前面说了注意力机制的工作原理,本次来看看为了实现自注意力机制,Q K V矩阵是如何实现的。
白话transformer(二)
1、语义相似性
我们在前面说了,embedding的作用就是相似的单词会被赋予相似的数字,那么我们是如何来计算语义的相似度的呢?

相似性其实是我们用来单词之间相似性的标准,我们希望有一种测量的方法使得可以用一些客观表示来形容相似度。
我们在这里介绍三种可以计算语义相似度的方法
1.1 点积
点积(dot product),又称内积(inner product),是两个向量的运算,结果是一个标量(一个单一的数值)。在数学、物理和计算机科学中,点积是一种基础且重要的运算。
对于两个向量 和
,它们的点积定义为:
即两个向量的对应分量相乘后再求和。
点积具有以下性质:
- 交换律:
- 分配律:
- 标量乘法:
,其中
是一个标量。
- 与向量长度和夹角的关系:点积还可以表示为两个向量的长度(或模)和它们之间夹角的余弦值的乘积,即
,其中
是向量
和
之间的夹角。

比如我们这里有一个坐标轴,水平轴表示科技属性,垂直方向表示水果属性;我们要计算他们的点积就需要求出他们的坐标,分别进行对应的坐标值相乘,后在相加得到点积

1.2 余弦相似度
余弦相似度(Cosine Similarity)是一种度量两个向量在方向上相似性的方法,它衡量的是两个向量在多维空间中的夹角余弦值。余弦相似度取值范围在[-1,1]之间,值越接近1,表示两个向量的方向越相似;值越接近-1,表示两个向量的方向越相反;值接近0,表示两个向量近乎正交,方向几乎无关。
假设有两个向量A和B,它们的点积(内积)定义为:
其中, 和
分别是向量A和B的欧几里得范数(即长度),
是向量A和B之间的夹角。
余弦相似度则定义为:
如果向量A和B都是单位向量(长度为1的向量),那么余弦相似度的计算可以简化为它们的点积,因为 ( |A| = |B| = 1 )。
在实际应用中,比如在文本分析中,余弦相似度常用于度量文档或词向量的相似度。通过将文档或词汇表示为高维空间中的向量,可以使用余弦相似度来比较它们之间的相似性,这在信息检索、推荐系统和文本分类等任务中非常有用。
余弦相似度的一个优点是它对向量的长度不敏感,只关注方向,因此它适用于度量大小差异很大但方向相似的数据点。然而,它也有缺点,比如在稀疏数据或数据分布不均匀的情况下,余弦相似度可能会产生误导性的结果。

1.3 比例点积
比例点积(scaled dot-product attention)是注意力机制(Attention Mechanism)中的一种计算方式,它在Transformer模型中被广泛使用。比例点积注意力通过计算查询(Query)和键(Key)之间的点积,并除以一个尺度因子(通常是为了避免点积结果过大导致梯度消失或梯度爆炸的问题)
比例点积注意力的计算公式如下:
其中:
- ( Q )、( K ) 分别是查询矩阵、键矩阵。
是键向量的维度。
是缩放因子,用于确保点积的梯度不会过大或过小。

2、demo
下面我们有两段文字,将这两段文字中的所有单词映射到坐标中,我们这里使用三位坐标轴来表示,将其坐标依次表示出来
an apple and an orange
an apple phone

接下来根据单词的坐标位置计算余弦相似度来表示其相似性

当我们计算完相似度后会得到一个矩阵,那么这个矩阵就表示每个单词之间的相似度,也会得到每个单词在其他所有单词上的相似度结果。我们可以将任何一个单词,用相似度的形式将其表示出来。

3、归一化
每个单词表示完成后,我们会发现,当数据很多的时候,这个数字之间不断的迭代会变得很大,所以我们需要对他们进行转换,对数字进行缩放,同时要保证每个单词前面的数字按照一定的比例,大的数字保持排在前面,小的权重排在后面。
这个在机器学习中也会经常遇到,就是归一化

我们将每个数字都除以全部数字的总和,这样就会同比例缩放,将每个单词用来表示的权重之和等于1
当然这样也会有问题,就是余弦相似度是可以为负的,如果所有的数值加起来等于0就坏了

4、soft Max
我们想要一种方法,可以将所有的权重变为整数,保证分母不会为0;这样看起俩球绝对值是一个方法;
但是我们还想要大于0的数值的权重要比等于0和小于0的权重更大,更突出,那么就要用到指数的变换了
将所有的数字进行变换后,在进行归一化

5、实现过程
不过为了简化过程我们还是把0相关的内容去掉,因为我们需要在二维坐标轴上展示。
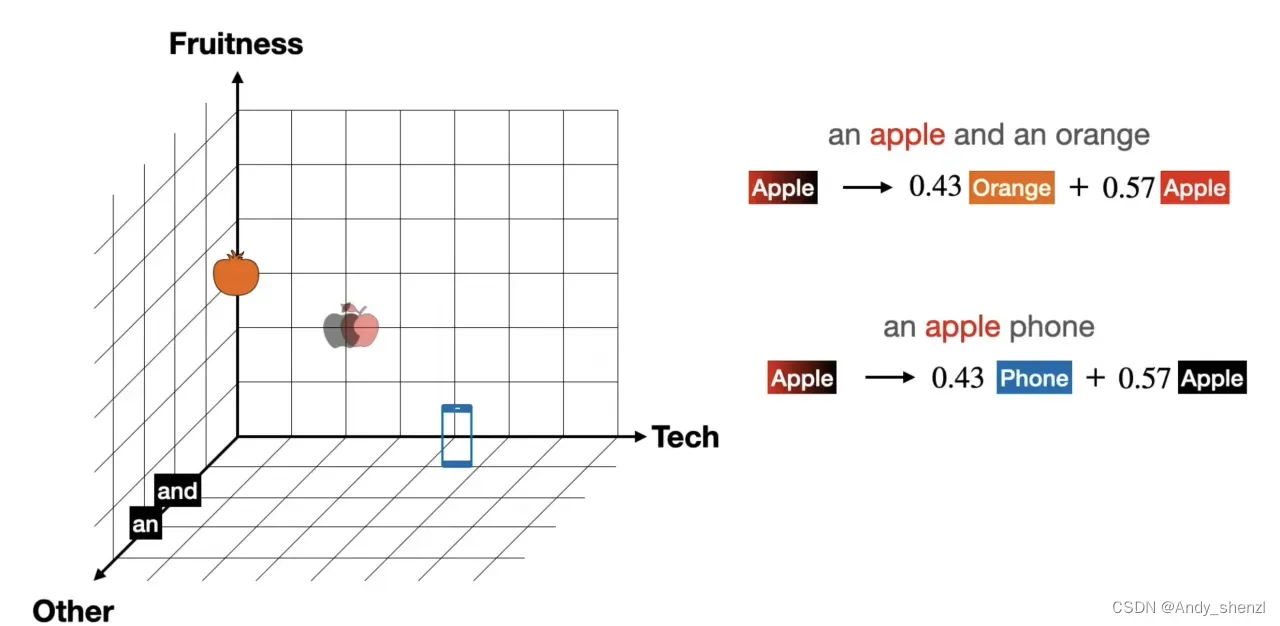
an apple and an orange
其表示为
在遇到句子:
an apple phone
其表示为
那么我们就根据上面表示进行移动,移动后就是说明,当我们在第一句话的训练时,apple的坐标不是2,2;而是移动后的(1.14,2.43)
而在第二句话中也是一样

6、Q、K、V
讲完上述内容,其实就是为了更好的说明Q、K、V这三个矩阵,
论文原图如下

6.1 Q、K
我首先来介绍Q、K矩阵,在前一篇文章说过,注意力机制是通过计算单词之间的相似度来移动单词从而更新embedding,但是在此之前需要做的事是需要初始化矩阵,我们初始化的过程是选择一个,然后进行线性变换得到其他的。

现在我们需要进行线性变化得到更好的初始化的词嵌入矩阵,那么如何实现呢?这就是Q和K矩阵要做的,他们是如何修改词嵌入矩阵的呢?

现在orange和phone这两个单词不是直接相乘求点积,而是orange先乘以Keys矩阵,queries乘以phone的转置,在进行相乘,其中K*Q的部分就是创建一个线性变换修改原始的词嵌入矩阵,实现词嵌入的优化
所以整个过程就是修改词嵌入中的相似性,并在不同的度量上采用相似性来确保这是一个更好的词嵌入,键和查询矩阵作为将我们的词嵌入转换为更适合词注意力机制的词嵌入的一种方式。
6.2 V矩阵
前面我们讲了查询矩阵和键矩阵是通过计算将词嵌入变成更好的相似性词嵌入,但是这个过程其实没有发生任何移动,他只是实现了所有词向量的相似度的计算,也就是说在Q和K的过程中,Q和K两个矩阵他们没有实际修改我们的embedding,但是这个过程实现了对词嵌入矩阵的理解,他输出的结果就是所有的单词之间相似性,也可以理解为我们前面说的相互吸引力,这个时候就需要利用我们计算得到的吸引力对V矩阵进行操作了。

V矩阵其实就是我们所有单词的初始化的embedding,与K和Q一样,区别就是,最终V矩阵才是最后用于模型表示的,而Q和K只是中间参与,用于调整V的。
那么为什么求的相似度后会得到更好的embedding呢,我们知道Q和K矩阵线性变换是根据单词的每一个维度进行优化的

比如我们前面例子中的水平轴是科技属性,垂直轴是水果属性,所以在整个过程中是不断提取和优化单词特征的过程,所以求得到的结果也会根据单词的特征对V矩阵进行调整,最终调整后的矩阵就是我们想要得到的结果
6.3 结合
当我们得到了最后的相似性矩阵后,这个时候我们说了,他只是求出了相似性,也对每个单词进行了表示,但是没有发生移动,整个注意机制要发生作用主要是对V的改变,这个时候我们和V矩阵相乘才会发生移动,而且移动的结果会传递到后循环中,是不断优化的。

我们看相乘的过程其实是每一个单词对其他所有单词在所有维度也就是特征上的关注度的计算。V矩阵的每一列代表单词的一个特征,最后求出的矩阵的长度其实是和V矩阵一样的,也就是最后的特征数量一致,没有改变。

我们来梳理一下这个过程,Q * V 得到相似性矩阵,先进除以维度的开放进行数据缩放,mask这里先不讲,后面进行soft Max进行归一化,得到整体的线性变换矩阵在乘以V矩阵。
7、多头注意力
多头注意力机制就是使用多个Q、K、V矩阵

最后将其concat起来,得到最后的结果。
版权声明:本文为博主作者:Andy_shenzl原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Andy_shenzl/article/details/136650313