conv2d(filters[0], out_ch, kernel_size=1, stride=1, padding=0)
# 前向计算,输出一张与原图相同尺寸的图片矩阵
def forward(self, x):
e1 = self.Conv1(x)
e2 = self.Maxpool1(e1)
e2 = self.Conv2(e2)
e3 = self.Maxpool2(e2)
e3 = self.Conv3(e3)
e4 = self.Maxpool3(e3)
e4 = self.Conv4(e4)
e5 = self.Maxpool4(e4)
e5 = self.Conv5(e5)
d5 = self.Up5(e5)
d5 = torch.cat((e4, d5), dim=1) # 将e4特征图与d5特征图横向拼接
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((e3, d4), dim=1) # 将e3特征图与d4特征图横向拼接
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((e2, d3), dim=1) # 将e2特征图与d3特征图横向拼接
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((e1, d2), dim=1) # 将e1特征图与d1特征图横向拼接
d2 = self.Up_conv2(d2)
out = self.Conv(d2)
return out
参考文章:
https://blog.csdn.net/weixin_40519315/article/details/104408388
文章出处登录后可见!