前言
写这一章本来是想来介绍GBDT-LR这一个推荐模型的。但是这里面就涉及到了很多机器学习的基础树形算法,思前想后还是决定分成几篇文章来写,这里先介绍一下CART数,因为在GBDT中用来分类回归的树形结构就是CART,为了更好的理解这个推荐模型,首选需要的就是打好基础,介绍完CART之后,我就会介绍XGBoost等一些集成学习的东西,然后就是GBDT,当然了还有Xgboost。的确是一个大家族啊,当然了这些并不是全部的东西,还有LightGBM、catboost这几大巨头算法。这些之后再介绍吧。
一、CART简介
分类回归树(classification and regression tree, CART)模型由Breiman等人在1984年提出,是应用广泛的决策树学习方法。CART同样由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。
具体的实现方法其实就类似于在刷算法题的时候的二叉搜索树,如下图所示:

二、理论推导
理论推导部分还是也有着很多的数学公式,如果小伙伴是第一次来看CART那可能有点难受,而且在我看过的所有博客中很多都是在单纯的讲解公式,然后配个例子。在这里我会尝试着用自己的大白话来讲出自己的理解来的,希望可以给大家带来不一样的视觉体验。给定X和Y两个输入和输出变量,并且Y是连续变量,给定训练数据集![]() 。
。
接下来我们要做的就是如何进行CART的划分,首先要考虑的两个问题是如何先择划分点也就是如何选择划分特征,第二个就是每个叶子节点上面的输出特征值应该如何求?一个回归树对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值。换句大白话就是每个CADT中的非叶子节点都是一次输入特征的划分,并且当被划分到叶子结点的时候叶子结点的值就是要进行的输出值。假设CADT将输入空间化为了M个单元,![]() ,也就是将并且每个单元(叶子节点)上面都有着一个固定的输出值
,也就是将并且每个单元(叶子节点)上面都有着一个固定的输出值![]() 。则回归树的模型可以表示为:
。则回归树的模型可以表示为:

我们训练的误差可以使用平方误差![]() 来表示,用平方误差最小的准则求解每个单元上的最优输出值。
来表示,用平方误差最小的准则求解每个单元上的最优输出值。
那么我们图和对输入空间Y进行划分呢,我们可以用过遍历X中的特征来获取它对应的Y特征,在这里用s来表示,从而作为切分变量和切分点,由此而来定义两个区域:

然后就是如何寻求最有切分点了,首先就用到上面我们说的平方误差,先看公式:
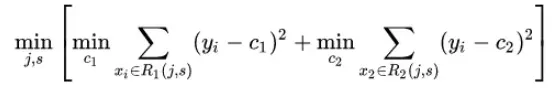
那么这个c如何求解呢,每个单元R上的c的最优值![]() 都是所有输入向量x对应y的均,即:
都是所有输入向量x对应y的均,即:
![]()
那么选定的最优切分点c_1和c_2的求解则是:
![]()
遍历所有输入变量,找到最优的切分变量j,构成一个对(j, s)。依此将输入空间划分为两个区域。接着,对每个区域重复上述划分过程,直到满足停止条件为止。这样就生成一颗回归树。这样的回归树通常称为最小二乘回归树(least squares regression tree)。
然后贴一下算法的具体流程吧:

三、具体实例
首先先看一下李航老师书上的例子:

假设这里有10个训练样本的某个特征取值范围区间[0.5, 10.5], y的取值范围[5.0, 10.0], 我们学习一个提升树模型。

首先需要求出区域R以及c来:

并且
![]()
取s=1,则求得两个区域![]() 则分别求得这两个区域的输出值c:
则分别求得这两个区域的输出值c:

遍历全部的特征值x之后得到下表:

将c带入到均值方差中去得到

显然取s=5时,m(s)最小。因此,第一个最优切分变量为j=x、最优切分点为s=5。
然后继续对两个区域![]() 进行递归划分即可得到最终的结果。
进行递归划分即可得到最终的结果。
文章出处登录后可见!