Pytorch
- 一 、深度学习概览
- 1、工具篇
- 2、流程介绍
- 3、基础知识(常用操作)
- 1、数据结构类型
- 4、常见名词概念
- 二、深度学习Pytorch
- 1、神经网络
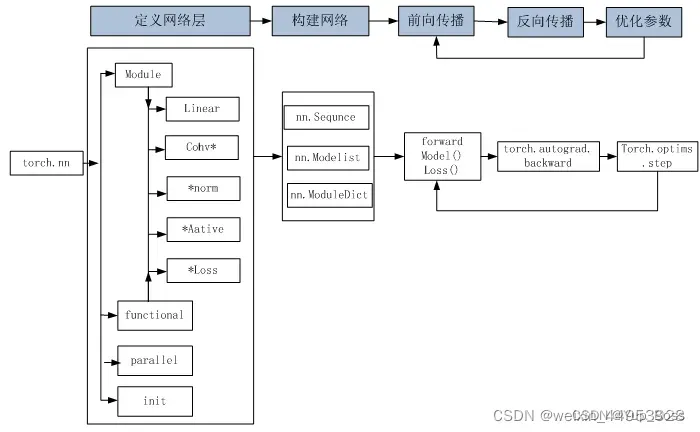
- 1.1 如何构建神经网络
- 1.2 核心组件
- 2、数据处理工具
- 2.1 torchvision(可视化处理工具)
- 2.1.1、torchvision.transforms
- 2.1.2、torchvision.datasets
- 2.1.3、torchvision.models
- 2.1.4、torchvision.utils
- 2.2 torch.utils.data
- 3 、神经网络工具箱nn
- 3.1 nn.Module模块
- 3.2 nn.functional模块
- 4 、优化器
- 4.1 动态修改学习率参数
- 5 、可视化工具(tensorboardX)
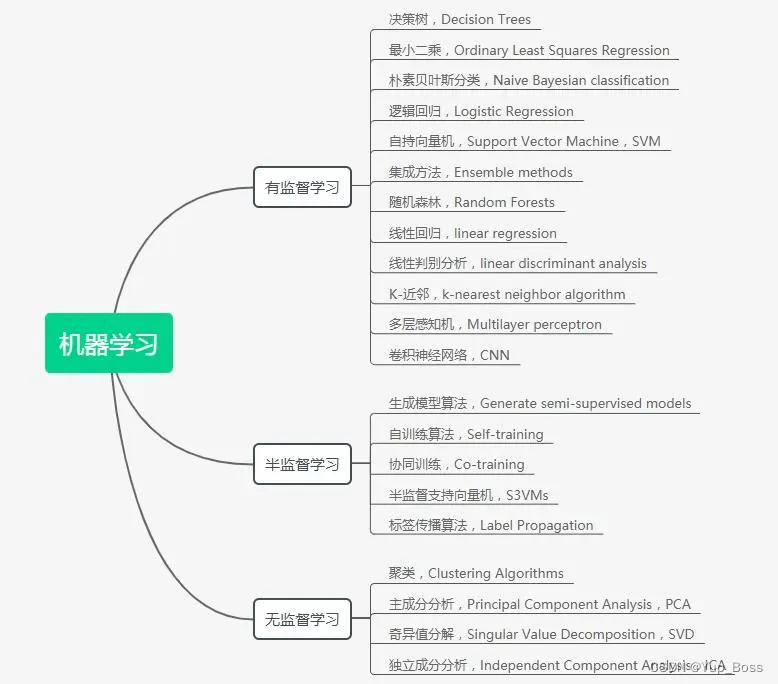
- 6 、机器学习基础
- 6.1 机器学习一般流程
- 6.2 相关知识介绍
- 7 、视觉处理基础
- 7.1 卷积神经网络(CNN)
- 7.2 卷积层
- 7.3 池化层
- 三、具体常用算法
- 1、YOLOv5
- 2、BEV感知算法
- 四、相关工具及工具包配置环境
- 待补充
一 、深度学习概览
1、工具篇
推荐10个好用到爆的Jupyter Notebook插件,让你效率飞起(先安装python,再安装pip)
2、流程介绍
请点击—->深度学习计算机视觉学习流程
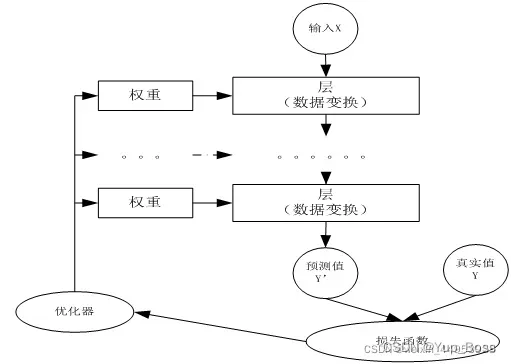
请点击–> 深度学习模型训练全流程!
请点击–> 深度学习一般工作流程:
step 1、定义问题,收集数据集。
step 2、定义模型预测性能指标
step 3、确定模型评估方式
step 4、数据预处理
step 5、搭建模型
1、确定激活函数、损失函数
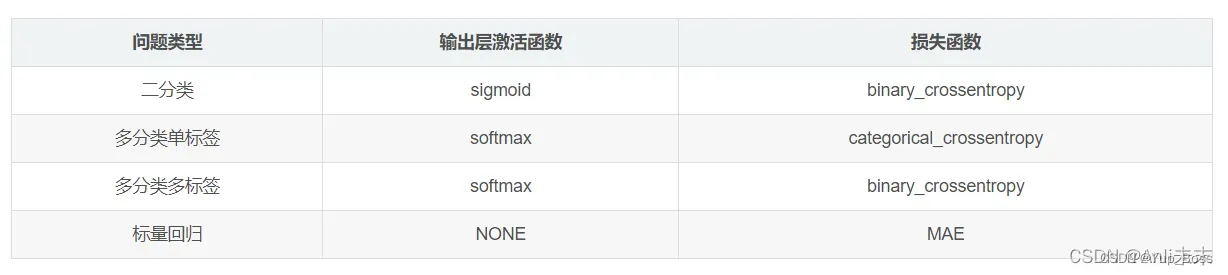
2、从简单结构开始逐步扩大模型规模
3、考虑正则化和dropout
step 6、交叉验证
step 7、测试集验证
注意:测试集性能和验证集性能相差较大,考虑采用更复杂的验证方法,如乱序重复K折交叉验证
3、基础知识(常用操作)
1、数据结构类型
请点击—> Tensor 常用操作
Pytorch基本变量类型FloatTensor与Variable
| torch成员函数 | 函数作用解释 |
|---|---|
| torch.where(condition,a,b) | torch.where()函数的作用是按照一定的规则合并两个tensor类型。输入参数condition:条件限制,如果满足条件,则选择a,否则选择b作为输出。注意:a和b是tensor. |
| torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) | 返回一个形状为为size,类型为torch.dtype,里面的每一个值都是0的tensor. |
| torch.full(size, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) | 返回创建size大小的维度,里面元素全部填充为fill_value. |
| torch.ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) | 返回创建size大小的维度,里面元素全部填充为1. |
4、常见名词概念
SOTA
Sota实际上就是State of the arts 的缩写,指的是在某一个领域做的Performance最好的model,一般就是指在一些benchmark的数据集上跑分非常高的那些模型。
SOTA model:并不是特指某个具体的模型,而是指在该项研究任务中,目前最好/最先进的模型。
SOTA result:指的是在该项研究任务中,目前最好的模型的结果/性能/表现。
Benchmark、Baseline
Benchmark和baseline都是指最基础的比较对象。你论文的motivation是想超越现有的baseline/benchmark,你的实验数据都需要以baseline/benckmark为基准来判断是否有所提高。唯一的区别就是baseline讲究一套方法,而benchmark更偏向于一个目前最高的指标,比如precision,recall等等可量化的指标。举个例子,NLP任务中BERT是目前的SOTA,你有idea可以超过BERT。那在论文中的实验部分你的方法需要比较的baseline就是BERT,而需要比较的benchmark就是BERT具体的各项指标。
迁移学习
迁移学习通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。
泛化(Generalization)
模型的泛化能力通俗易懂的说就是模型在测试集(其中的数据模型以前没有见过)中的表现,也就是模型举一反三的能力
二、深度学习Pytorch
常用两个功能函数:dir() ; help()。
【目录】【中文】【deplearning.ai】【吴恩达课后作业目录】
Python深度学习基于PyTorch:第1章 NumPy基础
Python深度学习基于PyTorch:第2章 Pytorch基础
Python深度学习基于PyTorch:第3章 Pytorch神经网络工具箱
Python深度学习基于PyTorch:第4章 Pytorch数据处理工具箱
1、神经网络
1.1 如何构建神经网络
step 1:构建网络层:一般采用torch.nn.Sequential()来构建;
step 2:前向传播:定义forward函数。forward函数的任务需要把输入层、网络层、输出层链接起来,实现信息的前向传导。在forward函数中,有些层来自nn.Module,也可以使用nn.functional定义。来自nn.Module的需要实例化,而使用nn.functional定义的可以直接使用。
step 3:反向传播:在反向传播过程中,优化器是一个重要角色。pytorch常用的优化方法都封装在torch.optim里面。最常用的优化算法就是梯度下降法及其各种变种。所有的优化方法都是继承了基类optim.Optimizer。
| 优化方法 | 优化器 |
|---|---|
| 随机梯度下降法 | torch.optim.SGD() |
| 含有动量的 随机梯度下降法 | torch.optim.SGD() |
| Per-parameter adaptive learning rate methods(逐参数适应学习率方法) | torch.optim.RMSprop() |
| Per-parameter adaptive learning rate methods(逐参数适应学习率方法) | torch.optim.Adam() |
| torch.optim.Adadelta() | |
| torch.optim.Adagrad() | |
| 以上优化器 |
nn.CrossEntropyLoss:
step 4:训练模型:缺省情况下,梯度是累加的,需要手工把梯度初始化或清零,调用optimizer.zero_grad()即可。如果希望用GPU训练,需要把模型、训练数据、测试数据发送到GPU上,即调用.to(device)。如果需要多GPU进行处理,可使模型或相关数据引用nn.DataParallel。
step 5:
1.2 核心组件
(1)层:神经网络的基本结构,将输入张量转换为输出张量。
卷积层:
全连接层:
Dropout层:
池化层:
隐含层:
(2)模型:层构成的网络。
(3)损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。
(4)优化器:如何使损失函数最小,这就涉及优化器。常用的是4种。
2、数据处理工具
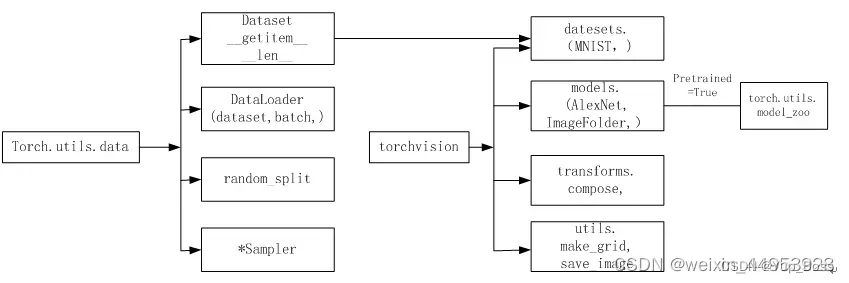 一边用torch.utils.data.Dataset处理同一个目录下的数据。如果数据在不同目录下,不同目录代表不同类别(这种情况比较普遍),使用data.Dataset来处理就不很方便。不过,可以使用Pytorch另一种可视化数据处理工具(即torchvision)就非常方便,不但可以自动获取标签,还提供很多数据预处理、数据增强等转换函数。
一边用torch.utils.data.Dataset处理同一个目录下的数据。如果数据在不同目录下,不同目录代表不同类别(这种情况比较普遍),使用data.Dataset来处理就不很方便。不过,可以使用Pytorch另一种可视化数据处理工具(即torchvision)就非常方便,不但可以自动获取标签,还提供很多数据预处理、数据增强等转换函数。
2.1 torchvision(可视化处理工具)
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision有4个功能模块:model、datasets、transforms和utils。
2.1.1、torchvision.transforms
torchvision.transforms是pytorch中的图像预处理包。例如裁剪、旋转等。
一般用Compose把多个步骤整合到一起,transforms.Compose。
数据归一化处理transforms.Normalize。
2.1.2、torchvision.datasets
另说明: torch.utils.data包括Dataset(只负责数据的抽取,不能进行批处理)和DataLoader(不光可以批处理还能shuffle和并行加速)。
提供常用的数据集加载,设计上都是继承自torch.utils.data.Dataset。
torchvision学习之torchvision.datasets。 一些加载数据的函数及常用的数据集接口。
torchvision.datasets中包含了以下数据集:
(1)MNIST
(2)COCO(用于图像标注和目标检测)(Captioning and Detection)
(3)LSUN Classification
(4)ImageFolder
(5)Imagenet-12
(6)CIFAR10 and CIFAR100
(7)STL10
2.1.3、torchvision.models
PyTorch源码解读之torchvision.models
torchvision.models这个包中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用的网络结构,并且提供了预训练模型,可以通过简单调用来读取网络结构和预训练模型。
2.1.4、torchvision.utils
2.2 torch.utils.data
它包括以下4个类:
(1)Dataset:是一个抽象类,其它数据集需要继承这个类,并且覆写其中的两个方法( _ getitem 、_ len __)。
(2)DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能。
(3)random_split:把数据集随机拆分为给定长度的非重叠新数据集。
*(4)sampler:多种采样函数。
3 、神经网络工具箱nn
3.1 nn.Module模块
nn.Module是nn核心数据结构,它可以是神经网络的某个层(Layer),也可以是包含多层的神经网络。在实际应用中,最常见的做法是继承nn.Module,生成自己的网络/层。
3.2 nn.functional模块
两者区别: 具有学习参数的(例如,conv2d, linear, batch_norm)采用nn.Xxx方式。没有学习参数的(例如,maxpool、loss func、activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。
4 、优化器
代码示例:
import torch.optim as optim
lr = 0.01
momentum = 0.5
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
4.1 动态修改学习率参数
修改参数的方式可通过修改参数optimizer.params_groups或新建optimizer。对于使用动量的优化器(momentum参数的sgd)可能会造成收敛中的震荡,所以建议采用修改参数optimizer.params_groups。
torch.unsqueeze(input, dim, out=None) # 解压缩(升维)
torch.squeeze(input, dim = None, out = None) # 压缩(降维)
#####
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
# 函数的作用是,返回一个一维的tensor(张量),这个张量包含了从start到end,分成steps个线段得到的向量。
5 、可视化工具(tensorboardX)
tensorboardX功能很强大,支持scalar、image、figure、histogram、audio、text、graph、onnx_graph、embedding、pr_curve and videosummaries等可视化方式。
6 、机器学习基础
6.1 机器学习一般流程
明确目标→收集数据(收集的数据尽量实现自动化、程序化)→输入数据→数据探索与预处理(一般包括数据清理、数据转换、规范数据、特征选择等)→训练及测试算法或建模(不同方法来训练进而选取最优)→评估及优化模型(留出法、K折交叉验证、重复的K折交叉验证,若出现过拟合,尤其是回归类的问题,可用正则化方法来降低模型的泛化误差)
如何解决过拟合问题呢? 正则化是指在机器学习中,很多被显式地用来减少测试误差的策略。正则化旨在减少泛化误差而不是训练误差。正则化不仅可以有效降低高方差,还有利于降低偏差。
1、权重正则化
2、Dropout正则化
3、批量正则化
4、权重初始化
6.2 相关知识介绍
代价函数(cost function): 衡量模型预测出来的值 h(θ) 与真实值 y 之间差异的函数叫做代价函数J(θ)。
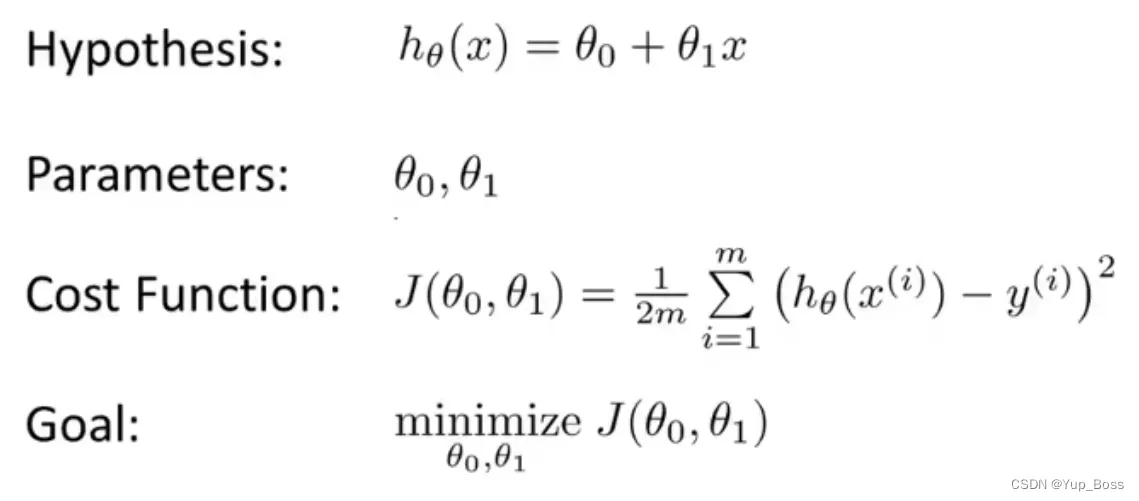
7 、视觉处理基础
7.1 卷积神经网络(CNN)
卷积神经网络是一种前馈神经网络。卷积神经网络由一个或多个卷积层和顶端的全连接层(对应经典的神经网络)组成,同时也包括关联权重和池化层(Pooling Layer)等。
7.2 卷积层
卷积层是卷积神经网络的核心层,而卷积又是卷积层的核心。卷积核(kernel)又称权重过滤器,简称为过滤器(filter)。常见卷积核有Horizontalfilter(水平边缘检测)、Verticalfilter(垂直边缘检测)、Sobelfilter(增强图像中心区域权重)。
1、卷积核
2、步幅(strides)
3、填充(padding)
4、激活函数
卷积神经网络与标准的神经网络类似,为保证其非线性,也需要使用激活函数,即在卷积运算后,把输出值另加偏移量,输入到激活函数,然后作为下一层的输入。
常用的激活函数有:nn.Sigmoid、nn.ReLU、nn.LeakyReLU、nn.Tanh等。
ReLU是将所有的负值都设为零,相反,Leaky ReLU是给所有负值赋予一个非零斜率。
5、卷积函数
卷积函数是构建神经网络的重要支架,通常PyTorch的卷积运算是通过nn.Conv2d来完成的。
6、转置卷积(Transposed Convolution)在一些文献中也称为反卷积(Deconvolution)或部分跨越卷积(Fractionally-Strided)。转置卷积在生成式对抗网络(GAN)中使用很普遍。
7.3 池化层
池化(Pooling)又称下采样,通过卷积层获得图像的特征后,理论上可以直接使用这些特征训练分类器(如Softmax)。常用池化方法有3种:(1)最大池化;(2)均值池化;(3)全局最大池化。
池化的作用体现在降采样:保留显著特征、降低特征维度,增大感受野。
1、局部池化
2、全局池化
全局平均池化(Global Average Pooling,GAP)。GAP的优势在于:各个类别与Feature Map之间的联系更加直观(相比与全连接层的黑箱来说),Feature Map被转化为分类概率也更加容易,因为在GAP中没有参数需要调,所以避免了过拟合问题。GAP汇总了空间信息,因此对输入的空间转换鲁棒性更强。所以目前卷积网络中最后几个全连接层,大都用GAP替换。PyTorch虽然没有对应名称的池化层,但可以使用PyTorch中的自适应池化层(nn.AdaptiveMaxPool2d或nn.AdaptiveAvgPool2d)来实现。
三、具体常用算法
1、YOLOv5
详解:yolov5中推理时置信度,设置的conf和iou_thres具体含义
YOLOV5模型转onnx并推理
| 名称 | 名词解释 |
|---|---|
| Intersect over Union Threshold | 交并比阈值 |
| Roboflow | 在线图像标注软件。目标检测中的数据格式转换工具 |
| pipeline | 直译就是管线,也就是流水线,流程 |
| mAP(Mean Average Precision) | 其中代表P(Precision)精确率。AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。 |
| ONNX(Open Neural Network Exchange) | 开放神经网络交换格式,ONNX 模型一般用于中间部署阶段,起到要给中间翻译的作用。ONNX简明教程。 • Pytorch -> ONNX -> TensorRT • Pytorch -> ONNX -> TVM • TF –ONNX – NCNN Pytorch -> ONNX -> tensorflow |
| protobuf | protocol buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小、更快、更为简单。 protobuf详细介绍和使用 。protocol buffer 文本格式 |
| Objective-C | 通常写作ObjC或OC和较少用的Objective C或Obj-C,是扩充C的面向对象编程语言。它主要使用于Mac OS X和GNUstep这两个使用OpenStep标准的系统,而在NeXTSTEP和OpenStep中它更是基本语言。 |
| DLA | 深度学习加速器 |
| TensorRT | TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。 |
2、BEV感知算法
BEV视觉3D感知算法梳理
四、相关工具及工具包配置环境
jupyter notebook创建/删除虚拟环境—-都在命令行执行
(包含源码+模型数据)使用TensorFlow, ONNX和TensorRT加速深度学习推理
resnet为残差网络-resnet-50介绍(一)
庖丁解牛-Resnet50 深度剖析,细致讲解,深入理解
window10下在anconda中虚拟环境下离线安装pytorch
待补充
请点击–> 深度学习与计算机视觉系列(10)_细说卷积神经网络
请点击–> 11种主要神经网络结构图解
系统学习Pytorch笔记一:Pytorch的数据载体张量与线性回归
系统学习Pytorch笔记二:Pytorch的动态图、自动求导及逻辑回归
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
系统学习Pytorch笔记四:模型创建Module、模型容器Containers及AlexNet网络搭建
系统学习Pytorch笔记五:nn的网络层介绍(卷积层,池化层,激活函数,全连接层等)
系统学习Pytorch笔记六:模型的权值初始化与损失函数介绍
系统学习Pytorch笔记七:优化器和学习率调整策略
系统学习Pytorch笔记八:Tensorboard可视化与Hook机制
系统学习Pytorch笔记九:正则化与标准化大总结
系统学习Pytorch笔记十: 模型的保存加载、模型微调、GPU使用及Pytorch常见报错
Protobuf的简单介绍、使用和分析
文章出处登录后可见!