LeViT是FAIR团队发表在ICCV2021上的成果,是轻量级ViT模型中的标杆,文章对ViT中多个部件进行的改进,如加速策略等,对很多工程化铺设ViT系列模型都是很有借鉴意义的。
按说,近期出现的优质模型非常多,各种冲击SOTA的,详情可戳我整理的小综述《盘点2021-2022年出现的CV神经网络模型》。但我为何会单独对LeViT拿出来进行详细剖析呢?原因很简单:LeViT非常工程实用,是一款足够优秀的轻量级视觉transformer模型。市面上很多轻量级模型都进入了一个误区:大家都在比拼FLOPs数和参数数量。却忽略了工程上最直观的评价标准Inference Speed。
首先要知道一个前提就是,无论是FLOPs还是parameters数量,都与inference speed并不成线性关系。
先来看一组数据: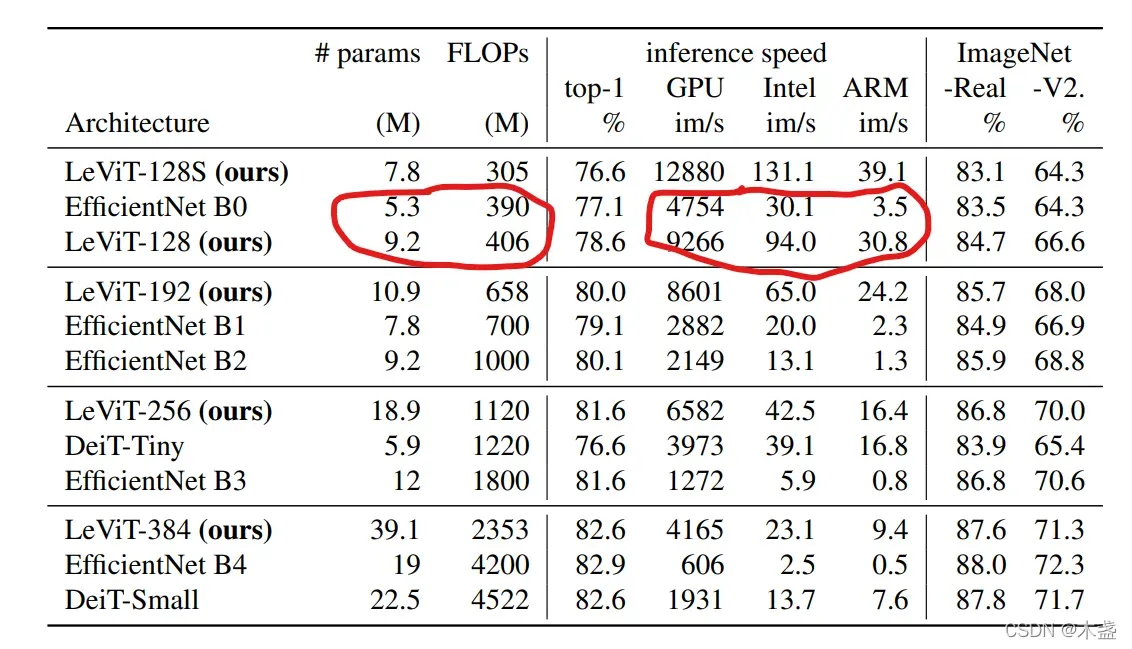
即使EfficientNet B0跟LeViT-128有着接近的FLOPs和params,甚至前者这两项数据更优秀,但推理速度后者可以在GPU上快2倍,CPU上快3倍,ARM CPU上快乐近10倍。看过这个数据,你是否对LeViT有了兴趣呢?
按照惯例:
论文标题(链接):LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference
Github:https://github.com/facebookresearch/LeViT
LeViT
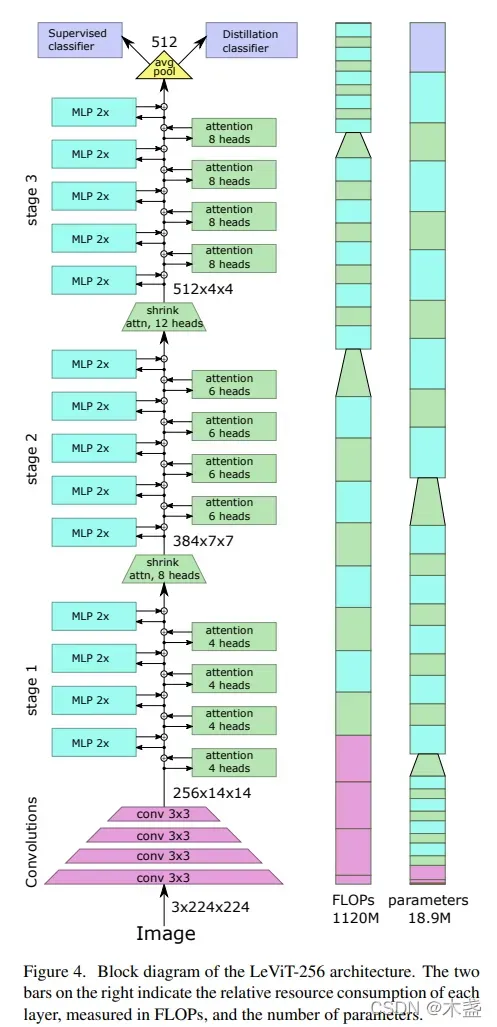
LeViT的结构如上图所示,很像一个火箭形状。这也是LeViT的特点之一:快速缩小特征图。这里的关键点在“特征图”,对,LeViT的思想里淡化了transformer中“token”的概念,引入了CNN中activation map(特征图)的概念。所以,大致按对待CNN的思路来对待LeViT会更有助于理解这个模型,比如最后加的那个average pooling。
图1咱们从下看到上,
1. 用CNN代替“划片”
这里用到了4层卷积层,每层的步长都是2,这样不需要使用pooling也能完成特征图下缩。在这一步,下缩幅度非常sharp,用4层就缩小了16倍的边长。而ResNet-18缩小到这个尺寸用了10层。如此sharp的尺寸下缩,使得送到self-attention模块的size就非常小了,有助于加速模型。
3x224x224 -> 256x14x14
输出为256x14x14的特征图,咱们用attention的角度理解:256个通道,每个通道14×14个token。咱们要知道self-attention的计算次数跟token数呈二次线性相关(知识点),所以token数太大对自注意力计算非常unfriendly。所以,轻量级ViT的思路肯定是尽量减小输入到self-attention模块之前的token数的。
用Conv layers代替无交集划片有几个优势:1. 可以进行初步的特征提取;2. 保留相对位置信息,可以不用在这个部分进行位置编码。
2. 用BN代替LN
transformer里最流行的norm方法就是LN,在很多论文的实验中都表明用LN比BN可以带来更多的准确率提升。而LeViT作者认为,LN比BN在准确率提升的作用上很有限,但LN比BN在计算上慢一些。
文章里对BN为何更快的解释如下:在inference的时候,BN计算可以融合到卷积里,几乎不会额外带来计算负担。(这点我附议,在TensorRT实验的时候可以看到BN的参数都固化下来了,而且前段时间的RepVGG也有融合BN到CNN中的操作。)
原文描述如下:
The batch normalization can be merged with the preceding convolution for inference, which is a runtime advantage over layer normalization (for example, on EfficientNet B0, this fusion speeds up inference on GPU by a factor 2).
3. 多分辨率金字塔
这个trick就描述了LeViT整个火箭型的结构,每过一个block,activation maps的尺寸都会减小,从开始的14×14到后面的4×4。
4. 具有收缩特征图尺寸作用的self-attention模块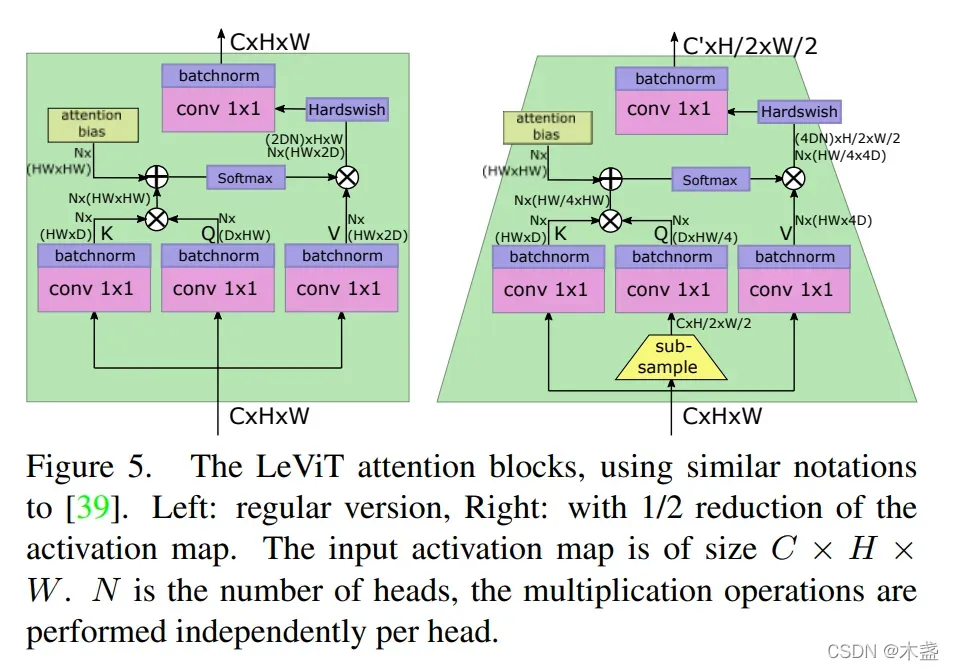
如Figure 5所示,咱们只需要关注输入输出的size,左边是正常的自注意力模块,右边是带特征图下缩的自注意力模块。通过在Q的计算里引入下采样来实现。
5. 采用维度更小的key
在原始ViT里面,K、Q、V都有一样的维度。实际上V可以保持大一点的维度,我们可以认为V承载了token的主要信息。而key可以看做是更高层的抽象,所以采用更小的key维度也并不影响模型效果。另外,我们看self-attention计算公式,会发现才是self-attention计算的大头,如果shrink一下key的维度,那自注意力模块的计算效率将会大大提升。
6. 采用注入attention的可学习位置编码
这就是LeViT一个很优秀的创新了。传统的ViT位置编码只在划片时候,以人工定义的位置矩阵来进行位置编码。但是LeViT作者认为,token的相对位置不仅在最开始很重要,在每一层attention模块都很重要。所以,采用一种注入self-attention计算的位置编码,咱们看图: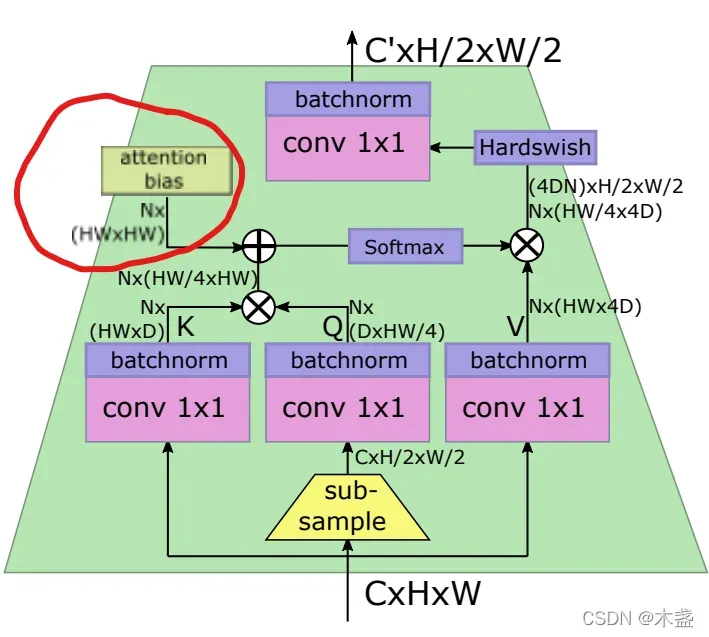
就是这个位置,用Attention Bias来代替Position Embedding(划重点)。
看一下公式: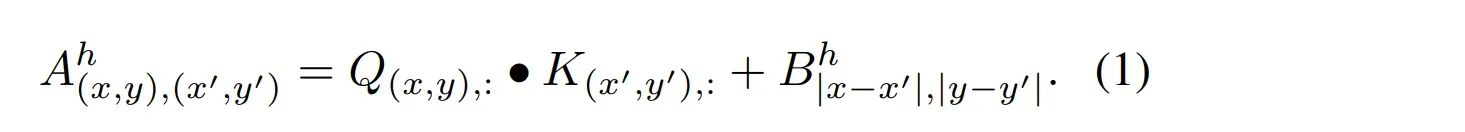
就是在QK乘法之后加上一个bias常数,这个bias是对称的、可学习的。
7. 蒸馏学习
蒸馏学习是指采用一个teacher模型来训练student模型。最开始将distillation思想用到ViT的模型是DeiT,而LeViT就是DeiT的改进版。
transformer引入CV领域之后有个很大的缺点迟迟没有被解决,那就是transformer不够Data Efficient。相比CNN,ViT对训练数据更加依赖,要达到CNN的SOTA,ViT需要用更多的数据以及需要更多的训练周期。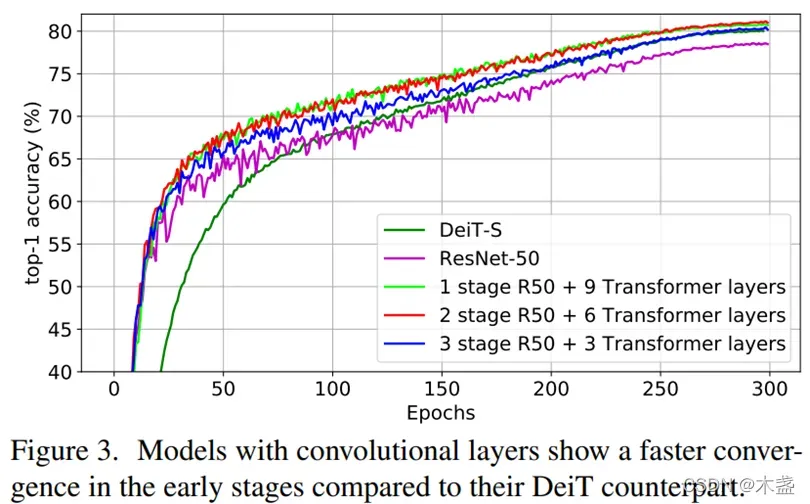
咱们看上图,DeiT的收敛比ResNet要慢很多,而且CNN比例越高,模型收敛越快。
这个原因很好解释:(下图是我自己画的)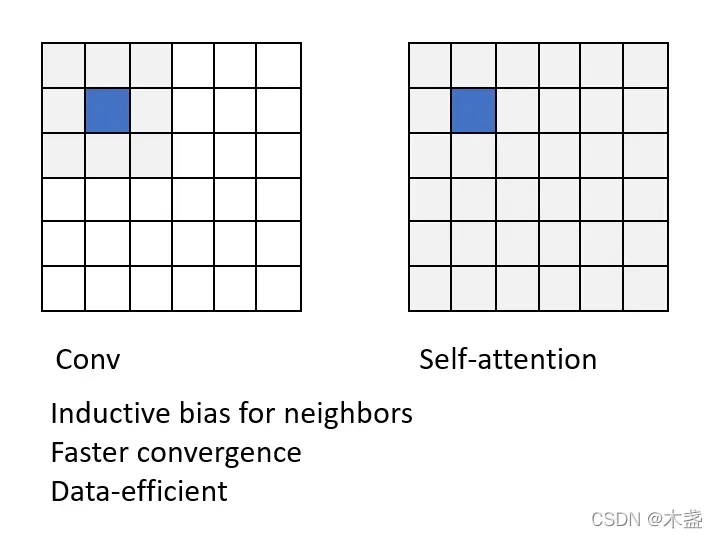
卷积的优势是自带对neighbors的归纳偏执,所以收敛更快,但缺乏global性;
self-attention的优势是global性,但本身处理单元时,在初始状态下会对所有token“一视同仁”。如上图所示,self-attention比Conv天生有更大的解空间。
因此,有必要引入蒸馏训练。
蒸馏训练是找个well-trained的CNN当做teacher model,然后用LeViT一方面跟Ground Truth做CE loss,一方面跟CNN的输出distribution做一个CE loss。这样可以用CNN来引导LeViT来加快收敛,这样就可以做到data-efficient了。
LeViT用到的teacher model是RegNetY-16G。
咱们看一下loss function就一目了然了:
上面截图来自DeiT的论文,蒸馏loss分为软蒸馏和硬蒸馏两种。通常用的都是硬蒸馏。
版权声明:本文为博主木盏原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/leviopku/article/details/123173848