总述
TinyBert主要探究如何使用模型蒸馏来实现BERT模型的压缩。
主要包括两个创新点:
- 对Transformer的参数进行蒸馏,需要同时注意embedding,attention_weight, 过完全连接层之后的hidden,以及最后的logits。
- 对于预训练语言模型,要分为pretrain_model 蒸馏以及task-specific蒸馏。分别学习pretrain模型的初始参数以便给压缩模型的参数一个好的初始化,第二步学习pretrain model fine-tuning的logits让压缩模型再次学习。
模型
模型主要分成三个部分:
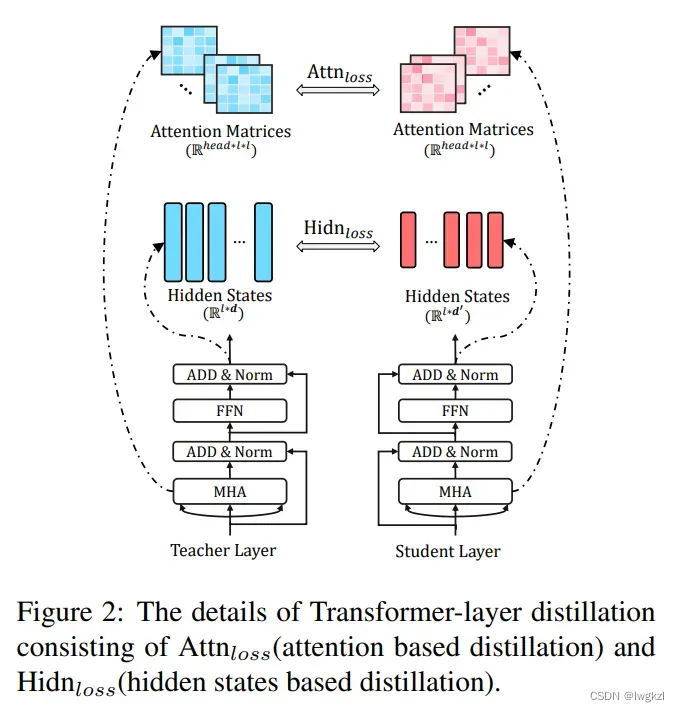
- Transformer Layer的蒸馏
主要蒸馏两部分,第一是每一层的attention weight,第二是每一层输出的hidden。如下图所示。
公式:
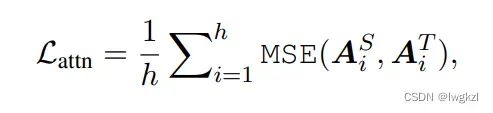
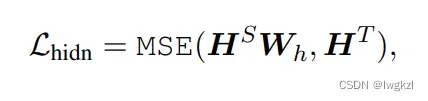
使用均方误差作为损失函数, 并且在hidden对比的时候引入了一个Wh,这是因为学生模型和老师模型的向量编码维度不一致(学生模型的向量维度要更小)
2. Embedding layer的蒸馏
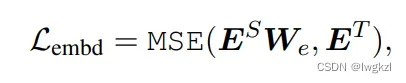
E表示embeddign层的输出。
3. Predict logits的蒸馏
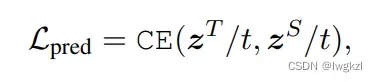
z表示老师模型与学生模型在task-specific任务上的预测概率。
此外还有一个细节便是数据增强,学生模型在task-specific任务上fine-tuning的时候,Tinybert对原数据集做了数据增强。(ps:这其实非常奇怪,因为后文实验中可以看到,去除数据增强之后,模型的效果比之之前的sota并无太大提升。而文章主要的卖点是模型蒸馏ummm)
实验和结论
-
蒸馏各个层次的重要性
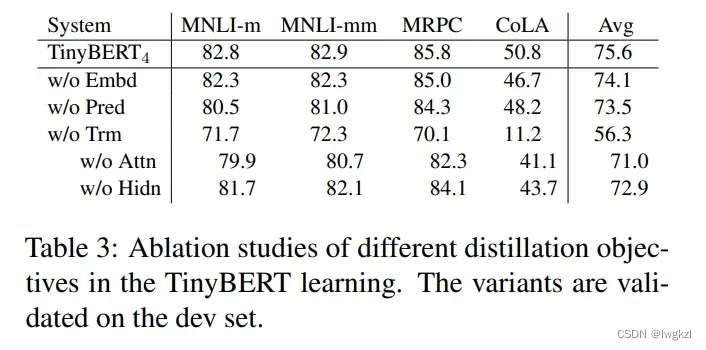
可以看出,从重要性来说: Attn > Pred logits > Hidn > emb. 其中,Attn,Hidn以及emb在两个阶段的蒸馏中均有用到。 -
数据增强的重要性
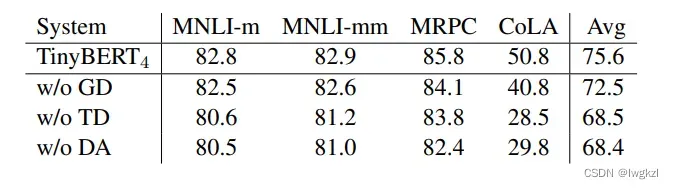
GD (General Distillation)表示第一阶段蒸馏。
TD (Task-specific Distillation)表示第二阶段蒸馏.
and DA (Data Augmentation).表示数据增强。
这张表得到的结论是,数据增强很重要 : (。 -
学生模型需要学习老师模型的哪些层
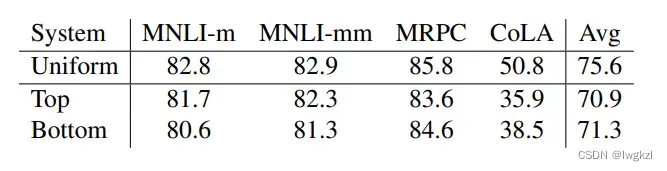
假设学生模型4层,老师模型12层
top表示学生模型学习老师的后4层(10,11,12),bottom表示学习老师模型的前4层(1,2,3,4),uniform表示均匀学习(等间距,3,6,9,12)。
可以看到,均匀学习各层的效果更好。
代码
# 此部分代码应该写在Trainer里面, loss.backward之前。
# 获取学生模型的logits, attention_weight以及hidden
student_logits, student_atts, student_reps = student_model(input_ids, segment_ids, input_mask,
is_student=True)
# 在测试环境下获取老师模型的logits, attention_weight以及hidden
with torch.no_grad():
teacher_logits, teacher_atts, teacher_reps = teacher_model(input_ids, segment_ids, input_mask)
# 分为两步,一步是学习attentino_weight和hidden,还有一步是学习predict_logits。 总思想就是对学生模型的输出和老师模型的输出做loss,其中针对attention_weight和hidden是MSE loss, 针对logits是交叉熵。
if not args.pred_distill:
teacher_layer_num = len(teacher_atts)
student_layer_num = len(student_atts)
assert teacher_layer_num % student_layer_num == 0
layers_per_block = int(teacher_layer_num / student_layer_num)
new_teacher_atts = [teacher_atts[i * layers_per_block + layers_per_block - 1]
for i in range(student_layer_num)]
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device),
student_att)
teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device),
teacher_att)
tmp_loss = loss_mse(student_att, teacher_att)
att_loss += tmp_loss
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
tmp_loss = loss_mse(student_rep, teacher_rep)
rep_loss += tmp_loss
loss = rep_loss + att_loss
tr_att_loss += att_loss.item()
tr_rep_loss += rep_loss.item()
else:
if output_mode == "classification":
cls_loss = soft_cross_entropy(student_logits / args.temperature,
teacher_logits / args.temperature)
elif output_mode == "regression":
loss_mse = MSELoss()
cls_loss = loss_mse(student_logits.view(-1), label_ids.view(-1))
loss = cls_loss
tr_cls_loss += cls_loss.item()
文章出处登录后可见!