原文标题 :Why Not Use CNN to Extract Features?
为什么不使用 CNN 来提取特征?
如何在数据中发现意外模式
意外中也有美。
就在你认为你已经把一切都弄清楚的时候,一些新的东西突然出现并让你陷入困境。数据分析也是如此。当您查看数据集,试图寻找模式和趋势时,有时您会遇到一些不太有意义的事情。这就是异常检测的用武之地。
异常检测是识别数据中异常模式的过程。这些不寻常的模式可能是任何不符合正常趋势或行为的东西,它们可能是由多种原因引起的,例如数据收集错误、异常值甚至恶意活动。异常检测很重要,因为它可以帮助您发现您无法通过其他方式发现的数据问题。
异常检测有多种方法,但在这篇博文中,我们将重点介绍一种特定方法:流形学习。流形学习是一种寻找高维数据的低维表示的技术。
Auto-Encoders
自动编码器是一种人工神经网络,分为两个主要元素:编码器网络和解码器网络。
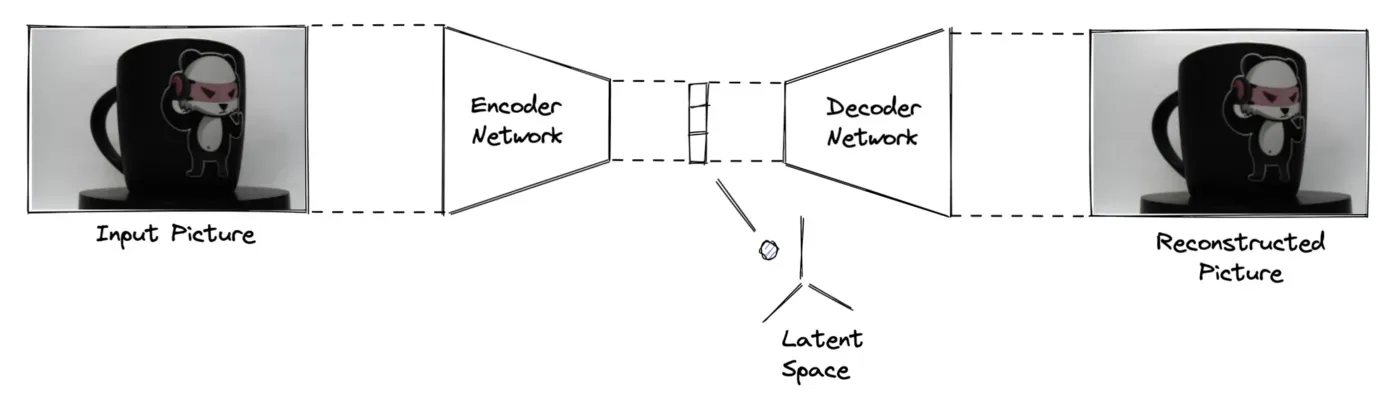
每个部分执行以下操作:
- 编码器网络:在称为潜在空间的低维空间中减少高维输入。
- 解码器网络:将潜在空间映射为输入图片的表示。
自动编码器属于非监督学习技术的范畴,因为数据不需要标签。编码器降低输入数据的维度,解码器从潜在空间再现输入,优化两个网络以减少输入和输出数据之间的差异。
编码器和解码器网络可以设计为服务于特定任务。在图片的情况下,我们通常使用我们训练的卷积神经网络 (CNN),以减少输入 X 与其重建输出 X’ 之间的均方误差 (MSE),即
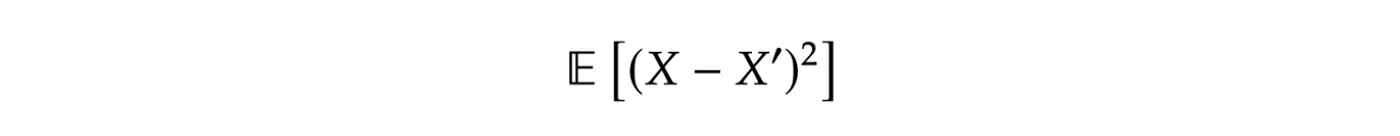
自动编码器的流行用例是:
- Dimensional reduction
- Image compression
- Data denoising
- Anomaly detection
对于后者,经典方法侧重于通过查看输入与其重建版本之间的差异来发现异常。假设是当输入与训练数据集相似但在异常周围产生高重建误差时,自动编码器表现良好。为了使用这种方法,我们用无异常数据训练自动编码器,并查看自动编码器输入和输出之间的差异。
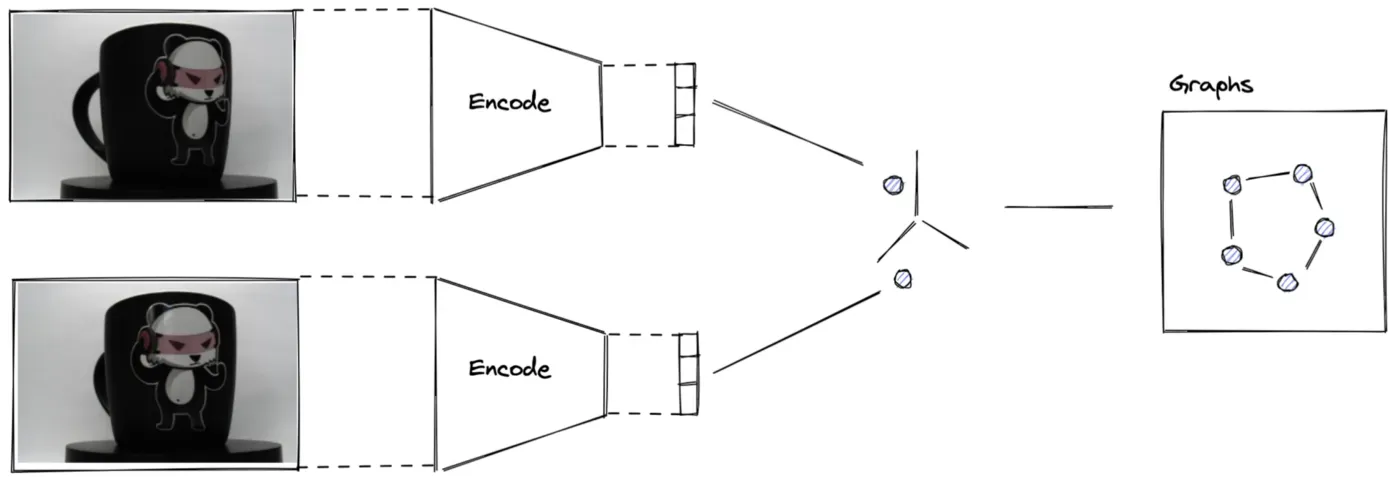
另一种可能性是确保模型学习潜在空间的有意义的表示,并直接在这个低维空间中发现异常。这就是拉普拉斯自动编码器的用武之地。
但首先,我们必须构建一个 K-Nearest-Neighbor Graph 来训练 Laplacian Auto-Encoder。
K-最近邻图
k-最近邻图(k-NNG)是一个图,其中每个节点都连接到它的最近邻。例如在下图中,每个节点都连接到其最近的三个点。
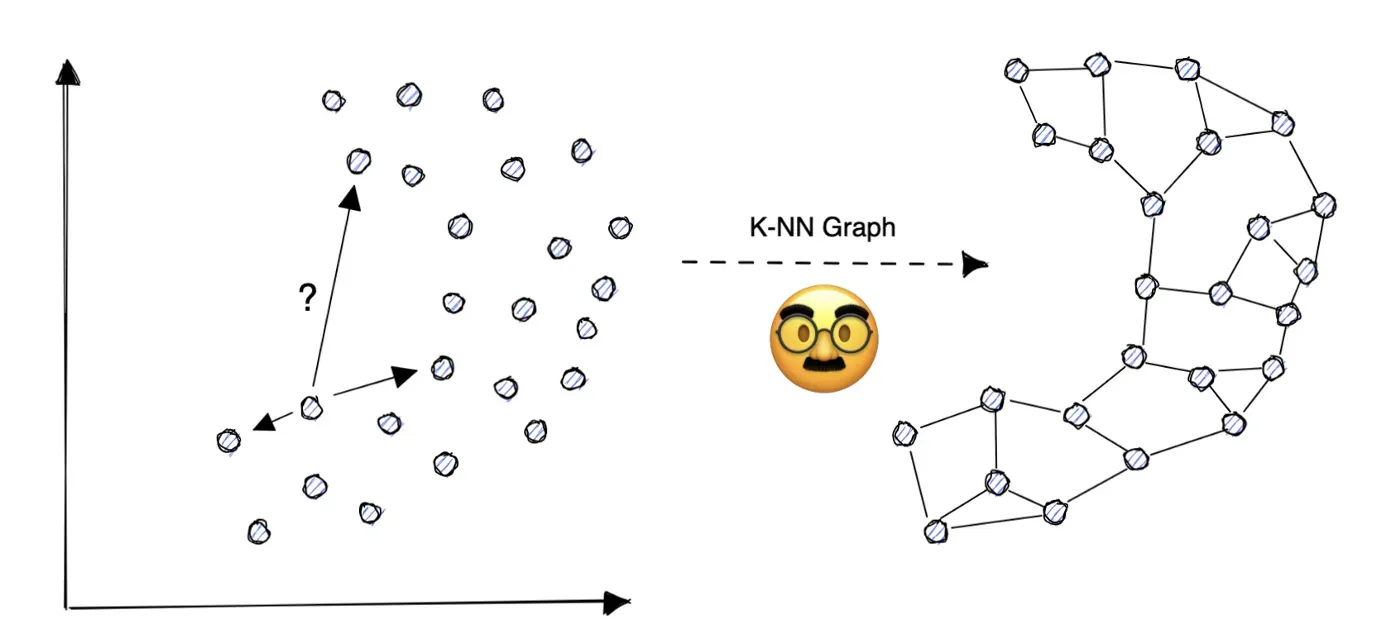
欧几里得范数可能是最直观的接近度度量,因为它给出了两点之间的最短距离。可以根据应用选择其他流行的距离度量,例如 Minkowski、Manhattan、Hamming 或 Cosine。[0]
对于高维输入,例如图片,我们需要选择一个可以测量图像之间相似性的距离度量,例如结构相似性指数度量(SSIM)或基于定向梯度直方图(HOG)。
例如,我们可以使用 HOG 描述符并使用 Wasserstein 度量或卡方距离计算两个直方图之间的距离。
在选择度量时,我们需要记住一个好的距离度量应该是:
- 信息丰富:距离可以直接转化为相似度
- 自反:“A 到 B”和“B 到 A”的距离相等
- 灵敏:距离变化时变化平滑
- 有界的:指标在限制范围内
Laplacian Auto-Encoder
使用自动编码器时最大的挑战是确保模型真正学习到潜在空间的有意义的表示。
拉普拉斯自动编码器也使用编码器-解码器结构,但不同之处在于用于训练两个网络的损失函数。
自动编码器仍然经过训练,以减少输入与其重构输出之间的误差,但在损失函数中添加了一个正则化项,以保持高维和低维之间的相同邻居。这意味着输入空间中的关闭数据点将在潜在空间中保持关闭。
为了构建拉普拉斯自动编码器,我们首先必须在输入数据上构建 KNN 图,并在损失函数上添加一个正则化项,以鼓励在映射到潜在空间后保留相同的邻居。
从 KNN 图中,我们得出一个权重矩阵 (W),当 Xi 和 Xj 之间的距离较大时,W(i, j) 较小,而当 Xi 和 Xj 之间的距离较小时,其 W(i, j) 较大。正则化函数定义如下:
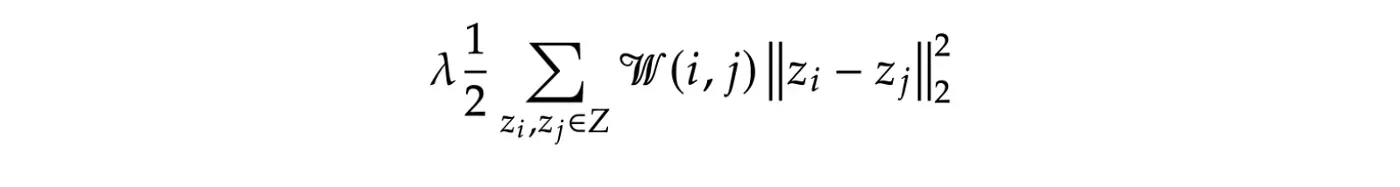
其中 Zi 和 Zj 分别表征来自输入 Xi 和 Xj 的潜在空间中的映射点。第一个参数 (lambda) 是正则化权重,我们可以将其调整为模型的超参数。
拉普拉斯自动编码器旨在优化的完整损失函数定义如下:
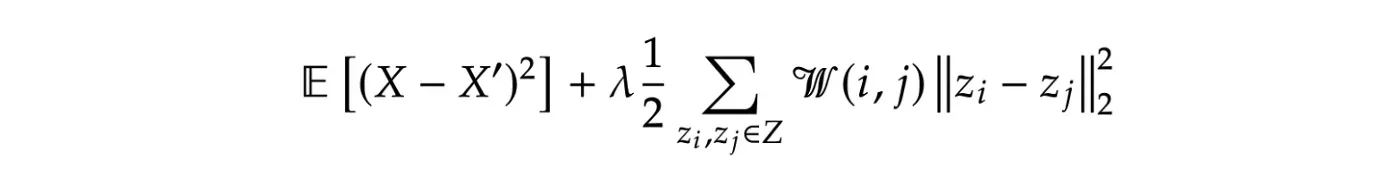
Final Words
那么,当您的数据不完全符合标准时,您能做些什么呢?
使用卷积神经网络 (CNN) 在您的数据中发现意想不到的模式。 CNN 非常适合从图像中提取特征,并且已被证明在发现传统方法难以检测到的模式方面非常有效。
使用无监督方法优于有监督等效方法的主要优点是我们不需要标记任何数据,这项任务可能非常昂贵。权衡是我们可能会检测到不是异常的模式,而是数据集固有的模式。
我希望您喜欢本教程并发现它很有用。如果您有任何问题或意见,请随时在下面发布。
想了解更多关于 Anthony 的工作和项目的信息吗?在 Medium、LinkedIn 和 Twitter 上关注他。[0][1][2]
文章出处登录后可见!