如何为深度学习编码病历
基于 Google Brain 的“可扩展且准确的电子健康记录深度学习”及其补充材料的简化插图。[0]

Background
十多年前,医疗保健行业开始系统地将医疗保健数据数字化。希望有一天,我们能够协调来自不同来源的数据,形成患者的“纵向视图”,其中包括有关患者健康的所有信息,从就诊、住院、用药史到免疫接种记录、家族史和生活方式观察。人们普遍认为,一旦具备了患者医疗保健数据的丰富性和完整性,我们就可以大大提高医疗质量,降低运营成本,推进医疗/药物研究。
如果您关注医疗技术领域的最新趋势,您会发现希望开始实现。在一些受控环境中,医疗保健提供者、付款人和研究人员开始将越来越多的来自特殊上游系统的数据拼凑起来,以构建全面的患者记录。随着这一令人兴奋的发展,现在出现了价值百万美元的问题:我们如何真正利用这些数据记录的力量?
虽然数据分析或机器学习模型开发通常会引起更多关注,但不应忽视导致这一点的数据工程的重要性。这篇博文有一个非常具体的重点。它研究了如何对医疗记录进行编码并使它们适用于深度学习,特别是时间序列学习。它通过简化示例和可视化图表说明了 Google Brain 的“可扩展且准确的电子健康记录深度学习”及其补充材料中提出的方法。如果您不想阅读原始 30 多页的深奥内容,这篇博文是您的不错选择。事不宜迟,让我们开始吧。[0]
学习任务的设置
学习任务的设置是对重症监护病房 (ICU) 患者进行预测。 Google Brain 和许多其他研究人员之所以选择 ICU 设置,是因为与其他医疗保健数据相比,ICU 的数据通常是最完整且可用于研究的数据。我们可以预测的事情有很多。我们可以预测临床结果——在这种情况下,死亡率(死亡)事件。我们可以预测资源利用率,在这种情况下,超过 7 天的停留时间。我们可以预测护理质量,在这种情况下,出院后 30 天再入院。
传统方法/模型依赖于精心挑选的特征变量,在预测时进行评估。这篇博文最后总结了一些流行的 ICU 分析模型。然而,Google Brain 团队假设,通过数据验证证明是成功的,通过考虑所有可用的患者数据并执行时间序列分析,可以实现对上述所有结果的更准确预测。这里的意义在于
- 它不需要手动选择特征——模型将学习权衡和组合特征
- 并且使用所有患者的历史数据,而不是其他流行的非深度学习模型,其中仅使用当前快照。
现在,随着学习任务设置的明确,让我们深入了解编码程序,看看医疗记录是如何为学习任务转换的。
Encoding Procedures
Google Brain 团队首先将他们从合作医院收到的 ICU 数据转换为一个开放的医疗数据标准,称为 FHIR。完全解释 FHIR 需要另外 10 篇博文。但它的核心思想并不难掌握。出于本文的目的,我们可以将其视为 JSON 数据。每个医疗保健概念都有一个 JSON 数据模式——Patient、Observation、Condition、MedicationRequest 等等——它们都是医疗保健概念。 JSON 数据模式将各个医疗保健概念的字段形式化。例如,患者有姓名、生日;观察具有价值等。从专有医疗保健数据到我们需要的 JSON 数据的转换相对简单,因为大多数专有医疗保健系统也基于常见的医疗保健概念对其数据进行建模。
这里需要注意的一件重要事情是,虽然结构转换是可以实现的,但医疗保健中的语义翻译极具挑战性。因为医疗保健数据采用各种(有时是专有的)编码系统。 “心力衰竭”在一种编码系统中可能是“123”,而在另一种编码系统中可能是“1a2b3c”。不同的编码系统具有不同的粒度和层次结构。将所有内容统一到一个单一的编码系统中是一项艰巨的任务。 Google Brain 团队的方法不需要编码系统的协调,这是一个至高无上的优势。正如我们稍后将看到的,他们可以这样做,因为他们将数据内容视为令牌并将令牌转换为嵌入。因此,只要医疗保健数据集为自己使用一组一致的编码系统(它们到底是什么并不重要),就应该没问题。让我们看看下面的具体步骤。
Step 1: tokenization
第一步是标记所有医疗保健概念中的所有领域。如果它是一个文本字段,我们只是用空格分隔它。例如,“高葡萄糖”变成[“高”,“葡萄糖”]。对于数字字段,仅将普通数字视为标记是没有意义的。所以我们需要编码更多的上下文。我们将名称(通常是编码值、数量和单位)连接在一起形成一个标记。例如,{code:”33747003″,quantity:10.2,unit:”mmol/L”} 变为 “33747003_10.2_mmol/L”。有关说明,请参见图 1。或者,我们可以对数量进行分位数以减少令牌的稀疏性。我们在第 1 步之后得到的是医疗保健概念的实例,其中每个实例的所有字段都已标记化。我们将每个实例的时间戳计算为相对于预定义预测时间(图 1 中的 dt1 和 dt2)的增量时间(以秒为单位)。预测时间通常为入院后 24 小时或出院时。
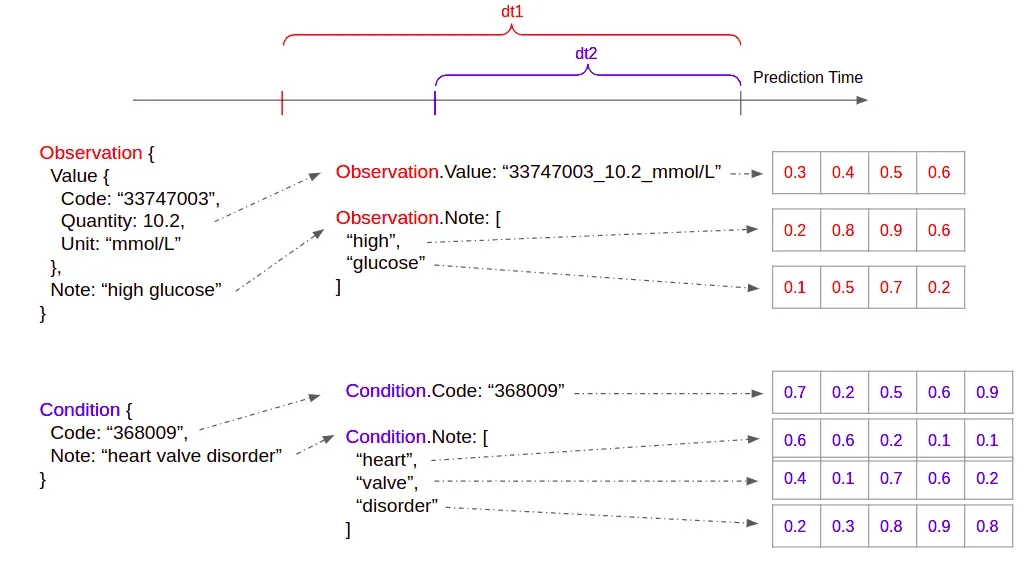
Step 2: embedding
对于每个医疗保健概念中的每个领域,我们都会建立一个预定义大小的词汇表。我们不使用全局词汇表,因为不同的领域具有不同的医疗保健语义。将所有概念的所有标记甚至所有领域的所有标记混合在一个概念中以构建词汇表是没有意义的。然后我们为每个令牌训练一个嵌入。嵌入是与预测任务共同学习的。请注意,我们故意为给定医疗保健概念中的所有字段选择相同的嵌入维度。正如我们稍后将看到的,它使聚合更容易。
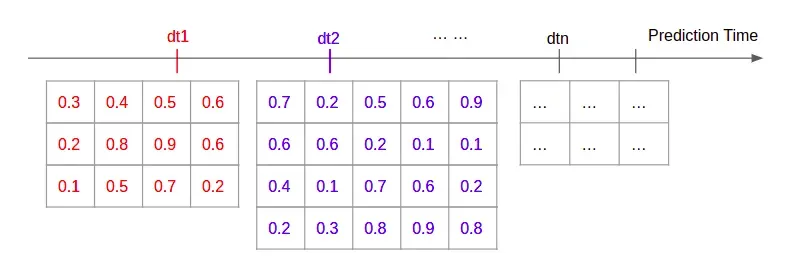
在第 2 步之后,我们得到的结果类似于图 2。它开始类似于典型的自然语言处理输入,其中您有一系列嵌入,您可以将其输入到循环神经网络 (RNN)。但是,当前格式存在三个问题:
- 每个实例都是一个训练示例。 ICU 设置中有数百甚至数千个数据点。我们知道 RNN 在长序列上表现不佳。
- 训练示例具有可变维度,由所讨论的概念和实例中的标记数量决定。 RNN 无法处理可变长度嵌入。
- 实例/训练示例的时间戳不是均匀分布的。当特定事件发生时具有重要的临床意义。嵌入没有捕捉到这一点。
第 3 步将解决所有 3 个问题。
Step 3: aggregation
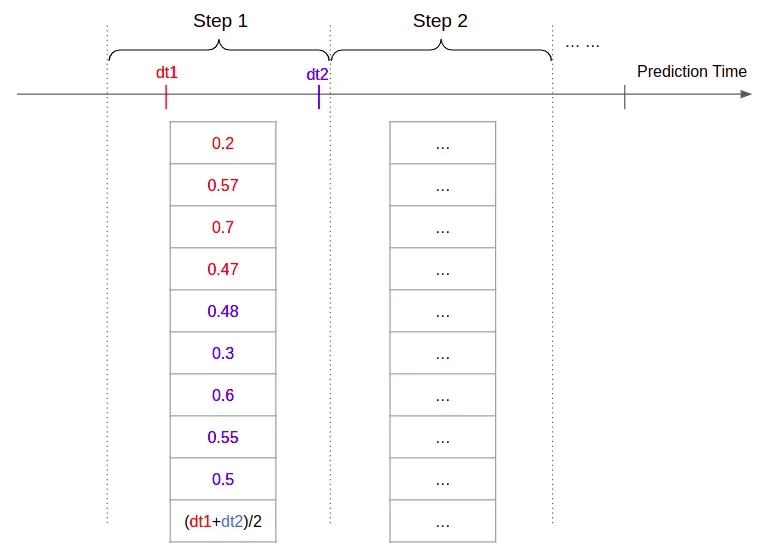
长序列的第一个问题很容易解决。我们只需要将数据点划分为均匀的时间步长。时间步长可能是 1 小时或几个小时,可以作为超参数进行调整。我们将聚合给定时间步长中的所有数据点以形成单个训练示例。
请记住,给定医疗保健概念中的所有字段共享相同的嵌入维度。因此,我们可以取一个实例中所有字段嵌入的平均值,以形成该实例的聚合嵌入。如果一个概念有多个实例,我们可以进一步平均实例嵌入以形成该概念的嵌入。由于医疗保健概念是一个预定义的枚举列表,我们可以将概念嵌入连接在一起以形成一个固定大小的示例。如果一个概念没有出现在时间步长中,我们只需将其嵌入设置为全 0。可变维度的第二个问题现在已经解决了。请注意,我们始终使用平均值进行聚合,但您可以想象使用其他聚合方案。
为了解决时间戳含义的最后一个问题,我们取时间戳中所有实例的时间戳的平均值,并将其附加到我们通过fields->instance和instances->concept聚合获得的固定大小嵌入的末尾.这样,时间戳的信号也会在训练示例中进行编码。
有关最终编码结果的说明,请参见图 3。我们现在有一个不那么长的固定大小嵌入序列,其中考虑了事件时间戳。我们现在可以将其提供给 RNN。
Conclusion
在这篇博文中,我们将逐步说明如何为 RNN 模型编码医疗记录。它首先将从合作伙伴组织收到的专有数据格式转换为开放标准 JSON 格式。这使我们能够理解源数据集的结构。然后它对每个 JSON 字段中的内容进行标记,并为每个标记构建一个嵌入。最后,它在合理的时间范围内聚合令牌嵌入,以创建一个合理长的固定大小嵌入序列,这适用于 RNN 模型输入。
上述数据处理的意义有两方面:
- 它不需要将医疗记录融合到全球编码系统中,从而节省了大量的人工工作。
- 它以同质的方式对整个患者历史中的所有记录进行编码,以便在模型训练期间可以将所有记录考虑在内。
附录:其他常见的非深度学习 ICU 数据分析模型
早期预警评分 (EWS) 通常在入院后 24 小时计算,以预测死亡的可能性。它使用呼吸频率、氧饱和度、温度、血压、心率和意识等级作为变量。每个变量都有一个由普通医学知识确定的正常范围。基于查找表计算分数,以表征变量与其正常范围的距离。如果所有分数的总和超过一个阈值,则意味着死亡的可能性很高。
再入院的医院分数通常在出院时计算。它考虑了血红蛋白水平、钠水平、入院类型、先前入院次数、住院时间、住院时间是否与癌症有关,以及住院期间是否进行了医疗程序。与上述 EWS 类似,基于已建立的医学知识,每个因素的值都被转换为风险评分,其总和描述了再入院的总体风险。
长期住院的 Liu 评分通常在入院后 24 小时计算。它是逻辑回归模型(使用适当的正则化技术),将年龄、性别、病情类别、诊断代码、接受的医院服务和生命体征的实验室测试等变量因素考虑在内,以产生长期住院的概率数。
文章出处登录后可见!