原文标题 :Taking Keras and TensorFlow to the Next Level
将 Keras 和 TensorFlow 提升到新的水平
充分利用 Keras 和 TensorFlow 的 11 个提示和技巧

Keras 是一个美丽的项目。虽然 TensorFlow 和 PyTorch 曾经争夺最先进的技术,但 Keras 的目标是我们这些需要完成工作的专业人士。我们可以使用去年的模型,而不是押注下一个 Transformer-killer 或 ResNet 崇拜者。作为 TensorFlow 的 Keras 的一部分近两年,现在表明该框架不惜一切代价拥抱易用性和生产力而不是速度。作为 TensorFlow 和 Keras 的用户,我在本文中分享了我多年来开发的一组技巧和窍门,旨在将这些框架提升到一个新的水平。
我强调这不是一个优化指南。相反,这些技巧旨在使开发模型和实现自定义功能变得更容易——所有这些都不会牺牲 Keras 最可爱的方面,它为您完成了大部分工作。
Here we go.
始终使用功能 API
使用 Keras 定义模型的主要方法有三种:作为层列表(顺序方法)、作为函数组合(函数方法)或通过继承模型(子类方法)。走出树,总是选择功能性方法。
import tensorflow as tf
input = tf.keras.layers.Input(shape=(64,))
hidden_layer = tf.keras.layers.Dense(256)(input) # composition!
output = tf.keras.layers.Dense(2)(hidden_layer)
model = tf.keras.Model(inputs=input, outputs=output)在上面的例子中,我们定义了一个 64 维的输入层,然后我们定义了一个有 256 个神经元的隐藏层,最后是一个二分类输出层。功能方面位于第 4 行和第 5 行的末尾。隐藏层是处理输入的函数。同样,输出是处理隐藏层的函数。在第 6 行定义的模型本身只是这个函数调用链的开始和结束。
您可以在 Keras 文档中阅读有关功能 API 的更多信息。[0]
使用 Functional API 的原因很简单:它有最好的支持并且没有限制。相比之下,顺序方法仅支持前馈模型(不允许跳过连接或分支),而子类化 API 对保存/加载模型和分布式训练的支持有限。此外,其他不太常见的功能,例如为 Web 或移动设备移植模型,在使用函数式 API 时也往往会更好地工作。
使用闭包创建块
使用函数式 API 时最大的问题是如何在坚持函数式语法的同时创建可重用的片段。解决方案?关闭。
闭包的一般定义是一个引用在其外部定义的变量的函数。在计算机科学词汇中,它“捕获”了这些变量。在 Python 中,这与嵌套函数(定义在其他函数中的函数)的概念密切相关,但不仅限于此。这是一个例子:
import tensorflow as tf
def resblock(n_filters):
def _block(start):
if start.shape[-1] != n_filters:
start = tf.keras.layers.Conv2D(n_filters, (1,1), (1,1), 'same')(start)
flow = tf.keras.layers.BatchNormalization()(start)
flow = tf.keras.layers.Activation('relu')(flow)
flow = tf.keras.layers.Conv2D(n_filters, (3,3), (1,1), 'same')(flow)
flow = tf.keras.layers.BatchNormalization()(start)
flow = tf.keras.layers.Activation('relu')(flow)
flow = tf.keras.layers.Conv2D(n_filters, (3,3), (1,1), 'same')(flow)
end = tf.keras.layers.Add()([flow, start])
return end
return _block
input = tf.keras.layers.Input(shape=(224,224,3))
block1 = resblock(256)(input)
block2 = resblock(256)(block1)
#...上面的代码片段展示了如何创建一个函数 (resblock),该函数返回另一个函数 (_block),该函数捕获“n_filters”参数。当调用传递层时,第二个函数将通过添加典型 ResBlock 的所有步骤来继续函数调用链,如原始论文(2015、2016)中所定义。[0][1]
使用这种语法的美妙之处在于它允许您将超参数(定义为第一个函数的参数)与调用层的先决条件(定义为内部函数的参数)分开。此外,它允许您在两个级别上放置自定义逻辑。例如,上面的示例展示了如何使用 1v1 卷积预处理“start”参数以确保它至少具有“n_filter”通道。
import tensorflow as tf
def Attention2D(n_filters):
bottleneck = n_filters // 8
def _block(q, k, v):
_, h, w, _ = q.shape
n = h * w
q_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(q)
k_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(k)
v_ = tf.keras.layers.Conv2D(n_filters, (1,1), (1,1), 'same')(v)
# All reshaping and processing done with Keras layers
q_ = tf.keras.layers.Reshape(target_shape=(n, bottleneck))(q_)
k_ = tf.keras.layers.Reshape(target_shape=(n, bottleneck))(k_)
v_ = tf.keras.layers.Reshape(target_shape=(n, n_filters))(v_)
# Attention scores
s = tf.keras.layers.Dot(axes=(2,2))([q_, k_]) # matmul
s = tf.keras.layers.Activation('softmax')(s)
# Output
o = tf.keras.layers.Dot(axes=(1,1))([s, v_])
o = tf.keras.layers.Reshape((h, w, n_filters))(o)
return o
return _block
def SelfAttention2D(n_filters):
def _block(start):
return Attention2D(n_filters)(start, start, start)
return _block
input = tf.keras.layers.Input(shape=(32,32,32))
attention = SelfAttention2D(64)(input)
#...
对于高级用户:在一个更复杂的示例中展示闭包,我们实现了一个 2D 瓶颈查询-值-键注意块,类似于 Self-Attention GANs 中描述的内容。首先,我们定义超参数 n_filters,并且在第一个函数的范围内,我们将瓶颈级别指定为 n_filters 的八分之一。然后,在内部函数中,我们使用 1v1 卷积来限制查询和值项,并将所有三个输入重塑为一维向量。接下来,我们将注意力分数计算为查询和值之间的 softmax 点积,最后,将其与关键术语相结合以获得输出。[0]
从第 27 行开始,我们创建了第二个闭包,以简化我们刚刚编码为 2D Self-Attention 块的 2D Attention,该块同时将单个输入映射为查询、值和键。这些实现一起展示了如何使用闭包的外部和内部范围,以及如何组合闭包以进一步扩展其功能。
可以将第 18-21 行替换为内置的 tf.keras.layers.Attention 层,以减少从头开始的解决方案。我刚刚意识到在编写示例后:x[0]
为自定义代码使用 Ops
在层链中,虽然显而易见的是只有层可以链接在一起,但现实情况是大多数 TensorFlow 操作都可以用作层。我知道的唯一先决条件是获取和输出张量。使用原始操作而不是纯层的优势是多方面的。我强调它更具可读性,更轻量级,更透明。此外,使用 ops 具有完全的控制权。
import tensorflow as tf
def Attention2D(n_filters):
bottleneck = n_filters // 8
def _block(q, k, v):
_, h, w, _ = q.shape
n = h * w
q_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(q)
k_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(k)
v_ = tf.keras.layers.Conv2D(n_filters, (1,1), (1,1), 'same')(v)
# All reshaping and processing done with tensorflow operations
q_ = tf.reshape(q_, (-1, n, bottleneck))
k_ = tf.reshape(k_, (-1, n, bottleneck))
v_ = tf.reshape(v_, (-1, n, n_filters))
s = tf.math.softmax(tf.matmul(q_, k_, transpose_b=True)) # scores
o = tf.reshape(tf.matmul(s, v_), (-1, h, w, n_filters))
o = tf.reshape(tf.matmul(s, k_), (-1, h, w, n_filters))
return o
return _block在上面的代码片段中,计算注意力分数和输出所需的操作被转换为简单的 TensorFlow 操作。这种语法更接近于您在 Numpy、PyTorch 甚至 JAX 中看到的语法。
使用 ops 的缺点是需要创建权重。为此,最好尽可能坚持使用内置层。在上面的示例中,我们坚持使用卷积层,其余部分使用操作。对于那些熟悉注意力公式的人来说,有时它包括一个最终的缩放参数(gamma)。坦率地说,我不会打扰。
好的,对于那些不喜欢的人来说,可以使用 1v1 卷积或更好的批范数或层范数来模拟需要权重的简单缩放和移位操作。
为整洁的摘要包装自定义代码
使用 ops 的另一个缺点是它们在运行 model.summary() 时变得非常丑陋。例如,上面的代码片段产生以下内容:
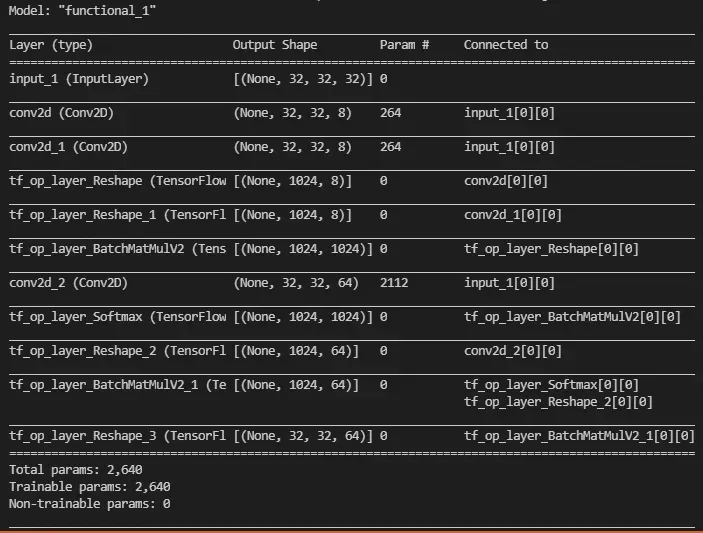
有两种方法可以解决这个问题:
第一种方法是最麻烦的,因为您需要处理 Keras 内部。但是,当您想用其他东西扩充现有的层实现时,第二个效果很好。一个完美的用例是 Addon 的 Spectral Normalization 实现。然而,第三个是最实用的(有一些警告)。[0][1]
这个想法是您可以将模型用作层(就像您可以将大多数操作用作层一样)。如果您有一组重复的层(如上面的注意力实现),您可以将其打包在模型中并在您的网络中使用此模型。这样,您可以将整个子网命名为单个实体。
需要注意两点:(1) 模型没有“.shape”属性,(2) 模型不会自动命名。如果自定义块尝试访问前一层的形状(例如上面的 ResBlock 实现),前者会咬你,如果它是模型,则会失败。后者将触发 Keras 异常,要求所有层都具有唯一的名称。因此,对于高级用户,我给你留下了一个 hacky 装饰器,它与唯一 id 的全局命名空间混淆,并使用 shape 属性对创建的模型进行猴子补丁🙈。
import tensorflow as tf
def Attention2D(n_filters):
bottleneck = n_filters // 8
def _block(q, k, v):
_, h, w, _ = q.shape
n = h * w
q_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(q)
k_ = tf.keras.layers.Conv2D(bottleneck, (1,1), (1,1), 'same')(k)
v_ = tf.keras.layers.Conv2D(n_filters, (1,1), (1,1), 'same')(v)
# All reshaping and processing done with tensorflow operations
q_ = tf.reshape(q_, (-1, n, bottleneck))
k_ = tf.reshape(k_, (-1, n, bottleneck))
v_ = tf.reshape(v_, (-1, n, n_filters))
s = tf.math.softmax(tf.matmul(q_, k_, transpose_b=True)) # scores
o = tf.reshape(tf.matmul(s, v_), (-1, h, w, n_filters))
return o
return _block
def MakeModel(func):
def wrapper(*args, **kwargs):
key = f'__{func.__name__}_guid'
if key not in globals().keys():
globals()[key] = 1
id = globals()[key]
name = f'{func.__name__}_{id}'
internal_fn = func(*args, **kwargs)
def _make_model(*args):
inputs = [tf.keras.layers.Input(shape=a.shape[1:]) for a in args]
output = internal_fn(*inputs)
model = tf.keras.Model(inputs=inputs, outputs=output, name=name)
model.shape = output.shape # monkey-patching!
return model(*args)
globals()[key] = id + 1
return _make_model
return wrapper
@MakeModel
def SelfAttention2D(n_filters):
def _block(start):
return Attention2D(n_filters)(start, start, start)
return _block
input = tf.keras.layers.Input(shape=(32,32,32))
attention = SelfAttention2D(32)(input)
attention = SelfAttention2D(32)(attention)
attention = SelfAttention2D(32)(attention)
#...
model = tf.keras.Model(inputs=input, outputs=attention)
model.summary()理解这个片段留给读者作为练习。
对自定义训练循环的评论
当 TensorFlow 2.0 发布时,要编写自定义训练例程,例如 GAN 的对抗训练,需要完全放弃 model.fit() 调用并从头开始重新实现它。这样做可不是一件小事。你必须完成你的 epochs,有效地获得下一批,编写训练和测试步骤,运行你的回调和指标,设置进度条等。混合精度或分布式训练的奖励积分。这是关于自定义训练循环的官方文档。[0]
TensorFlow 2.2 为我们提供了使用子类模型的一个很好的理由:您可以在使用 model.fit() 时覆盖 train_step、test_step 和 predict_step 调用来自定义训练。对于胆小的人来说,重新实现这些调用仍然不是一件容易的事。但是,您不需要重新发明整个战车,只需重新发明轮子即可。
到目前为止,我所知道的实现这些调用的最佳参考是源代码本身(它被视为文档)。你可以在这里找到它。
到目前为止,我建议在所有情况下都坚持使用功能 API。要继续它,您可以对 train_step、test_step 和 predict_step 调用进行修补。语法有点不对劲,monkey patching 是一个相当老套的解决方案,但它确实有效:)。毕竟,如果您正在编写自定义训练循环,那么您对 Python 的魔力非常了解。
无论如何,这是维基百科关于猴子补丁的陷阱部分[0]
import tensorflow as tf
from sklearn.datasets import make_blobs
input = tf.keras.layers.Input(shape=(64,))
hidden_layer = tf.keras.layers.Dense(256)(input)
output = tf.keras.layers.Dense(6)(hidden_layer)
model = tf.keras.Model(inputs=input, outputs=output)
X, y = make_blobs(n_samples=4096, centers=6, n_features=64)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
old_fn = model.train_step
n_calls = 0
def new_fn(data):
global n_calls
n_calls = n_calls + 1
return old_fn(data)
model.train_step = new_fn # monkey-patching!
model.run_eagerly = True
model.fit(X, y, batch_size=64, epochs=10)
print(f'There were a total of {n_calls} calls to the monkey-patched function!')这个愚蠢的片段展示了如何对 train_step 调用进行猴子修补以计算它被调用的次数。请注意,第 19 行激活了 Eager 模式以强制 Keras 不将此函数跟踪到图形模式,这将导致它仅被调用两次。现实世界的用例不需要使用 Eager 模式,仅用于像这样的愚蠢演示。
知道如何遍历模型
你有没有问过自己如何迭代所有模型层并在每个层上做一些事情?当您需要对每一层应用某些东西或收集内部数据(例如每一层的平均权重)时,遍历会非常方便。这里的提示是不要忘记迭代子模型。
def add_weight_decay(model, weight_decay):
def add_decay_loss(m, factor):
if isinstance(m, tf.keras.Model):
for layer in m.layers:
add_decay_loss(layer, factor)
else:
if isinstance(m, tf.keras.layers.DepthwiseConv2D):
m.add_loss(lambda: tf.keras.regularizers.l2(factor)(m.depthwise_kernel))
elif isinstance(m, tf.keras.layers.Conv2D) or isinstance(m, tf.keras.layers.Conv2DTranspose):
m.add_loss(lambda: tf.keras.regularizers.l2(factor)(m.kernel))
elif isinstance(m, tf.keras.layers.BatchNormalization):
m.add_loss(lambda: tf.keras.regularizers.l2(factor)(m.beta))
m.add_loss(lambda: tf.keras.regularizers.l2(factor)(m.gamma))
if hasattr(m, 'bias_regularizer') and m.use_bias:
m.add_loss(lambda: tf.keras.regularizers.l2(factor)(m.bias))
# weight decay and l2 regularization differs by a factor of 2
add_decay_loss(model, weight_decay / 2.0)这是一个如何向模型的所有层添加权重衰减的示例。该算法是对所有层进行深度优先扫描,使用递归来深入研究子模型、子模型的子模型等。注意此代码仅支持少数层,但易于扩展其他层。
使用正确的数据类型
使用正确的数据类型可以节省 50%(例如从 float64 到 float32)到 93% 的内存(从默认的 int64 到瘦 uint8)。我之前在下面的文章中写过这个:
特别是对于 TensorFlow 和 Keras,人们通常不加思索地坚持一件事:one-hot 编码和交叉熵。经验法则是使用 one-hot 编码对标签进行编码,并编写为每个类输出一个值的模型。这种做法通常是安全和正确的。然而,对于海量数据集或具有大量类的问题,使用稀疏标签和稀疏交叉熵可能会改变生活。
稀疏标签是以索引形式存储的标签:例如,第七类由数字 7 表示,而不是由第七个位置设置为 1 的零向量表示。对于 1000 类问题,这要紧凑几个数量级。一个 uint16 数字与一千个浮点数。默认情况下,大多数数据集都使用稀疏标签打包,我们强制它们为 one-hot。
稀疏交叉熵是分类交叉熵的一种变体,它将单热格式的模型输出与索引格式的真实标签进行比较。结合这种损失和稀疏标签,您可以节省大量内存,否则这些内存会花费在数英亩的零上。[0][1]
“自定义训练循环的评论”上的片段显示了使用稀疏交叉熵的示例。
Extra Tips
不要忘记急切模式:当 TensorFlow 开始抱怨形状和数据类型不兼容的内部错误时,它可能会很棘手。其中大多数在急切模式下很容易发现或不会发生。记住使用 Eager 模式可以帮助追踪错误的根源,或者在将错误缩小到图形模式问题(例如使用正确的数据类型)之前专注于更大的图景。
对 tf.data 也使用 Eager 模式:使用数据 API 很痛苦,因为它总是将所有内容都跟踪到图形模式。从 TensorFlow 2.6 开始,您可以激活数据 API 的调试模式。此功能仍被标记为实验性,但可以非常方便。这是如何做到的。[0]
使用 Lambda 回调:当使用昂贵的指标跟踪训练进度时,使用 Lambda 回调类注入代码以在 epoch 结束时运行是值得的。如果您的指标真的很慢,您可以使用 epoch 参数跳过在奇数 epoch 上执行代码或仅每十个 epoch 执行一次。[0]
让自己成为一个图书馆:当你使用深度学习时,你将不得不实现不同的层和架构。有些使用所有内置的东西作为构建块很容易实现,而另一些则不会。因此,保留一个方便的 layers.py 文件是值得的,其中包含您多年来必须编写的所有自定义内容。
这就是现在的全部。如果您对本文有任何疑问,请随时发表评论或与我联系。[0]
如果您是 Medium 的新手,我强烈建议您订阅。对于数据和 IT 专业人士来说,中型文章是 StackOverflow 的完美搭档,对于新手来说更是如此。请考虑在注册时使用我的会员链接。[0][1][2]
Thanks for reading :)
文章出处登录后可见!