1.摘要
- 提出了一种将几何3D形状表示为3D体素网格中的二值变量概率分布方法,然后用卷积深度网络进行处理。
- 不仅可以对3D形状进行操作,2.5D的深度图也可以处理,可以使用单视图的方法,也可以使用Next-Best-View 优化识别率。
- 构造了ModelNet,一个规模很大的CAD模型3D数据集,用于3D深度训练。
2.引言
- 本文探寻一种能够用于目标识别和形状补全的通用3D形状表示方法。
- 当类别识别的第一视角不足时,识别系统还需要寻找更好的观看视角。
3.相关工作
- Assembly-based approach
- Smooth interpolation-based approach
- Template-based approach
- Deep learning-based approach
- Next-Best-View problem
4.3D ShapeNets
3D voxel grid的构建可以参考此篇Blog。[0]
Convolutional Deep Belief Network (CDBN)的构建具有以下特点:
- 通过卷积权重共享减少模型参数。
- 不要使用任何池化操作(因为形状重建的不确定性很大)。

Convolutional Deep Belief Network (CDBN)的构建配置:
- 网格大小为30×30×30,在表示形状的时候,要在上下左右空出3个多余的格子,减少卷积边界的误差,所以目标形状的范围是24×24×24。
- 第一层:使用48个大小为6的卷积核,步数为2。
- 第二层:使用160个大小为5的卷积核,步数为2.
- 第三层使用512个大小为4的卷积核。
- 第四层:全连接,有1200个隐藏单元。
- 第五层:全连接,有4000个隐藏单元,输入为multinomial label variables和Bernoulli feature variables(不清楚说的是啥,看图是输入标签和第四层特征)
- 训练的时候采用一层一层的预训练模式,前四层的训练方式为standard Contrastive Divergence,后两层的训练方式为Fast Persistent Contrastive Divergence(FPCD)。
- 微调阶段使用wake sleep algorithm。第一层只学习感知域中非空的信号,还使用了sparsity regularization 。最后,we duplicate the label units 10 times to increase their significance.(不懂,有知道的小伙伴可以在评论区讨论一下)
4. 2.5D Recognition and Reconstruction
4.1 View-based Sampling
在训练完CDBN后,模型学习到了体素数据和目标类别
的联合分布函数
。尽管模型是在3D形状上训练的,但是能够识别2.5D的深度图。
将2.5D深度图转换为体素表示,分成free、surface和occluded三个部分。free和surface被认为是可见的,occluded是不可见的
,整体表示为
。
识别物体类别的任务可以表示为,通过Gibbs sampling进行求解,具体可以参考此篇Blog。步骤如下:[0]
- 将
初始化为一个随机值并自下而上传播数据样本
以从
获取标签
的样本。
- 然后,High level signal向下传播到体素
的采样。
中可见的体素
被截断并自下而上传播。
50次上下采样迭代应足以获得补全后的形状,以及对应的值
。上述步骤可以并行运行,从而产生与潜在不同类别相对应的各种补全结果。最后一个类别标签对应于采样频率最高的类别。
4.2 Next-Best-View Prediction
仅从一个角度识别目标是不稳定的,其他类型的都会被识别。如果能够给出当前视角,模型可以预测下一个视角将对识别目标类别产生巨大影响。
enter:
- 未知目标的单个可见体素
- 下一个视角的有限可选列表
(相机旋转和平移)
output:
- 从列表中选择最佳视图以降低识别不稳定性
原始识别不确定性 由以观察到的
为条件的
的熵给出:
其中条件概率 可以通过从
采样并边缘化
来近似。
当相机移动到另一个视图时,一些以前没有观察到的体素
根据其实际形状进行观察。不同的视图
将导致这些未观察到的体素
的可见性不同。
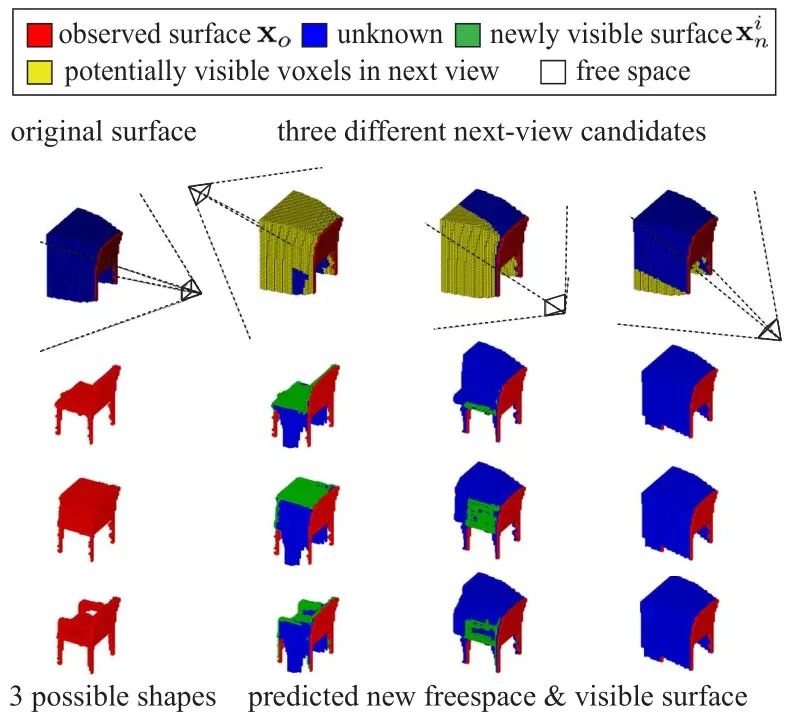
上图中,以为条件,可以采样到很多可能的形状,然后根据每个假设得到
视角下的深度图。通过这种方式,我们可以在不同的视角下为不同的样本模拟新的深度图。
让表示下一个视图下的新可见体素,
是在以下等式中将被边缘化的未知变量。不确定性表示为:
上式中的条件熵可以通过以下步骤计算:
- 从
采样足够的
- 做3D rendering,得到深度图,从
- 使用
计算
根据信息论,以
为条件,
和
之间的互信息。
因此,视角优化算法就是最大化这个互信息:
5.ModelNet: A Large-scale 3D CAD Dataset
数据源:
- 3D Warehouse
- 3D模型搜索引擎 Yobi3D
- SUN database
- Princeton Shape Benchmark
- 打标签工具 Amazon Mechanical Turk
共有660类,151128个3D模型。
6.实验
ModelNet40:40类,每类100个模型
ModelNet10:10类
每个模型沿着重力方向旋转12次(一次30°)
– 应对旋转不变性
共有48000 CAD 训练
one Intel XEON E5-2690 CPU
one NVIDIA K40c GPU
训练两天
6.1Classification and Retrieval
Classification,将第五层看作特征,再加一层线性SVM作为输出层,取每一类的平均值,对比的算法包括Light Field descriptor (LFD, 4,700 dimensions)、Spherical Harmonic descriptor (SPH, 544 dimensions)。
Retrieval,L2 distance被用于两种模型间的相似性。评价指标为recision-recall curve (AUC) 和mean average precision (MAP)。
38,400模型进行训练,9600个模型用于测试。
6.2 View-based 2.5D Recognition
NYU RGB-D dataset:10类, 4899个模型
先直接把在ModelNet上训练好的模型用在NYU数据集上
然后微调
6.2Next-Best-View Prediction
主要取决于形状重建的性能。
理所当然地,一个好的视图选择方案应该产生更高的识别精度。
7.总结
所提出的模型既可以识别又可以重构。
文章出处登录后可见!