1、数据分析
数据分为两部分,一部分为jpg格式的图片,另一部分为包含图片中所含的标签、锚框等信息的xml格式的标签数据。
2、数据导入
2.1位置提取
打开xml文件查看数据排布:
可以看出文件中包含了有用的信息,所以可以提取出这部分信息
import xml.etree.ElementTree as ET
def parse_rec(filename):
""" Parse a PASCAL xml file """
tree = ET.parse(filename)
width = int(tree.find('size').find('width').text)
height = int(tree.find('size').find('height').text)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(float(bbox.find('xmin').text)),
int(float(bbox.find('ymin').text)),
int(float(bbox.find('xmax').text)),
int(float(bbox.find('ymax').text))]
objects.append(obj_struct)
return objects, width, height
提取出来的数据分为两部分,第一部分为label信息,第二部分为该图片的大小
以上实现了label的信息的提取,但只能提取某一个xml文件的信息,我们需要将所有的xml的信息都提取出来,故要将所有的xml的文件位置都排列出来
import os
def pathlist(filename):
""" 输入图片所在的文件夹的位置 """
""" 最终得到的是图片和标签名一一对应的位置列表 """
path = os.listdir(filename)
img_path =[]
tar_path =[]
for i in path:
a = os.path.join(filename,i)
img_path.append(a)
""" 替换相匹配的xml的label文件的位置 ""
b = i.replace('jpg','xml')
f = os.path.join('Annotations/gesture/train/image',b)
tar_path.append(f)
return img_path,tar_path
如此便可以用循环遍历位置列表中的元素,提炼出每个xml中的可用信息,但是当出现有部分xml信息中不存在name、bbox的信息,这是由于在标注时部分图片没标注导致的,若图片数量不多,可直接将这部分图片忽略不用,即在位置列表中将缺失信息的图片删除。
lab_path = []
lab_path = tar_path
n = 0
m = 0
#删除
for i in tar_path:
a = parse_rec(i)
if a[0] == [] :
m += 1
del(lab_path[n])
del(img_path[n])
n +=1
print('删除了{}条数据缺失'.format(m))
#检测
b = 0
for i in lab_path:
a = parse_rec(i)
if a[0] == [] :
b +=1
if b == 0:
print('缺失数据删除完成!')
else:
print('还有{}条缺失数据'.format(b))
如果您还没有删除过一次,请再次运行它以将其删除。
2.2制作正标签
pytorch中有Dataset类,可以继承该类来以自己想要的形式来导入训练数据的形式
class myDataset(Dataset):
def __init__(self, img_path, tar_path, transform=None,size = 448):
'''其中img_path和img_label均为list'''
self.img_path = img_path
self.tar_path = tar_path
self.transform = transform
self.size = size
# 修改boundingbox格式,中心的偏移+宽高的归一化
def change_box_to_center_axes(self,bbox, width, height,stride = 64):
wb = width/self.size
hb = height/self.size
x0 = bbox[0]/stride/wb
y0 = bbox[1]/stride/hb
x1 = bbox[2]/stride/wb
y1 = bbox[3]/stride/hb
cx = (x0+x1)/2
cy = (y0+y1)/2
gridx = int(cx)
gridy = int(cy)
tx = cx-gridx
ty = cy-gridy
w = (bbox[2]-bbox[0])/width
h = (bbox[3]-bbox[1])/height
rebbox = [tx, ty, w, h,gridx,gridy]
return rebbox
# 合并成函数
def gernerate_targets(self,label_n,bbox, numclasses=24, S=7):
"""bbox的内容应该为[xc,yc,w,h]"""
VOC_CLASSES = (
'Two', 'Congratulation', 'Heart_single', 'OK',
'Heart_1', 'Nine', 'One', 'Four', 'Insult',
'Heart_3', 'ILY', 'Eight', 'Seven', 'Honour', 'Heart_2',
'Five', 'Thumb_up', 'Fist', 'Thumb_down', 'Three',
'Six', 'Rock', 'Prayer', 'Palm_up')
class_idx = VOC_CLASSES.index(label_n)
labels = np.zeros(24)
labels[class_idx] = 1
numelements = 5 + numclasses
targets = np.zeros((S, S, numelements))
tx, ty = bbox[0], bbox[1]
w, h = bbox[2], bbox[3]
x_idx = bbox[4]
y_idx = bbox[5]
target = []
target.extend(bbox[0:4])
target.append(1)
target.extend(labels)
targets[y_idx][x_idx] = target
targets = torch.tensor(targets).float()
return targets
'''根据下标返回数据(img和label)'''
def __getitem__(self, index):
img_fn = self.img_path[index]
tar_fn = self.tar_path[index]
img = Image.open(img_fn).convert('RGB')
features = parse_rec(tar_fn)
label_n = features[0][0]['name']
bbox = features[0][0]['bbox']
width, height = features[1], features[2]
bbox = self.change_box_to_center_axes(bbox, width, height)
targets = self.gernerate_targets(label_n,bbox)
img = self.transform(img)
return img,targets
'''返回数据集长度'''
def __len__(self):
return len(self.img_path)
对于图像的数据转换,我没有进行水平反转操作,因为我认为手势识别在转换图像后会改变它的含义,所以我不能进行太多的形状操作。
preprocess = transforms.Compose([
transforms.Resize((448,448)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
最后用DataLoader导入
train_data = myDataset(img_path,lab_path,preprocess)
train_loader=torch.utils.data.DataLoader(train_data,batch_size=10, shuffle=True,drop_last=True)
3、模型制作
模型我以以yolov1为理论基础,backbone为resnet18,进行改写适配该次实验,使其更适配
numclasses = 24
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
}
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, zero_init_residual=False):
super(ResNet, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
C_1 = self.conv1(x)
C_1 = self.bn1(C_1)
C_1 = self.relu(C_1)
C_1 = self.maxpool(C_1)
C_2 = self.layer1(C_1)
C_3 = self.layer2(C_2)
C_4 = self.layer3(C_3)
C_5 = self.layer4(C_4)
return C_5
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
# strict = False as we don't need fc layer params.
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']), strict=False)
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']), strict=False)
return model
class SPP(nn.Module):
"""
Spatial Pyramid Pooling
"""
def __init__(self):
super(SPP, self).__init__()
def forward(self, x):
x_1 = torch.nn.functional.max_pool2d(x, 5, stride=1, padding=2)
x_2 = torch.nn.functional.max_pool2d(x, 9, stride=1, padding=4)
x_3 = torch.nn.functional.max_pool2d(x, 13, stride=1, padding=6)
x = torch.cat([x, x_1, x_2, x_3], dim=1)
return x
class Conv(nn.Module):
def __init__(self, c1, c2, k, s=1, p=0, d=1, g=1, act=True):
super(Conv, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(c1, c2, k, stride=s, padding=p, dilation=d, groups=g),
nn.BatchNorm2d(c2),
nn.LeakyReLU(0.1, inplace=True) if act else nn.Identity()
)
def forward(self, x):
return self.convs(x)
class myYOLO(nn.Module):
def __init__(self, device='cuda', num_classes=24, trained=True):
super(myYOLO, self).__init__()
self.device = device
self.num_classes = num_classes
self.backbone = resnet18(pretrained=trained)
c5 = 512
self.neck = nn.Sequential(
SPP(),
Conv(c5 * 4, c5, k=1),
)
self.head = nn.Sequential(
Conv(c5, 256, k=1),
Conv(256, 512, k=3, p=1),
Conv(512, 256, k=1),
Conv(256, 512, k=3, p=1)
)
self.pred = nn.Sequential(nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.Conv2d(256, 5 + numclasses, kernel_size=3, stride=2, padding=1, bias=False)
)
def forward(self, x, target=None):
x = self.backbone(x)
x = self.neck(x)
x = self.head(x)
x = self.pred(x)
# B,C,W,H -> B,W,H,C
x = x.permute(0, 2, 3, 1)
x[:, :, :, 0:5] = torch.sigmoid(x[:, :, :, 0:5])
return x
4、loss函数制作
由于对yolov1进行了升级,预测框由两个改为了1个,loss函数也会相应的升级
class YoloV1Loss(nn.Module):
def __init__(self, s=7, b=1, l_coord=5, l_noobj=0.5,
device=torch.device('cuda')):
super(YoloV1Loss, self).__init__()
self.s = s # 正方形网格数
self.b = b # 每个格的预测框数
self.l_coord = l_coord # 损失函数坐标回归权重
self.l_noobj = l_noobj # 损失函数类别分类权重
self.device = device
def forward(self, predict_tensor, target_tensor):
"""
:param predict_tensor:
(tensor) size(batch_size, S, S, Bx5+20=30) [x, y, w, h, c]---预测对应的格式
:param target_tensor:
(tensor) size(batch_size, S, S, 30) --- 标签的准确格式
:return:
"""
N = predict_tensor.size()[0]
coo_mask = target_tensor[:, :, :, 4] > 0 # coo_mask.shape = (bs, 7, 7)
noo_mask = target_tensor[:, :, :, 4] == 0
# 得到含物体的坐标等信息(coo_mask扩充到与target_tensor一样形状, 沿最后一维扩充)
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor)
# 得到不含物体的坐标等信息
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)
# coo_pred:tensor[, 30](所有batch数据都压缩在一起)
coo_pred = predict_tensor[coo_mask].view(-1, 29)
# box[x1,y1,w1,h1,c1], [x2,y2,w2,h2,c2]
box_pred = coo_pred[:, :5].contiguous().view(-1, 5)
# class[...]
class_pred = coo_pred[:, 5:]
coo_target = target_tensor[coo_mask].view(-1, 29)
box_target = coo_target[:, :5].contiguous().view(-1, 5)
class_target = coo_target[:, 5:]
# compute not contain obj loss
noo_pred = predict_tensor[noo_mask].view(-1, 29)
noo_target = target_tensor[noo_mask].view(-1, 29)
# noo pred只需要计算 Obj1、2 的损失 size[,2]
noo_pred_mask = torch.ByteTensor(noo_pred.size()).to(self.device)
noo_pred_mask.zero_()
noo_pred_mask[:, 4] = 1
noo_pred_mask = noo_pred_mask.bool()
# 获取不包含目标框的置信度值
noo_pred_c = noo_pred[noo_pred_mask]
noo_target_c = noo_target[noo_pred_mask]
# 不含object bbox confidence 预测
nooobj_loss = F.mse_loss(noo_pred_c.to(torch.float32), noo_target_c.to(torch.float32), reduction='sum')
# 包含目标box confidence的损失
contain_loss = F.mse_loss(box_pred[:, 4].to(torch.float32), box_target[:, 4].to(torch.float32), reduction='sum')
# 包含目标box的损失
loc_loss = (F.mse_loss(box_pred[:, :2].to(torch.float32),
box_target[:, :2].to(torch.float32),
reduction='sum') +
F.mse_loss(torch.sqrt(box_pred[:, 2:4]).to(torch.float32),
torch.sqrt(box_target[:, 2:4]).to(torch.float32),
reduction='sum'))
# 3.class loss(分类损失)
class_loss = F.cross_entropy(class_pred.to(torch.float32), class_target.to(torch.float32), reduction='sum')
return (self.l_coord * loc_loss + 2 * contain_loss +
self.l_noobj * nooobj_loss + class_loss) / N,class_loss/N
5、训练
培训部分,即定期培训
#更新学习率
def set_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = myYOLO()
net.to(device)
# 超参数设置
EPOCH = 50 # 遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
LR = 0.001 #学习率
# 定义损失函数和优化方式
# 优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
criterion = YoloV1Loss(device = device)
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 训练
print("Start Training!")
net.train()
num_iters = 0
#采用多精度混合训练
scaler = torch.cuda.amp.GradScaler()
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
class_loss = 0.0
correct = 0.0
total = 0
#每10个epoch LR小10倍
if np.mod(epoch,10) == 0:
LR = LR*0.1
set_lr(optimizer, LR)
for i, data in enumerate(train_loader, 0):
num_iters += 1
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 清空梯度
# forward + backward
with torch.cuda.amp.autocast():
outputs = net(inputs)
loss,loss2 = criterion(outputs,labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
sum_loss += loss.item()
class_loss += loss2.item()
total += labels.size(0)
# 每20个batch打印一次loss和准确率
if (i + 1) % 20 == 0:
print('[epoch:%d, iter:%d] SumLoss: %.05f ClassLoss: %.05f'
% (epoch + 1, num_iters, sum_loss / (i + 1),class_loss / (i + 1)))
print("Training Finished, TotalEPOCH=%d" % EPOCH)
6、结果
训练样本4300张图片除去十多张伪标注的部分,训练集的精确度为99.7%,
测试集的800张左右的图片也能达到86%以上的精确度!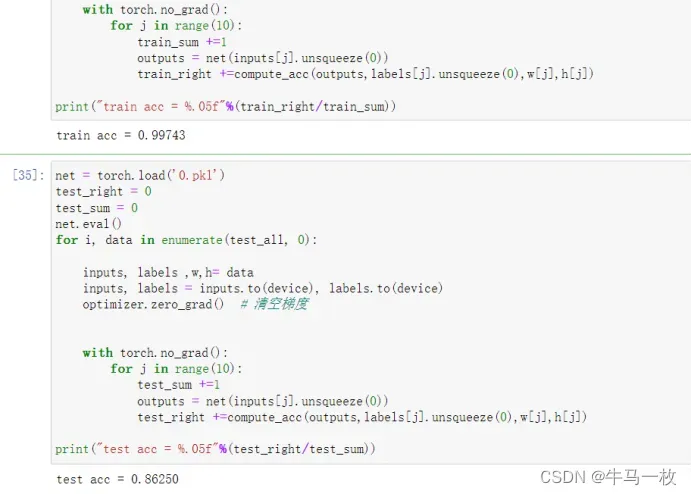
这是一帧视频预测的结果:
7、结语
以上就是这个手势识别的过程,剩下的评测过程没有组织,因为比较分散,所以不会难看,虽然上面的部分没有组织,有点乱。
如果需要我整理所有内容,一站式一键运行结果,支持我,我整理好放到网盘里供大家提取!但是,我认为如果您麻烦自己,可以复制上述部分。
文章出处登录后可见!