1. ResNext
Xie, Saining, et al. “Aggregated residual transformations for deep neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
多分支结构是Inception中提出的,然而在Inception中每个分支的结构都不太一样,因此这为网络结构的设计带来了很多麻烦。作为类Inception模型的工作,在这篇ResNext的文章中也采用了split-transform-merge strategy(由1×1卷积降维,再由3×3或者5×5的卷积进一步提取特征,最后拼接各分支的特征),然而作者认为在多分支中采用相同的结构能够大大简化网络的设计并且简单的设计能够大大降低结构风险(文中作者举了VGG的例子来阐述这一观点,因为VGG之前的AlexNet设计太过于混乱),因此,神经网络的设计应当遵循简单易懂的原则,而不是堆叠各种复杂的模块。
首先文章提出了一个新的名词:cardinality。这是一个新的超参数,指的是分支的路径数。并且作者认为增加路径数有利于提高图像分类的精确度,同时不同于一味增加网络的深度,增加分支能够更加有效率。
值得注意的是,cardinality这个名词很容易和width相混淆,后者指的是一个瓶颈块(bottleneck)中中间的卷积层的输出通道数。通常的瓶颈块总是先对通道维降维再升维。
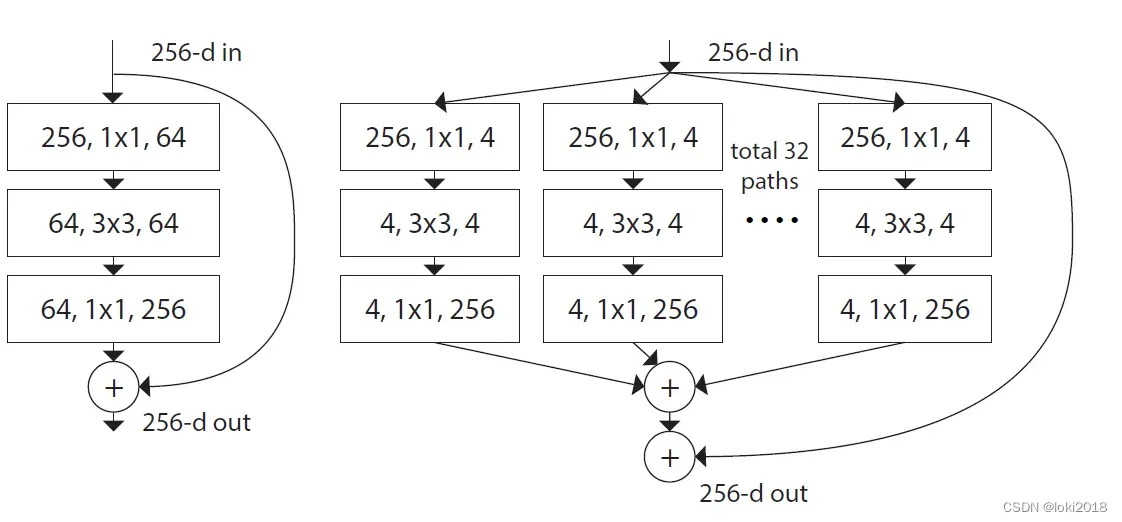
如上图所示,左边是ResNet块,右边是ResNext块,其中cardinality值为32,每个分支的width是4,最后也采用了一个残差连接。两者唯一不同的就是分支的设计。
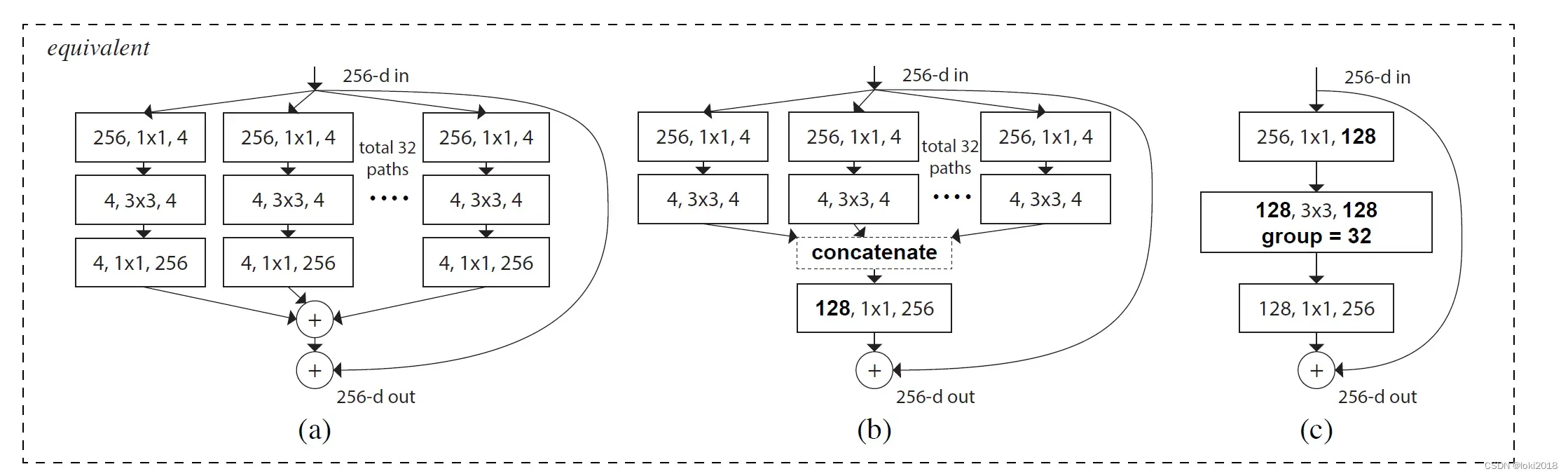
作者还给出了三种等价结构,(a) 中各分支最后输出的通道数都是256,最后逐一相加即可,但是这种方式计算量较大, (b)中各分支只输出最终通道数的一部分,最后将它们拼接到一起,(c)和(b)并无太多区别,只是将中间的过程改为了分组卷积的形式,分组卷积可以大大减少参数量。
2. 代码
import torch
import torch.nn as nn
import torchvision
from torch.utils import data
import matplotlib.pyplot as plt
import copy
import math
def conv1x1(in_channels, out_channels, stride=1, groups=1, bias=False):
# 1x1卷积操作
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=stride, groups=groups, bias=bias)
def conv3x3(in_channels, out_channels, stride=1, padding=1, dilation=1, groups=1, bias=False):
# 3x3卷积操作
# 默认不是下采样
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, stride=stride, padding=padding, dilation=dilation,
groups=groups,bias=bias)
class ResNextBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, stride, cardinality, bottleneck_width):
# cardinality : 分支数
# bottleneck : 每个分支的通道数
super(ResNextBottleneck, self).__init__()
mid_channels = in_channels // 4
D = int(math.floor(mid_channels * (bottleneck_width / 64.0)))
group_width = cardinality * D
self.conv1 = conv1x1(
in_channels=in_channels,
out_channels=group_width
)
self.conv2 = conv3x3(
in_channels=group_width,
out_channels=group_width,
stride=stride,
groups=cardinality
)
self.conv3 = conv1x1(
in_channels=group_width,
out_channels=out_channels
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
class ResNextUnit(nn.Module):
def __init__(self, in_channels, out_channels, stride, cardinality, bottleneck_width):
super(ResNextUnit, self).__init__()
self.resize_identity = (in_channels != out_channels) or (stride != 1) # 残差连接是否改变形状
self.body = ResNextBottleneck(
in_channels = in_channels,
out_channels = out_channels,
stride = stride,
cardinality = cardinality,
bottleneck_width = bottleneck_width
)
if self.resize_identity:
self.identity_conv = conv1x1(
in_channels=in_channels,
out_channels=out_channels,
stride=stride
)
self.activ = nn.ReLU(inplace=True)
def forward(self, x):
if self.resize_identity:
identity = self.identity_conv(x)
else:
identity = x
x = self.body(x)
x = x + identity
return self.activ(x)
文章出处登录后可见!