近期同时在进行的两个深度学习项目都需要用到3DResNet模型,本着不做调包侠的心态,还是要好好把模型的原理看一看的。
1、ResNet结构理解
首先先理解一下二维的ResNet吧。
ResNet又名残差结构,残差连接等。何恺明大佬提出这个概念是为了解决深层网络的梯度消失和梯度爆炸的问题,以及收敛深层网络的“退化”问题,从而可以使得网络层数变得更深。(常见层数有18-34-50-101-152层)相较于之前的层数大多在10~20层的网络来说,无疑是在层数上有了非常大的突破。
残差结构的原理,主要是把输入输出的映射从F(x)转换到了H(x)=F(x)+x上,这样做的目的,个人理解是:在网络层数足够深的情况下,在接近网络输出端的层结构中,其上一层的输出x很可能已经无限逼近于最优解,这个时候对于此层的参数调整,就可以给网络一种选择:即把F(x)置0,或者赋予很小的权重,让此层的结构发挥的作用是将上一层的输出完好地送至下一层,保留最佳输出的结果,也就是所谓的“恒等映射”。(identity mapping)
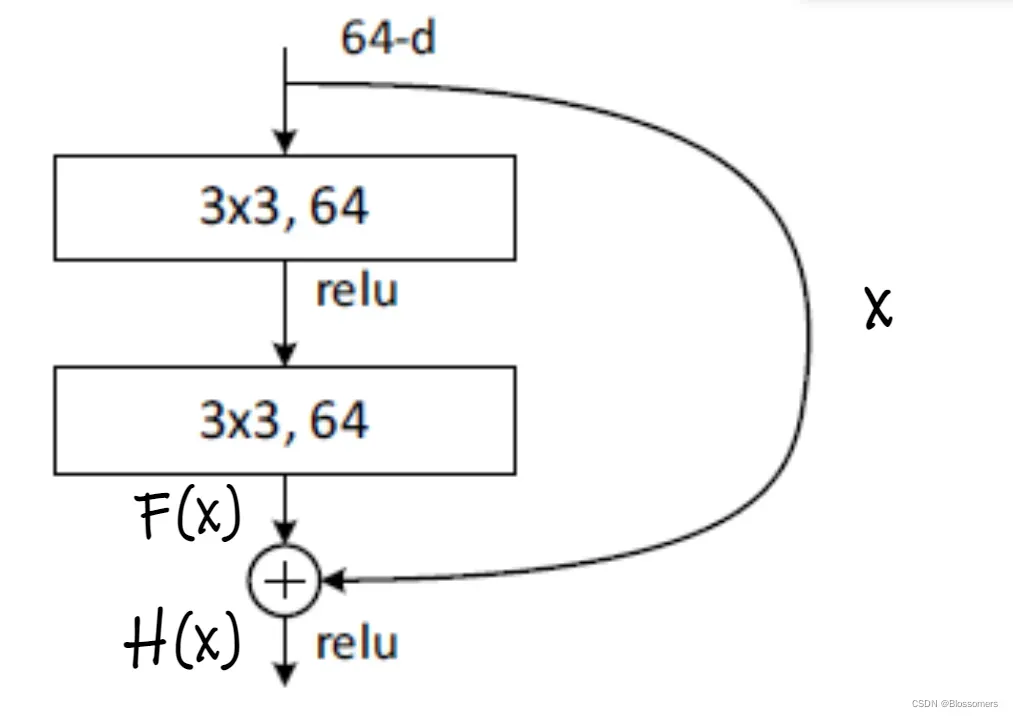
而,传统的卷积层结构来说,要调整至这样一种“不怎么改变输入的”参数结构,显然是不如直接将F(x)置为0来的容易的。本质上这是一种模型复杂度的降低(来自李沐老师的观点),即给网络以一个比较“手动”的引导,去让网络的参数能够逼近于你想要的结构。个人认为,这是残差连接能够加深网络层数的一个比较可以解释得通的理由。
另外,这样一种“学习恒等映射”的方法,它的F(x)也未必一定要完全是0,在输入足够趋近最优解的情况下,可以理解为一种“小幅的,进一步促进输出逼近最优的作用”,像是在训练的尾声阶段把lr调的非常小,那种意思。
2、3DCNN的理解
ResNet3D = ResNet+3DConv 所以有必要先理解一下3DConv的基础知识
3DConv与2DConv的区别,首先就体现在了卷积核的参数上。
2DConv的卷积核尺寸一般为:[in_channels,out_channels,W,H]
3DConv的卷积核尺寸一般为:[in_channels,out_channels,W,H,T] T在这里一般是指,需要连续考虑多少帧的参数。
以下图为例:
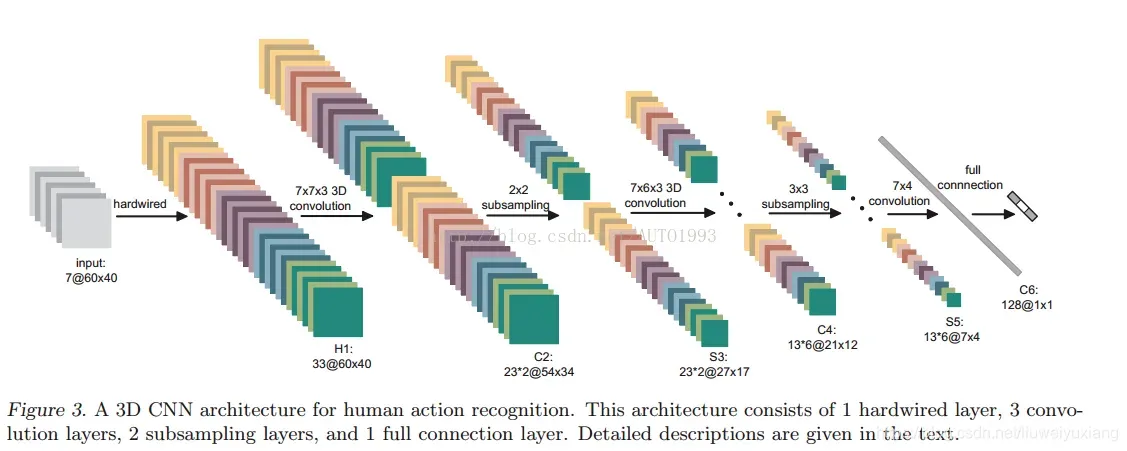
3DConv的shape讨论:对于3DConv来说,他的输入、特征图都从2DConv的单张featuremap变成了一个在时序上堆叠起来的“series feature map”,而每一个“通道”可以理解为图中的一整“块”,如C2中就可以说是有“两个通道”,因为C2是由H1经过了两个不同的卷积核而输出的。而这一个“通道”中,包含的是一个“series”的feature map,比如第一层3DCNN层中,卷积核的WHT参数分别为[7,7,3],表示卷积核的尺寸为7*7,且每一次需要考虑三个帧的信息。H1中一个特征为7帧,那么经过7*7*3的WHT参数的卷积核之后,就会输出一个54*54*5的特征map,所以这样就可以理解,C2中的54*34*23*2的尺寸的来由。
同样地,对于第二层7*6*3的卷积层,三个不同的卷积核分别卷积S3层的feature series map,得到13*6的shape,注意这里,输出的通道数和卷积核的个数是不相等的,这点与2DCNN不同。就是经过在两个通道卷积后,不是像2DCNN那样把他们的结果叠加起来,而是分别映射到两个通道中,这点是导致两者不同的原因。相当于把两个通道“分开来算”
最后一层C6的卷积层,尺度应该是7*4*78*128,也就是2DCNN中inchannel为78,outchannel为128,这样去卷积。最后输出128个1*1的featuremap之后,再用全连接层连起来输出即可~
总体来看,3DConv相对2DConv来说,最大的区别就在于所有的输入,特征,都变成了时序性的,也就是提升了一个维度。经过这样的时序上的卷积,可以有效地提取输入以及特征图中的时序信息,帮助网络更好的理解视频之类的输入。不过,文章中提到的架构,可以看到第一个Hardwired层是去手动地提取了光流,梯度等特征,并不算是一个“端到端”的结构。
而ResNet3D,只是用残差结构将一个个的3DConv模块连接起来,通过实验科学组成一个效果比较好的网络,感觉应该没有太多需要讲的地方,如果后续有新的理解,前来填坑~
Reference:
(6条消息) ResNet详解——通俗易懂版_sunny_yeah_的博客-CSDN博客_resnet
(6条消息) 残差resnet网络原理详解_mao_feng的博客-CSDN博客_resnet
文章出处登录后可见!