hello,我是毛豆。
上次毛豆以涨停双响炮为例,介绍了如何通过python对股票进行分钟级别的监控:
量化研究分享:如何用python抓涨停双响炮
后面收到小伙伴的私信,说最近人工智能很火,问毛豆有没有可能用人工智能来炒股呢?
其实,用AI模型炒股这件事情早已广泛存在,大量的量化机构都在研究和使用,这里面主要涉及到机器学习、深度学习技术,想要深入研究并不是一件容易的事情。为了满足大家的好奇心,今天毛豆就以时序分析中常用的LSTM模型为例,来和大家分享一下机器学习技术是如何应用于股价预测的。
一、LSTM模型
首先说一下为什么要使用LSTM模型来预测股价。一方面,股价预测是高度非线性的,这就要求模型能够处理非线性问题;另一方面,股价具有时间序列的特性,适合使用循环神经网络。因此相比于众多ML和DL模型,LSTM在这个问题上有着天然的优势。
然后介绍一下今天的主角,LSTM模型。LSTM的全称是Long Short Term Memory,是循环神经网络(RNN)的一种,顾名思义,它具有记忆长短期信息的能力。长期困扰传统神经网络结构的一个基本问题是解释“信息”和“上下文”相互依赖的输入序列,在这个问题上RNN能起到一定的作用,但是当输入序列过长时RNN的权重矩阵要循环相乘,所以会产生梯度消失和梯度爆炸的问题,因此RNN不能解决长期依赖问题,这时候LSTM就可以派上用场了。
LSTM模型的1个神经元包含了1个细胞状态(cell)和3个门(gate)机制,三个门分别是输入门、遗忘门和输出门。其中输入门决定将哪些新信息添加到细胞状态,遗忘门负责单元状态的权重和激活函数,输出门决定输出什么,它决定了后面隐藏状态的值。LSTM的核心是细胞状态,它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNN。下面是 LSTM 神经元的典型内部工作图:
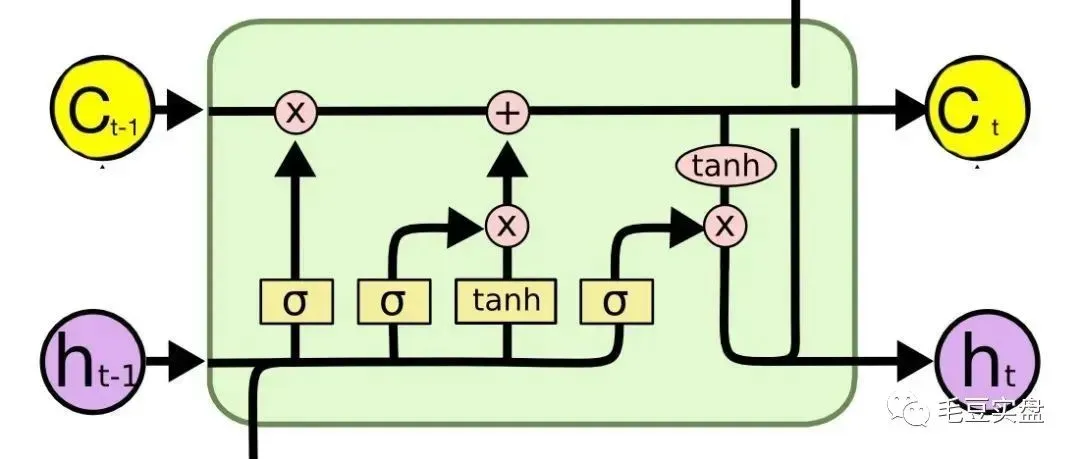
其中C(t-1)为上一时刻的细胞状态值,C(t)为这一时刻的细胞状态值;h(t-1)为上一时刻的输出,h(t)为这一时刻的输出。参数更新方法主要是反向传播和链式求导,具体公式在这里不做阐述。由于存储单元中编码的值不会重复更新,因此在使用反向传播训练时梯度不会消失,从而使LSTM能够克服梯度消失问题。
总的来说,信息按照一套规则进入LSTM网络,只有经过LSTM验证的信息才会被保留,否则它将被遗忘门删除。这种单元状态是保持网络和输入的长期记忆和上下文的原因。
LSTM模型就介绍到这里,接下来介绍如何通过LSTM模型实现股价预测。
二、通过LSTM模型实现股价预测
0. 环境准备
导入数据分析常用的包:
#基础数据分析包
import os
import pandas as pd
import numpy as np
import pickle
import jqdatasdk
from jqdatasdk import *
import mpl_finance as mpf
from matplotlib.dates import date2num
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker导入深度学习keras框架。多年前毛豆做深度学习模型的时候,keras还是独立的包,其后端(底层框架)是可以选择tensorflow或Theano的,但现在keras已经集成到tensorflow中了,因此直接用tf.keras就好了:
#深度学习框架
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
from tensorflow.keras.layers import Input,Dense,LSTM,GRU,BatchNormalization
from tensorflow.keras.layers import PReLU
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error as MAE
tf.keras.backend.clear_session()1.获取数据
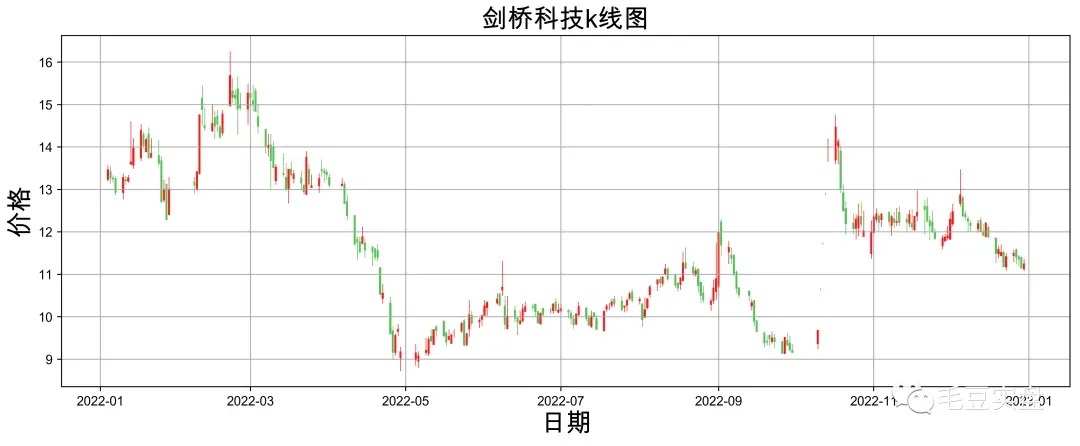
我们以今年的大牛股剑桥科技为例,首先获取其去年一年的数据,通过设置参数skip_paused=True删除停牌日期:
security='603083.XSHG'
df=get_price(security,start_date='2022-01-01',end_date='2022-12-31', frequency='daily', fields=['open', 'close', 'low', 'high', 'volume', 'money', 'pre_close'],
skip_paused=True, fq='pre', panel=True)先画一个蜡烛图看看:
#转化时间格式
df['date']=date2num(df.index.to_pydatetime())
df1=df[['date','open','close','high','low','volume']]
#绘制蜡烛图
plt.figure(figsize=(14,5))
plt.subplots_adjust(hspace=0.45)#调整子图间距
ax1=plt.subplot(1,1,1)
ax1.grid(True)
ax1.xaxis_date()
mpf.candlestick_ochl(ax1,df1_mat,colordown='#53c156', colorup='#ff1717',width=0.3,alpha=1)plt.xlabel("日期",size=20)
plt.ylabel("价格",size=20)
plt.title("剑桥科技k线图",size=20)
plt.show()效果如下:
2.数据预处理
首先我们将训练数据处理成深度学习训练要求的向量格式,特征值x为时间步N天内的股价数据,目标值y为第N+1天的股价数据。
#按时间步生成输入输出数据集
def Processing_data(array,timeStep):
data=list()
for i in range(len(array)-timeStep):
a=list(array[i:i+timeStep])
data.append(a)
return np.array(data)这里我们仅使用股价数据就可以了,时间步长取30天:
timeStep=30
x=Processing_data(df['close'],timeStep)
y=df['close'][timeStep:].values对数据进行标准化:
#标准化
x_scaler = StandardScaler()
y_scaler = StandardScaler()
x=x_scaler.fit_transform(x)
y=y_scaler.fit_transform(y.reshape(-1,1))然后将数据划分为训练集和测试集:
#划分数据集
ind=int(len(x)*0.75)
x_train,y_train,x_test,y_test=x[:ind],y[:ind],x[ind:],y[ind:]准备好数据后,接下来就可以建模了。
3.构建LSTM模型
模型主要涉及到的参数有激活函数、学习率、损失函数等。dropout的作用是防止过拟合,可以先不加。
#构建LSTM模型
def buildLSTM(timeStep,inputColNum,outStep,learnRate,loss_function):
'''
搭建LSTM网络,激活函数为tanh
timeStep:输入时间步
inputColNum:输入列数
outStep:输出时间步
learnRate:学习率
loss_function::损失函数
'''
#输入层
inputLayer = Input(shape=(timeStep,inputColNum))
#中间层
middle = LSTM(256,activation='relu')(inputLayer)
middle = Dense(256,activation='relu')(middle)
#dropout
#dropout=tf.nn.dropout(middle,rate=0.2)
#输出层 全连接
outputLayer = Dense(outStep)(middle)
#建模
model = Model(inputs=inputLayer,outputs=outputLayer)
optimizer = Adam(lr=lr)
model.compile(optimizer=optimizer,loss=loss_function)
model.summary()
return model我们初始化配置网络参数如下,这里的时间步长为30天,输出步长1天,即每次使用过去30天的数据来预测未来1天的数据,如果想预测未来3天的数据将outStep设置为3即可。
#配置神经网络参数
timeStep=30
outStep=1
num_units = 64
lr = 0.01
activation_function = 'tanh'
adam = Adam(lr=lr)
loss_function = 'mse'
batch_size = 65
epochs = 50
inputColNum=1
#LSTM模型
lstm = buildLSTM(timeStep,inputColNum,outStep,lr,loss_function)
(注意,上面模型的构建方式为回归模型,我们也可以使用KerasClassifier将模型封装为分类模型,模型输出为上涨/下跌,这样可以更方便地评估模型的准确率。)
#构建分类模型
lstm = KerasClassifier(build_fn=buildLSTM,verbose=0)由于初始设置的参数不一定是最优的,我们可以使用网格搜索的方法对超参数进行调优。以激活函数的调优为例,可以备选softmax、relu、sigmoid等多个激活函数,看看哪一个激活函数下模型准确率最高:
#网格搜索
lstm = KerasClassifier(build_fn=buildLSTM,epochs=50,batch_size=60,verbose=0)
activation = ['softmax', 'softplus', 'softsign', 'relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear']
param_grid = dict(activation=activation)
grid = GridSearchCV(estimator=lstm, param_grid=param_grid, n_jobs=1)
grid_result = grid.fit(x_train, y_train)
#调优结果
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
for params, mean_score, scores in grid_result.grid_scores_:
print("%f (%f) with: %r" % (scores.mean(), scores.std(), params))打印结果如下(使用linear激活函数准确率最佳,实际效果差不多):

其余的各个参数以此类推,最终都可以得到最优参数。
在得到最优参数后,我们重新配置参数来构建模型:
lstm = buildLSTM(timeStep,inputColNum,outStep,lr,loss_function)
然后再使用训练集数据训练神经网络:
#训练神经网络
lstm.fit(x_train,y_train,epochs=epochs,verbose=0,batch_size=batch_size)4.预测股价
训练完成后,使用训练好的模型(回归模型)对测试集数据进行预测:
yPredict=lstm.predict(x_test)因为数据归一化过,我们使用inverse_transform方法将数据还原,这样就得到了预测后的数据:
yPredict=y_scaler.inverse_transform(yPredict)
yTest=y_scaler.inverse_transform(y_test)将结果整理到一个数据框,包括真实股价、预测股价、真实涨幅、预测涨幅;我们构造一个新的列来记录模型对股票涨跌的判断是否正确,正确为1,错误为0:
c1,c2=[],[]
for i in range(len(yTest)):
c1.append(yTest[i][0])
c2.append(yPredict[i][0])
res=pd.DataFrame({'true':c1,'pred':c2},index=df.index[ind+timeStep:])
res1=res.shift(1)
res['true_rate']=(res['true']-res1['true'])/res1['true']
res['pred_rate']=(res['pred']-res1['true'])/res1['true']
res['tag']=0
res['tag'][res['true_rate']/res['pred_rate']>=0]=1
print(res.head())查看结果:
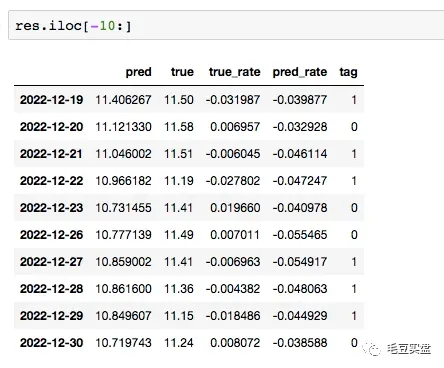
例如12-19日剑桥科技股价真实值为11.50,预测值为11.40,虽然真实值和预测值之间有误差,但误差并不大,至少模型对涨跌的判断是正确的,因此tag为1。
12月20日剑桥科技股价真实值为11.58,预测值为11.12,这一天的预测结果误差就比较大了,真实情况是上涨的,而预测情况是下跌的,涨跌预测错误,因此tag为0。
那么通过整理后的数据,我们就可以统计模型预测值与真实值之间的误差以及预测的准确率,并由此评价模型是否可靠。
5.模型评估
股价的误差衡量我们采用平均绝对误差(MAE),其计算方式为目标值和预测值之差的绝对值之和。准确率(accuracy)即预测正确的样本数占总样本数的比例。如果更关注模型预测错误带来的风险,我们也可以使用假阳性率(false positive rate,FPR)来评估模型。
mae = MAE(res['true'],res['pred'])
print('MAE',mae)
accuracy=res['tag'].value_counts()[1]/len(res['tag'])
print('accuracy',accuracy)打印结果如下:
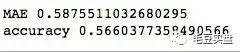
模型的预测准确率方面仅达到56.6%,比投掷硬币稍强一点点。注意这里的准确率是模型在测试集上的准确率,上面使用网格搜索得到的准确率是模型在训练集上的准确率,需要区分。
将预测值和真实值可视化:
#可视化
plt.figure(figsize=(8,5))
plt.plot(res.index,res['pred'],label='pred')
plt.plot(res.index,res['true'],label='true')
plt.title('MAE: %2f'%mae)
plt.legend()
plt.savefig('fig2.png',dpi=400,bbox_inches='tight')结果如图,其中黄线为真实价格,蓝线为预测价格:

三、总结
总的来说,LSTM对股价具有一定的记忆能力,其对距离当前时间越近的数据“记忆性”越强,对距离当前时间越远的数据“记忆性”越弱,因此模型在对股价预测时会更多地依赖近端的数据。具体表现为,当近期股价连续上涨时,模型倾向于预测其继续上涨;当近期股价连续下跌时,模型倾向于预测其继续下跌。这样的特性会导致一个严重的后果,即只有当股价走势发生变化之后(如连续上涨后的突然下跌、连续下跌后的突然上涨),模型才会进行纠错,因此模型会存在严重的“延时性”。
那么为什么模型没能很好地预测股价呢?或者如何去解决这样的“延时性”呢?
毛豆认为,不论是LSTM亦或是其他的机器学习模型,其本质上是通过数理逻辑对股价的运行规律进行归纳总结,但这样做的前提必须是股价要有规律,尤其是长期的规律。而A股是典型的政策市,任何突发的利好或利空消息都会改变股票原本的走势或规律,这些消息面的因素对模型来说都是随机事件、是无法预测的、是噪声点,这些噪声点严重干扰了模型对股价原本走势的拟合效果。而大多数A股在其股价走势中受到消息面或外在的影响太多,致使其走势原本的规律性变得难以拟合。
今天的干货内容到这里就结束了,最后毛豆说一下,之前毛豆分享的行业网络模型是利用行业间的相关性来构建网络,而本文使用的神经网络是深度学习模型,虽然两个都是“网络”,但其原理是截然不同的,大家切勿混淆。行业网络模型的相关内容可以看我前面的帖子:量化研究分享:如何构建行业网络模型
喜欢毛豆的老铁们记得点赞+关注,你们的关注是对毛豆最大的支持。
文章出处登录后可见!