
SadTalker模型是一个使用图片与音频文件自动合成人物说话动画的开源模型,我们自己给模型一张图片以及一段音频文件,模型会根据音频文件把传递的图片进行人脸的相应动作,比如张嘴,眨眼,移动头部等动作。
SadTalker,它从音频中生成 3DMM 的 3D 运动系数(头部姿势、表情),并隐式调制一种新颖的 3D 感知面部渲染,用于生成说话的头部运动视频。
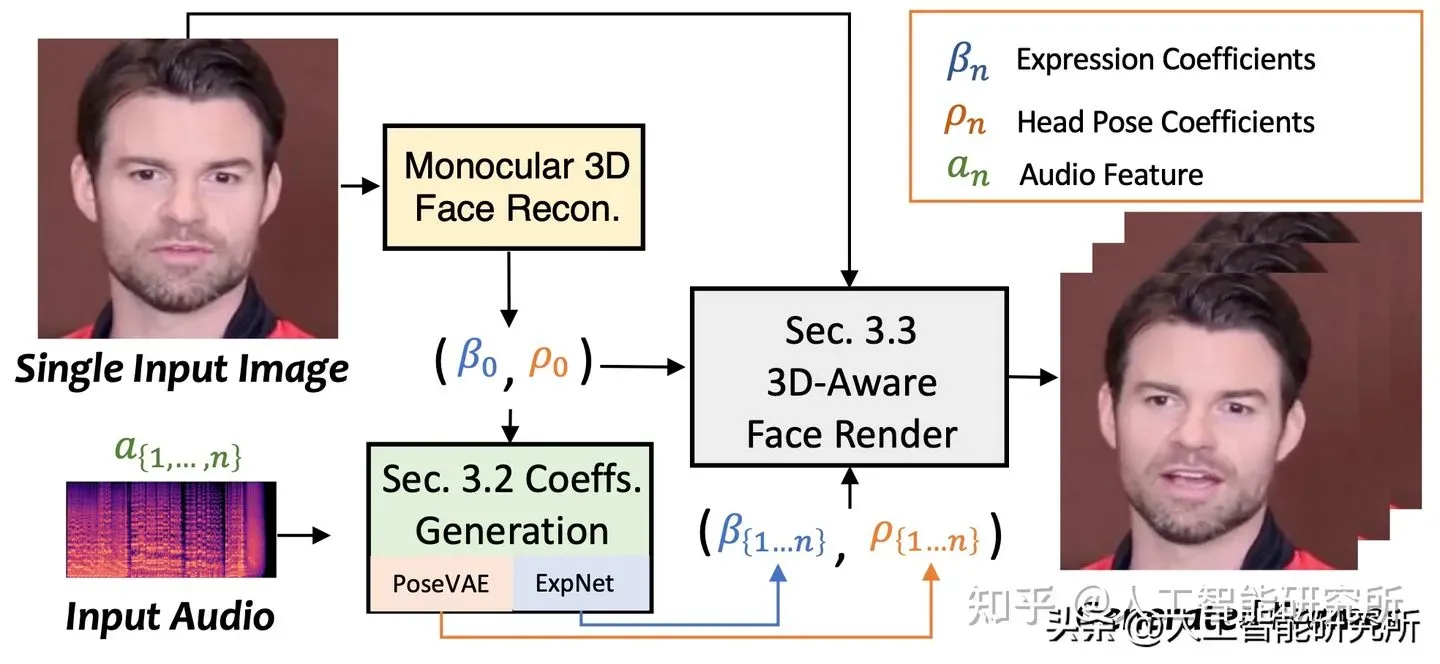
为了学习真实的运动,SadTalker分别对音频和不同类型的运动系数之间的联系进行显式建模。 准确地说,SadTalker提出 ExpNet模型,通过提取运动系数和3D渲染的面部运动来从音频中学习准确的面部表情。 至于头部姿势,SadTalker通过PoseVAE 以合成不同风格的头部运动。
模型不仅支持英文,还支持中文,我们可以直接hugging face上面来体验
https://huggingface.co/spaces/vinthony/SadTalker当然官方开源了源代码,我们可以直接在自己电脑上面来运行此模型
https://github.com/OpenTalker/SadTalker当然我们要运行本程序,需要安装python3.8以上版本,并下载预训练模型ÿ
文章出处登录后可见!
已经登录?立即刷新