文章来源 | 恒源云社区
原文地址 | 论文小记
原文作者 | Mathor
这几天忙里偷闲去社区看了看各位版主一开始发的文章。重点找了我最喜欢的版主Mathor的文章,仔细一查,竟然已经发了90多篇,不愧是社区大佬本佬了!
想着看都看了,那就顺手搬运一下大佬的文章吧!
接下来跟着小编的脚步👣,一起看下去吧~
正文开始
EMNLP2021 Findings上有一篇名为TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning的论文,利用Transformer结构无监督训练句子编码,网络架构如下所示:
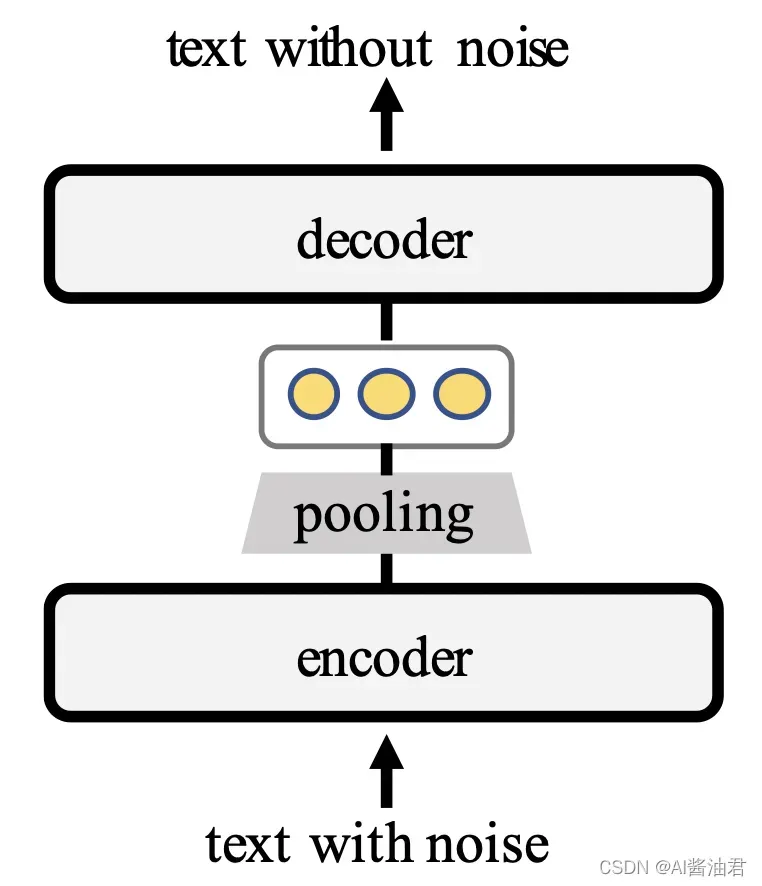
具体来说,输入的文本添加了一些确定的噪声,例如删除、交换、添加、Mask一些词等方法。Encoder需要将含有噪声的句子编码为一个固定大小的向量,然后利用Decoder将原本的不带噪声的句子还原。说是这么说,但是其中有非常多细节,首先是训练目标
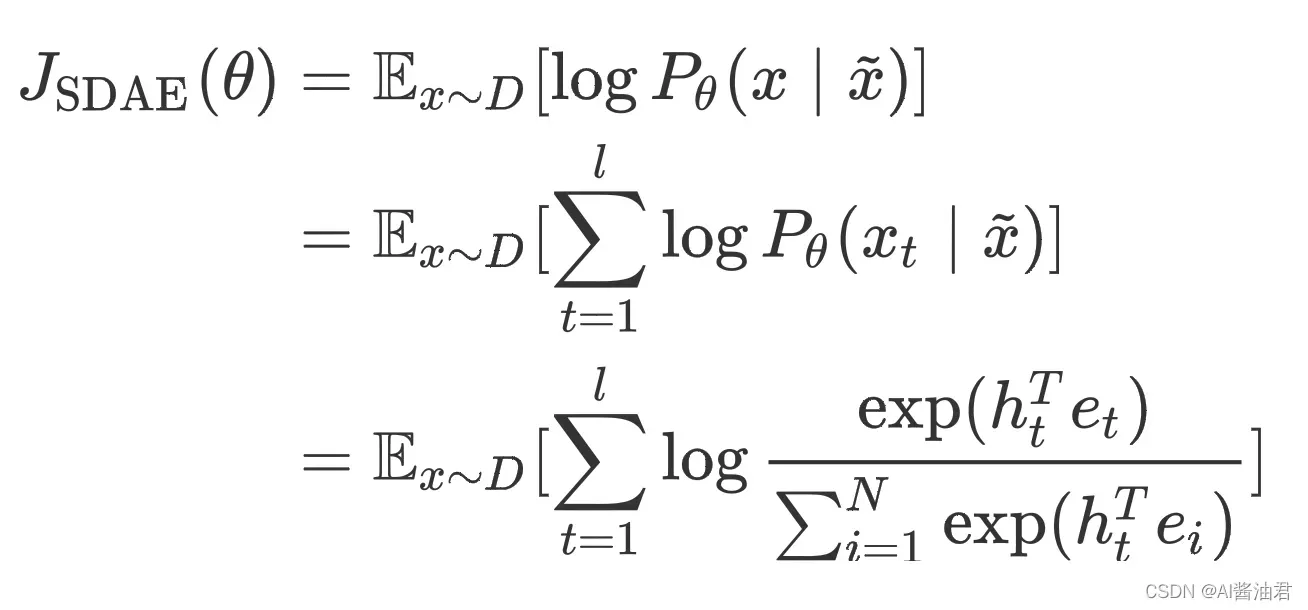
其中,是训练集;
是长度为lll的输入句子;
是
添加噪声之后的句子;
是词
的word embedding;
为Vocabulary size;
是Decoder第
步输出的hidden state
不同于原始的Transformer,作者提出的方法,Decoder只利用Encoder输出的固定大小的向量进行解码,具体来说,Encoder-Decoder之间的cross-attention形式化地表示如下: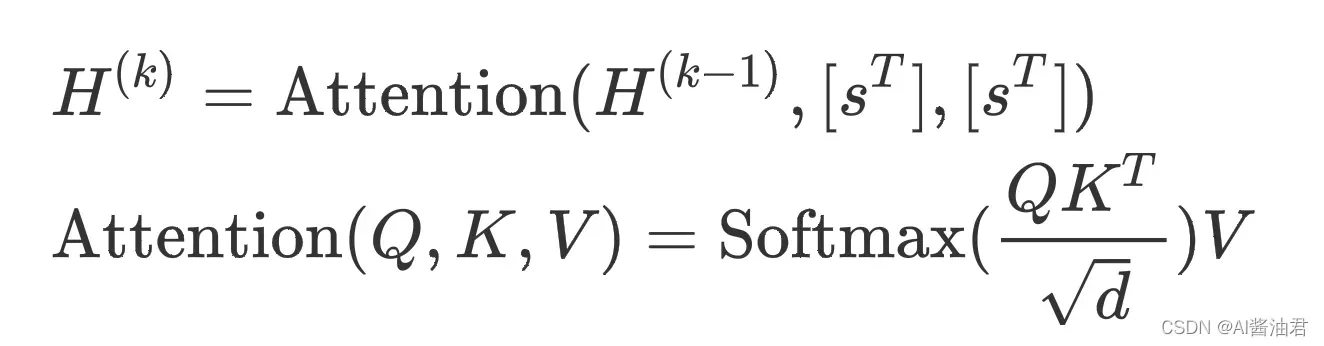
其中,是Decoder第
层
个解码步骤内的hidden state;
是句向量的维度(Encoder输出向量的维度);
是Encoder输出的句子(行)向量。从上面的公式我们可以看出,不论哪一层的cross-attention,
和
永远都是
,作者这样设计的目的是为了人为给模型添加一个瓶颈,如果Encoder编码的句向量
不够准确,Decoder就很难解码成功,换句话说,这样设计是为了使得Encoder编码的更加准确。训练结束后如果需要提取句向量只需要用Encoder即可
作者通过在STS数据集上调参,发现最好的组合方法如下:
- 采用删除单词这种添加噪声的方法,并且比例设置为60%
- 使用[CLS]位置的输出作为句向量
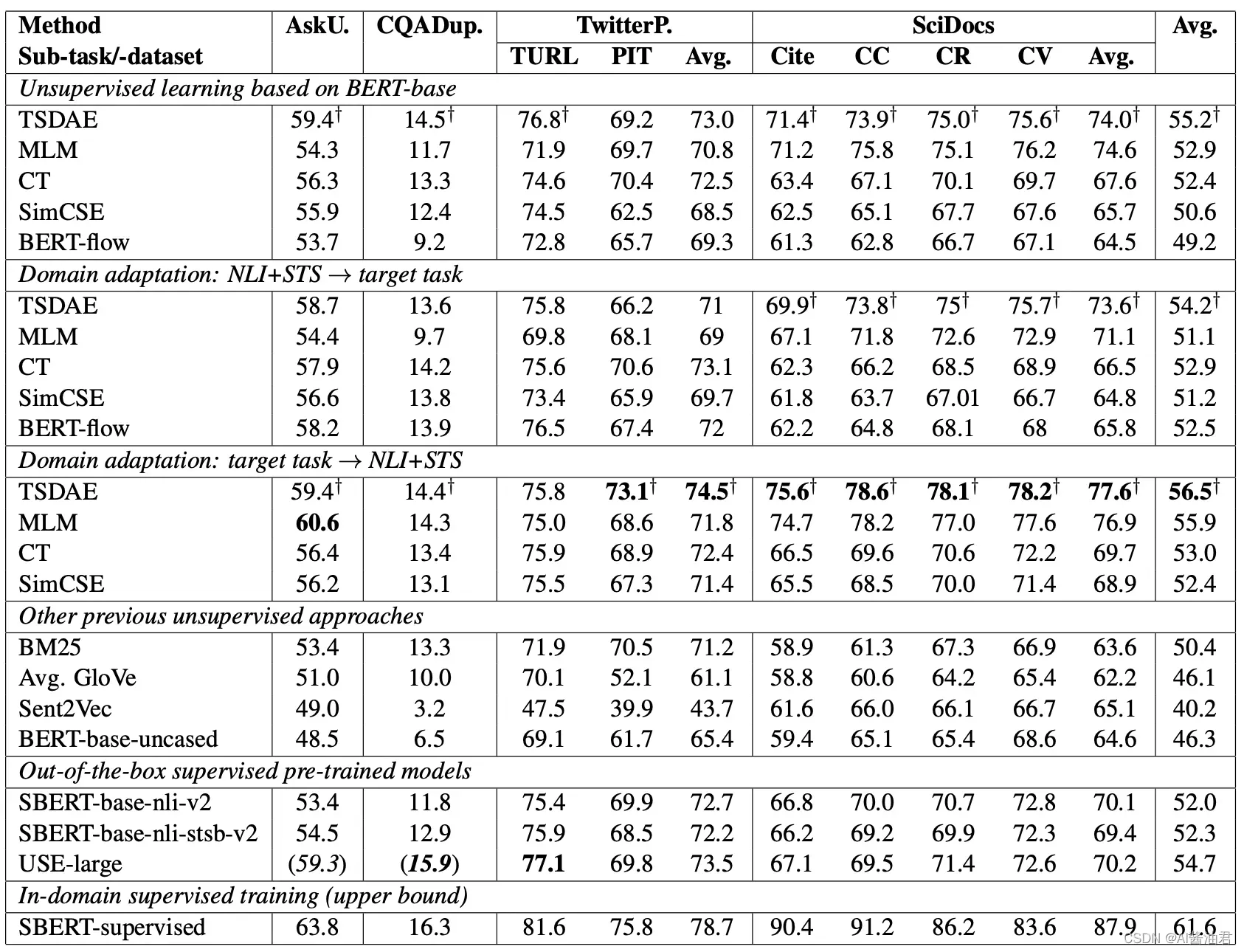
RESULTS
从TSDAE的结果来看,基本上是拳打SimCSE,脚踢BERT-flow
个人总结
如果我是reviewer,我特别想问的一个问题是:“你们这种方法,与BART有什么区别?”
论文源码在UKPLab/sentence-transformers/,其实sentence-transformers已经把TSDAE封装成pip包,完整的训练流程可以参考Sentence-Transformer的使用及fine-tune教程,在此基础上只需要修改dataset和loss就可以轻松的训练TSDAE
# 创建可即时添加噪声的特殊去噪数据集
train_dataset = datasets.DenoisingAutoEncoderDataset(train_sentences)
# DataLoader 批量处理数据
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# 使用去噪自动编码器损失
train_loss = losses.DenoisingAutoEncoderLoss(model, decoder_name_or_path=model_name, tie_encoder_decoder=True)
# 模型训练
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
weight_decay=0,
scheduler='constantlr',
optimizer_params={'lr': 3e-5},
show_progress_bar=True
)
版权声明:本文为博主AI酱油君原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_53977063/article/details/122580449