原文标题 :Word Embedding Techniques: Word2Vec and TF-IDF Explained
词嵌入技术:Word2Vec 和 TF-IDF 解释
这些词需要对机器学习或深度学习算法有意义。因此,它们必须用数字表示。 One Hot Encoding、TF-IDF、Word2Vec、FastText 等算法使单词能够以数学方式表示为用于解决此类问题的词嵌入技术。

Word Embeddings
词嵌入技术用于以数学方式表示词。 One Hot Encoding、TF-IDF、Word2Vec、FastText是常用的Word Embedding方法。根据处理数据的状态、大小和目的,首选和使用这些技术中的一种(在某些情况下是几种)。
* One Hot Encoding
用于以数字方式表示数据的最基本技术之一是 One Hot Encoding 技术[1]。在这种方法中,创建了一个向量,其大小与唯一词的总数相同。向量的值被分配,使得属于其索引的每个词的值为 1,而其他词的值为 0。例如,可以检查图 1。
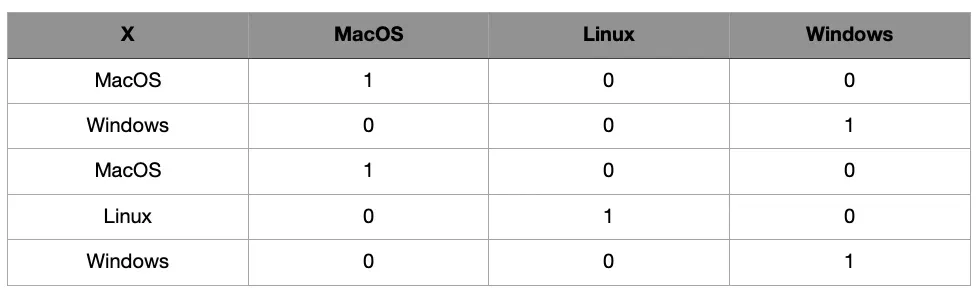
在图 1 中,名为“X”的列由 3 个不同的词组成。当对该列应用一个热编码时,会创建代表每个表达式的 3 个不同的列(换句话说,为每一行创建 3 个单位向量)。每行中与单词对应的列用值1填充,其他为0。因此,这些表达式被数字化了。它一般用于语言数据的多样性不大,不需要表示数据之间的语义和统计关系的情况。
* TF-IDF
TF-IDF 是一种统计度量,用于确定文档中单词的数学意义[2]。矢量化过程类似于 One Hot Encoding。或者,为对应于该词的值分配一个TF-IDF值而不是1。TF-IDF值是通过将TF和IDF值相乘获得的。举个例子,让我们找出由 1 个句子组成的 3 个文档的 TF-IDF 值。
[He is Walter],
[He is William],
[他不是彼得或九月]
在上面的例子中,“He”用在所有 3 个文档中,“is”用在 2 个文档中,“or”只用在一个文档中。根据这些,让我们分别找到 TF 和 IDF 值。
- TF (Term Frequency)
用最简单的术语来说,词频是文档中目标词的数量与文档中的总词数的比率。如果按照上例计算TF值,则为
[0.33, 0.33, 0.33],
[0.33, 0.33, 0.33],
[0.20, 0.20, 0.20, 0.20, 0.20]
- IDF(逆文档频率)
IDF值是文档总数与出现目标词的文档数之比的对数。在此阶段,该术语在文档中出现多少次并不重要。确定它是否通过就足够了。在这个例子中,要取的对数的底值被确定为10。但是,使用不同的值是没有问题的。
“He”: Log(3/3)= 0,
“is”: Log(3/2):0.1761,
“or, Peter, ..”: log(3/1) : 0.4771
这样就得到了TF和IDF值。如果使用这些值创建向量化,则首先为每个文档创建一个由等于所有文档中唯一词数的元素组成的向量(在此示例中,有 8 个词)。在这个阶段,有一个问题需要解决。如术语“He”所示,由于 IDF 值为 0,因此 TF-IDF 值也将为零。但是,在向量化过程中没有包含在文档中的单词(例如,短语“Peter”不包含在第 1 句中)将被赋值为 0。这里为了避免混淆,TF-IDF 值对矢量化进行平滑处理。最常用的方法是在得到的值上加 1。根据目的,稍后可以对这些值应用归一化。如果根据上述创建向量化过程;
[1. , 1.1761 , 1.4771 , 0. , 0. , 0. , 0. , 0.],
[1. , 1.1761 , 0. , 1.4771 , 0. , 0. , 0. , 0.],
[1. , 0. , 0. , 0. , 1.4771 , 1.4771, 1.4771 , 1.4771],
* Word2Vec
Word2vec 是另一种常用的词嵌入技术。扫描整个语料库,并通过确定目标词更频繁地出现哪些词来执行向量创建过程[3]。这样,也揭示了单词之间的语义接近度。例如,让序列 ..x y A z w.. , .. x y B z k.. 和 ..x l C d m… 中的每个字母代表一个词。在这种情况下,word_A 将比 word_C 更接近 word_B。当向量形成中考虑到这种情况时,词之间的语义接近度以数学方式表示。
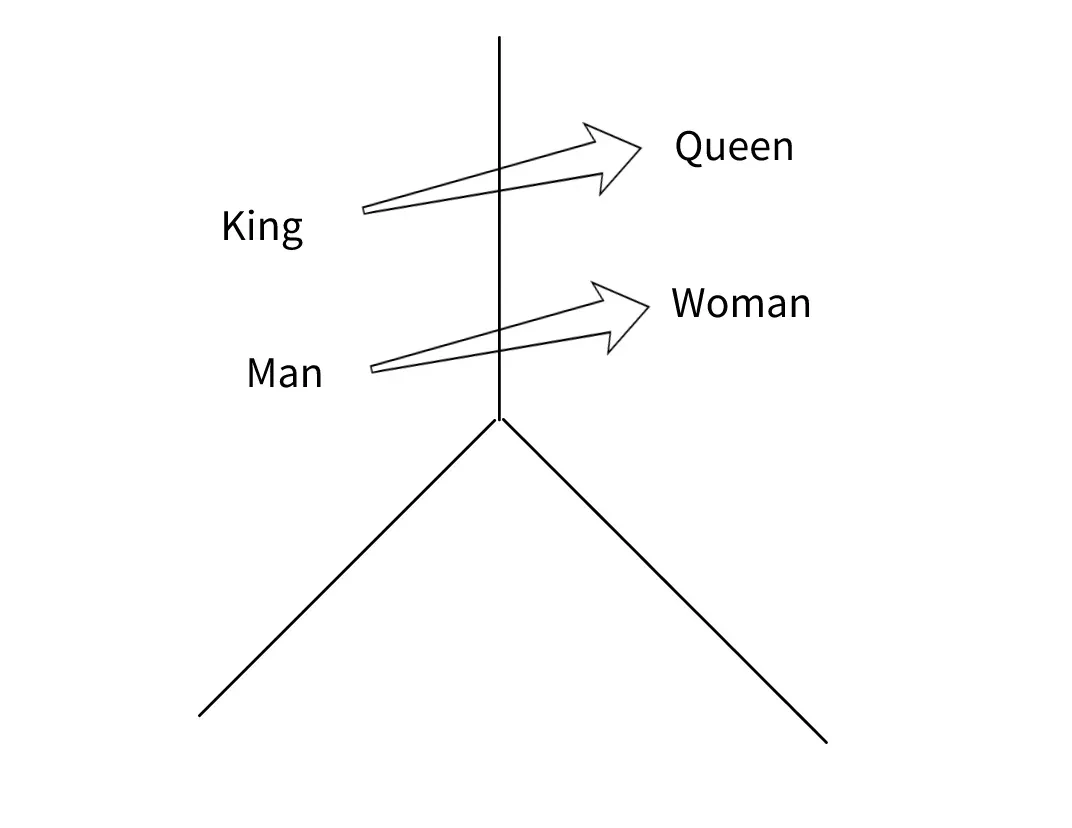
图 2 显示了 Word2Vec 中最常用的图像之一。这些词之间的语义接近度是向量值彼此在数学上的接近度。经常给出的例子之一是等式“国王+女人=女王”。这里发生的情况是,向量相减和相加得到的向量值等于“女王”表达式对应的向量。可以理解为,“国王”和“王后”这两个词非常相似,但向量上的差异只是因为它们的性别。
在 Word2Vec 方法中,与 One Hot Encoding 和 TF-IDF 方法不同,执行的是无监督学习过程。未标记的数据通过人工神经网络进行训练,以创建生成词向量的 Word2Vec 模型。与其他方法不同,向量大小并不像语料库中唯一词的数量那么大。向量的大小可以根据语料库大小和项目类型来选择。这对于非常大的数据特别有用。例如,如果我们假设一个大型语料库中有 300 000 个唯一词,当使用 One Hot Encoding 创建向量时,会为每个词创建一个大小为 300 000 的向量,其中一个元素的值为 1 和其他为 0。但是,通过在 Word2Vec 端选择向量大小 300(可以或多或少取决于用户的选择),可以避免不必要的大向量操作。
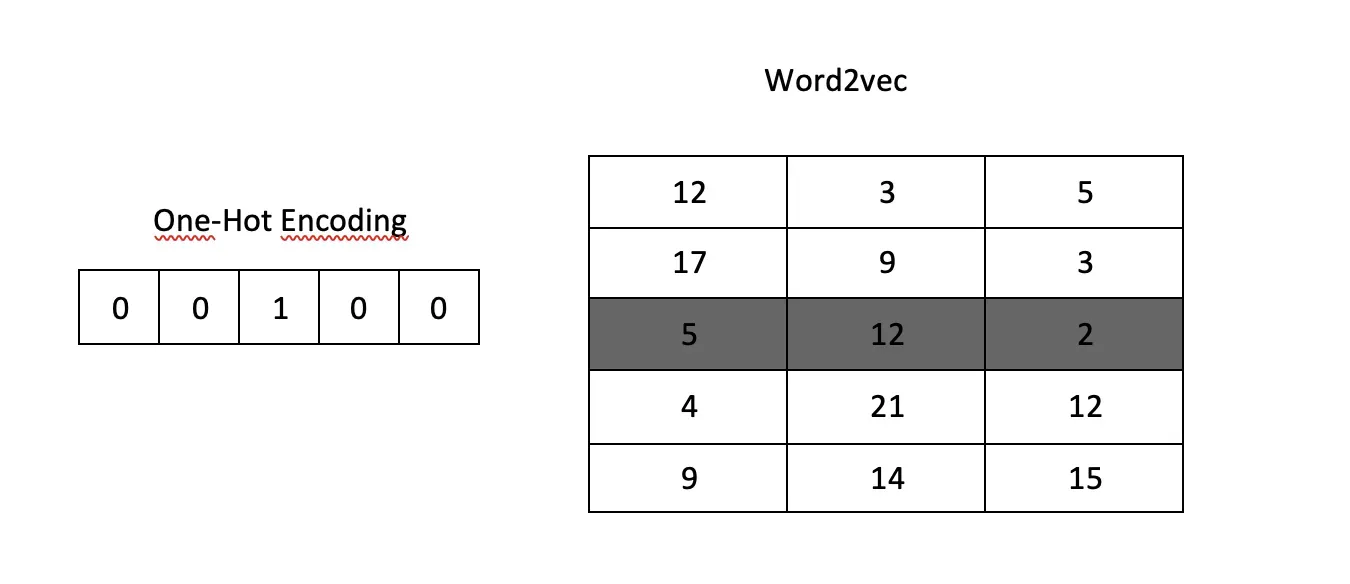
“Royal”的向量化如图3所示。如果用One Hot Encoding对一个五词句子中的“Royal”这个词进行向量化,则得到第一个向量表达式(输入向量)。可以看出,这个向量的大小与句子中单词的总数一样多。但是,如果向量化过程是用 Word2Vec 完成的,这一次会创建一个由三个单元 [5,12,2] 组成的向量。
kaggle (https://www.kaggle.com/anu0012/hotel-review) 中的酒店评论数据集用于应用 Word2Vec 模型训练。作为示例给出的所有代码都可以在这里找到。[0][1]
import pandas as pd
import re
from nltk.corpus import stopwords
from gensim.models import Word2Vec
import multiprocessing
csv_path = ".../hotel-reviews.csv"
df = pd.read_csv(csv_path)
def clean_data(text):
text = re.sub(r'[^ \nA-Za-z0-9À-ÖØ-öø-ÿ/]+', '', text)
text = re.sub(r'[\\/×\^\]\[÷]', '', text)
return text
def change_lower(text):
text = text.lower()
return text
stopwords_list = stopwords.words("english")
def remover(text):
text_tokens = text.split(" ")
final_list = [word for word in text_tokens if not word in stopwords_list]
text = ' '.join(final_list)
return text
def get_w2vdf(df):
w2v_df = pd.DataFrame(df["sentences"]).values.tolist()
for i in range(len(w2v_df)):
w2v_df[i] = w2v_df[i][0].split(" ")
return w2v_df
def train_w2v(w2v_df):
cores = multiprocessing.cpu_count()
w2v_model = Word2Vec(min_count=4,
window=4,
size=300,
alpha=0.03,
min_alpha=0.0007,
sg = 1,
workers=cores-1)
w2v_model.build_vocab(w2v_df, progress_per=10000)
w2v_model.train(w2v_df, total_examples=w2v_model.corpus_count, epochs=100, report_delay=1)
return w2v_model
df[["sentences"]] = df[["sentences"]].astype(str)
df["sentences"] = df["sentences"].apply(change_lower)
df["sentences"] = df["sentences"].apply(clean_data)
df["sentences"] = df["sentences"].apply(remover)
w2v_df = get_w2vdf(df)
w2v_model = train_w2v(w2v_df)由于它区分大小写,因此所有单词都转换为小写。然后,清除特殊字符和停用词。 nltk 库用于无效词。如果需要,这些词也可以完全手动确定。执行这些操作之前的例句如下。
“我丈夫和我在这家酒店住过几次。虽然不是最高档的酒店,但我们喜欢这样一个事实,即我们可以步行到芬威球场——大约几英里。它很干净,工作人员非常乐于助人。我唯一的抱怨是浴室里的风扇很吵,当你打开灯时会自动打开,我们尽量把灯关掉。我们住过更昂贵的酒店,这些酒店都收取互联网和早餐费用,这些都包括在内。会再呆在那里。”
数据预处理后会出现的新情况如下。
“丈夫入住酒店时间虽然最高档的酒店爱情事实步行英里芬威清洁工作人员住宿投诉风扇浴室嘈杂自动变亮尝试保持光线很可能我们住过更昂贵的酒店收费互联网早餐包括住宿”
完成这些过程后,进行 Word2Vec 训练。训练期间使用的参数:
min_count :目标词在语料库中的最小出现次数。特别是对于非常大的 copruse,保持此限制较高会进一步提高成功率。但是,对于小型数据集,保持较小会更准确。
window :是直接影响目标表达式向量计算的相邻词的个数。例如,“他是一个非常好的人。”对于 window =1 ,单词“a”和“good”在“very”词向量的形成中是有效的。当 window = 2 时,“is”、“a”、“good”和“person”这些词在创建“very”词向量方面是有效的。
size :它是要为每个元素创建的向量的大小。
alpha : 初始学习率
min_alpha :它是在训练期间学习率将线性下降的最小值。
sg :指定训练算法将如何工作。如果 sg 的值为 1,则使用 skip-gram 算法,否则使用 CBOW 算法。
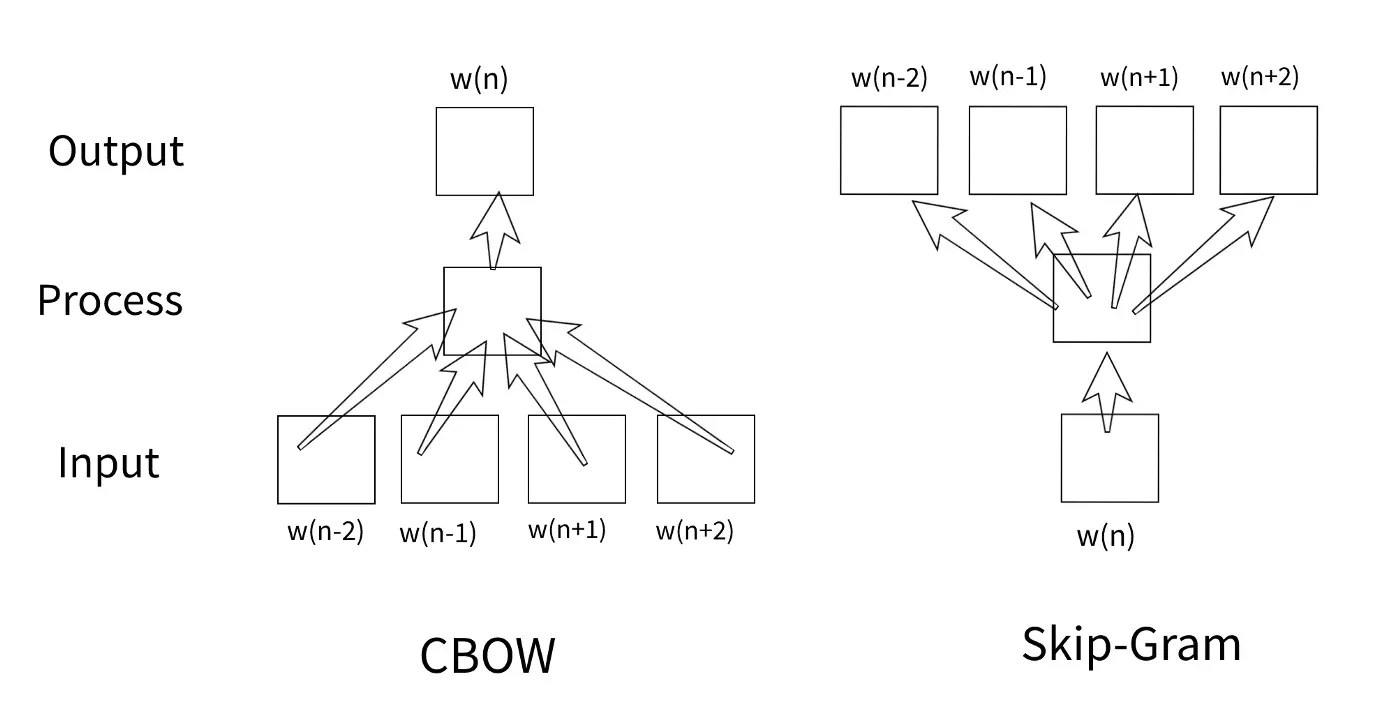
CBOW(Continuous Bag of Words)与 Skip-gram 算法的区别如图 4 所示。在使用 CBOW 算法的训练中,与目标词相邻的词作为输入,而目标词本身是作为输出获得。在skip-gram算法中,目标词本身作为输入,相邻词作为输出。
worker :训练可以并行执行。可以使用workers参数确定用于此的核心数量。
如果你想通过训练得到的模型来查看“great”这个词的向量;
w2v_model["great"]
>>>array([ 3.03658217e-01, -1.56424701e-01, -8.23674500e-01,
.
.
.-1.36196673e-01, 8.55127215e-01, -7.31807232e-01, 1.36362463e-01],
dtype=float32)print(w2v_model["great"].shape)
>>>(300,)
与“great”、“terrible”、“boston”、“valet”最接近的10个词如下。
w2v_model.wv.most_similar(positive=["great"])
>>>[('excellent', 0.8094755411148071),
('fantastic', 0.7735758423805237),
('perfect', 0.7473931312561035),
('wonderful', 0.7063912153244019),
('good', 0.7039040327072144),
('amazing', 0.6384587287902832),
('loved', 0.6266685724258423),
('nice', 0.6253951787948608),
('awesome', 0.6186609268188477),
('enjoyed', 0.5889394283294678)]
---------------------------------
w2v_model.wv.most_similar(positive=["terrible"])
>>>[('bad', 0.5275813341140747),
('poor', 0.504431962966919),
('horrible', 0.4722219705581665),
('awful', 0.42389577627182007),
('worst', 0.40153956413269043),
('dirty', 0.3467090427875519),
('disgusting', 0.32588857412338257),
('horrendous', 0.3157917261123657),
('lousy', 0.30114778876304626),
('uncomfortable', 0.3005620837211609)]
---------------------------------
w2v_model.wv.most_similar(positive=["boston"])
>>>[('chicago', 0.519180417060852),
('seattle', 0.5126588940620422),
('dc', 0.4830571711063385),
('bostons', 0.4459514617919922),
('copley', 0.4455355107784271),
('city', 0.44090309739112854),
('newbury', 0.4349810481071472),
('fenway', 0.4237935543060303),
('philadelphia', 0.40892332792282104),
('denver', 0.39840811491012573)]
---------------------------------
w2v_model.wv.most_similar(positive=["valet"])
>>>[('parking', 0.7374086380004883),
('car', 0.6263512969017029),
('garage', 0.6224508285522461),
('retrieving', 0.5173929929733276),
('self', 0.5013973712921143),
('inandout', 0.4847780168056488),
('selfpark', 0.47603434324264526),
('fee', 0.47458043694496155),
('per', 0.4741314947605133),
('parked', 0.4707031846046448)]* FastText
FastText 算法的工作逻辑与 Word2Vec 类似,但最大的区别在于它在训练时也使用了 N-grams 的单词 [4]。虽然这增加了模型的大小和处理时间,但它也使模型能够预测单词的不同变体。例如,假设“Windows”这个词在训练数据集中,我们想在训练完成后得到“Wndows”这个词的向量。如果对这些操作使用 Word2Vec 模型,则会给出一个错误,即字典中不存在单词“Wndows”,并且不会返回任何向量。但是,如果此过程使用 FastText 模型,则向量都将返回,并且“Windows”一词将在最接近的词中。如上所述,训练中不仅包括单词本身,还包括 N-gram 变体(例如单词“Windows”的 3-gram 表达式 -> Win、ind、ndo、dow、ows)。尽管如今 FastText 模型在许多不同的领域都得到了应用,但它经常是首选,尤其是在 OCR 工作中需要词嵌入技术时。尤其是与其他不能容忍丝毫 OCR 错误的技术相比,FastText 在获得不直接在其自身词汇表中的偶数词的向量方面提供了巨大优势。因此,在可能出现单词错误的问题上,它比其他替代方案领先一步。
上述矢量化方法是当今最常用的技术。它们每个都有不同的用途。在需要词向量化的研究中,首先要确定问题,然后根据这个问题优先选择向量化技术。事实上,每种技术都存在不同的情况。
除此之外,还有上下文表示,例如 ELMO 和 BERT[5]。这些问题将在下一篇文章中讨论。
Github
所有代码都可以在 https://github.com/ademakdogan/word2vec_generator 找到。在这个项目中,word2vec 训练可以根据需要在任何 csv 文件中确定的列自主完成。将作为操作结果创建的 word2vec 模型保存在“模型”文件夹下。示例用法如下所示。这个项目也可以在 docker 上运行。 src/training.py 中的参数可以根据数据大小进行优化。[0]
python3 src/w2vec.py -c </Users/.../data.csv> -t <target_column_name>GitHub:https://github.com/ademakdogan[0]
领英:https://www.linkedin.com/in/adem-akdo%C4%9Fan-948334177/[0]
Referanslar
[1]史蒂文斯,S.S.(1946 年)。 《论量表理论》。科学,新系列,103.2684,677-680。
[2] 相泽明子,(2003 年)。 “tf-idf 措施的信息论视角”。信息处理和管理。三十九(1),45-65。 doi:10.1016/S0306–4573(02)00021–3[0][1]
[3]托马斯·米科洛夫等人。 (2013)。 “向量空间中词表示的有效估计”。 arXiv:1301.3781[0][1]
[4] Armand Joulin、Edouard Grave、Piotr Bojanowski、Tomas Mikolov,(2017 年)。 “高效文本分类技巧包”,会议:计算语言学协会欧洲分会第 15 次会议论文集:第 2 卷。
[5]Devlin Jacob、Chang Ming-Wei、Lee Kenton、Toutanova Kristina,(2018 年)。 “BERT:用于语言理解的深度双向转换器的预训练”
文章出处登录后可见!