目录
- 0 专栏介绍
- 1 最优控制理论
- 2 线性二次型问题
- 3 LQR的价值迭代推导
- 4 基于差速模型的LQR控制
- 5 仿真实现
-
- 5.1 ROS C++实现
- 5.2 Python实现
- 5.3 Matlab实现
0 专栏介绍
🔥附C++/Python/Matlab全套代码🔥课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。
🚀详情:图解自动驾驶中的运动规划(Motion Planning),附几十种规划算法
1 最优控制理论
最优控制理论是一种数学和工程领域的理论,旨在寻找如何使系统在给定约束条件下达到最佳性能的方法。它的基本思想是通过选择合适的控制输入,以最小化或最大化某个性能指标来优化系统的行为。其中,系统的动态行为通常用状态方程描述,状态表示系统在某一时刻的内部状态。状态空间表示将系统的状态和控制输入表示为向量,通常用微分方程或差分方程来描述系统的演化。在最优控制理论中,会设置代价函数或者目标函数,用来衡量系统行为的好坏的函数。性能指标可以是各种形式,如最小化路径长度、最小化能量消耗、最大化系统稳定性等。最优控制理论在许多领域都有广泛的应用,包括航空航天、机器人学、经济学、生态学等。
2 线性二次型问题
若系统动力学特性可以用一组线性微分方程表示,且性能指标为状态变量和控制变量的二次型函数,则此类最优控制问题称为线性二次型问题。线性二次调节器(Linear Quadratic Regulator, LQR)是求解线性二次型问题常用的求解方法之一,其假设系统零输入且期望状态为零。
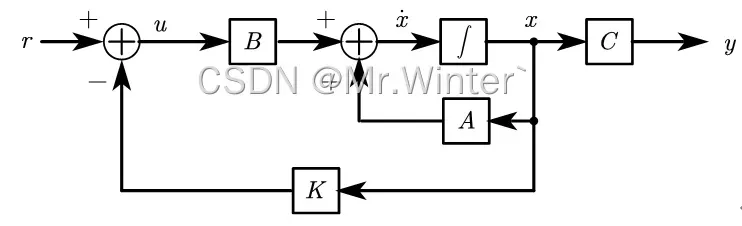
如图所示的全状态反馈控制系统。设控制误差,其中
、
分别是第
个控制时间步的实际状态和期望状态,则全反馈控制律由误差驱动
上式表明可以通过选取状态变量和输入变量,使系统等效为零输入(跟踪期望输入)且期望状态为零(消除状态误差),满足应用LQR进行最优控制的条件。定义代价函数
其中与
是用户设定的半正定矩阵,前者衡量了系统状态向期望轨迹的收敛速度,后者衡量了系统能量消耗的相对大小,二者互相制约——希望系统快速收敛往往需要加强控制力度,导致能量耗散。因此, 与 需要结合具体场景进行调节。
3 LQR的价值迭代推导
针对进行优化,引入价值迭代策略,价值迭代的理论基础请看Pytorch深度强化学习1-4:策略改进定理与贝尔曼最优方程详细推导
即第步到终端的代价等于当前步的代价与第
步到终端的代价之和。根据
的定义,其一定能表示成二次型
,对于优化问题
,令
则,对比
可得
将代入
可得
从而
称为离散迭代黎卡提方程。根据贝尔曼最优原理,在迭代过程中会逐步收敛。
4 基于差速模型的LQR控制
根据差分机器人运动学模型
选择状态量和状态误差量
,控制量
和控制误差量
,可得
其中
接着按照LQR算法求解即可。
5 仿真实现
5.1 ROS C++实现
核心代码如下所示
Eigen::Vector2d LQRPlanner::_lqrControl(Eigen::Vector3d s, Eigen::Vector3d s_d, Eigen::Vector2d u_r)
{
Eigen::Vector2d u;
Eigen::Vector3d e(s - s_d);
e[2] = regularizeAngle(e[2]);
// state equation on error
Eigen::Matrix3d A = Eigen::Matrix3d::Identity();
A(0, 2) = -u_r[0] * sin(s_d[2]) * d_t_;
A(1, 2) = u_r[0] * cos(s_d[2]) * d_t_;
Eigen::MatrixXd B = Eigen::MatrixXd::Zero(3, 2);
B(0, 0) = cos(s_d[2]) * d_t_;
B(1, 0) = sin(s_d[2]) * d_t_;
B(2, 1) = d_t_;
// discrete iteration Ricatti equation
Eigen::Matrix3d P, P_;
P = Q_;
for (int i = 0; i < max_iter_; ++i)
{
Eigen::Matrix2d temp = R_ + B.transpose() * P * B;
P_ = Q_ + A.transpose() * P * A - A.transpose() * P * B * temp.inverse() * B.transpose() * P * A;
if ((P - P_).array().abs().maxCoeff() < eps_iter_)
break;
P = P_;
}
// feedback
Eigen::MatrixXd K = -(R_ + B.transpose() * P_ * B).inverse() * B.transpose() * P_ * A;
u = u_r + K * e;
return u;
}

5.2 Python实现
核心代码如下所示
def lqrControl(self, s: tuple, s_d: tuple, u_r: tuple) -> np.ndarray:
dt = self.params["TIME_STEP"]
# state equation on error
A = np.identity(3)
A[0, 2] = -u_r[0] * np.sin(s_d[2]) * dt
A[1, 2] = u_r[0] * np.cos(s_d[2]) * dt
B = np.zeros((3, 2))
B[0, 0] = np.cos(s_d[2]) * dt
B[1, 0] = np.sin(s_d[2]) * dt
B[2, 1] = dt
# discrete iteration Ricatti equation
P, P_ = np.zeros((3, 3)), np.zeros((3, 3))
P = self.Q
# iteration
for _ in range(self.lqr_iteration):
P_ = self.Q + A.T @ P @ A - A.T @ P @ B @ np.linalg.inv(self.R + B.T @ P @ B) @ B.T @ P @ A
if np.max(P - P_) < self.eps_iter:
break
P = P_
# feedback
K = -np.linalg.inv(self.R + B.T @ P_ @ B) @ B.T @ P_ @ A
e = np.array([[s[0] - s_d[0]], [s[1] - s_d[1]], [self.regularizeAngle(s[2] - s_d[2])]])
u = np.array([[u_r[0]], [u_r[1]]]) + K @ e
return np.array([
[self.linearRegularization(float(u[0]))],
[self.angularRegularization(float(u[1]))]
])

5.3 Matlab实现
核心代码如下所示
function u = lqrControl(s, s_d, u_r, robot, param)
dt = param.dt;
% state equation on error
A = eye(3);
A(1, 3) = -u_r(1) * sin(s_d(3)) * dt;
A(2, 3) = u_r(1) * cos(s_d(3)) * dt;
B = zeros(3, 2);
B(1, 1) = cos(s_d(3)) * dt;
B(2, 1) = sin(s_d(3)) * dt;
B(3, 2) = dt;
% discrete iteration Ricatti equation
P = param.Q;
% iteration
for i=1:param.lqr_iteration
P_ = param.Q + A' * P * A - A' * P * B / (param.R + B' * P * B) * B' * P * A;
if max(P - P_) < param.eps_iter
break;
end
P = P_;
end
% feedback
K = -inv(param.R + B' * P_ * B) * B' * P_ * A;
e = [s(1) - s_d(1); s(2) - s_d(2); regularizeAngle(s(3) - s_d(3))];
u = [u_r(1); u_r(2)] + K * e;
u = [linearRegularization(robot, u(1), param), angularRegularization(robot, u(2), param)];
end

完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇
版权声明:本文为博主作者:Mr.Winter`原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/FRIGIDWINTER/article/details/137479248