1. SqueezeSegV1 简介
1.1 文章信息
(1)标题:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud (2018)
(2)文章链接:https://arxiv.org/pdf/1710.07368.pdf
(3)文章代码:https://github.com/BichenWuUCB/SqueezeSeg
1.2 算法特点
高速
1.3 算法摘要
在本文中,我们讨论了从 3D LiDAR 点云中对道路对象进行语义分割的问题。特别是,我们希望检测和分类感兴趣的实例,例如汽车、行人和骑自行车的人。我们将该问题描述为一个逐点分类问题,并提出了一种基于卷积神经网络(CNN)的端到端管道称为 SqueezeSeg:CNN 将转换后的 LiDAR 点云作为输入,直接输出逐点标签匹配,然后通过一个条件随机场(CRF)进行细化,该随机场作为一个循环层来实现。然后通过传统的聚类算法获得实例级标签。我们的 CNN 模型是在 KITTI 数据集中的 LiDAR 点云上训练的,我们的逐点分割标签来自 KITTI 的 3D 边界框。为了获得额外的训练数据,我们在流行的视频游戏《侠盗猎车手V》(GTA-V)中构建了一个 LiDAR 模拟器,以合成大量真实的训练数据。我们的实验表明,SqueezeSeg 以惊人的速度和稳定的运行时间(每帧8.7±0.5毫秒)实现了高精度,非常适合自动驾驶应用。此外,对合成数据的额外培训可以提高对真实数据的验证准确性。我们的源代码和合成数据将是开源的。
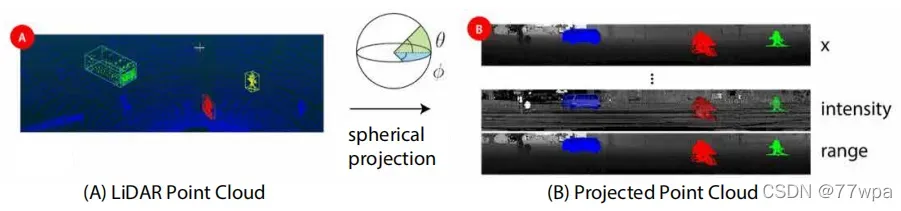
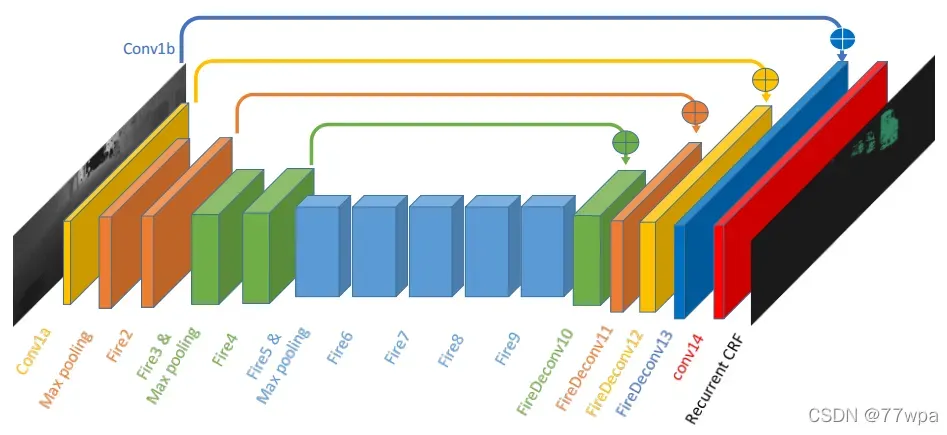
1.4 参考资料
参考文章原文和源码,看一遍,大概就明白了。下面的参考资料也可以理解。
参考
2. SqueezeSegV2 简介
2.1 文章信息
(1)标题:SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud (2019)
(2)文章链接:https://arxiv.org/pdf/1809.08495v1.pdf
(3)文章代码:https://github.com/xuanyuzhou98/SqueezeSegV2
2.2 算法特点
更快的速度和更高的精度
2.3 算法摘要
早期的工作证明了基于深度学习的点云分割方法的前景;然而,这些方法需要加以改进,以便实际有用。为此,我们介绍了一种新的模型SqueezeSegV2,该模型对 LiDAR 点云中的衰减噪声更具鲁棒性。凭借改进的模型结构、训练损失、批量标准化和额外的输入通道,SqueezeSegV2 在真实数据上训练时实现了显著的精度提高。用于点云分割的训练模型需要大量标记的点云数据,获取这些数据非常昂贵。为了避免收集和标注的成本,可以使用 GTA-V 等模拟器创建无限量的标记合成数据。然而,由于领域转移,基于合成数据训练的模型往往不能很好地推广到现实世界。我们通过一个域自适应训练管道来解决这个问题,该管道由三个主要部分组成:1) 学习强度渲染,2)测地线相关对齐,3)渐进域校准。当在真实数据上进行训练时,我们的新模型显示分割精度比原来的 SqueezeSeg 提高了6.0-8.6%。当我们使用提出的领域适应管道在合成数据上训练我们的新模型时,我们对真实数据的测试精度几乎翻了一番,从29.0%到57.4%。我们的源代码和合成数据集将是开源的。
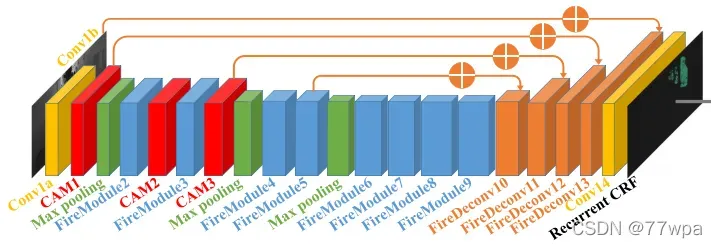
2.4 参考资料
参考文章原文和源码,看一遍,大概就明白了。下面的参考资料也可以理解。
参考
3. SqueezeSegV3 简介
3.1 文章信息
(1)标题:Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation (2020)
(2)文章链接:https://arxiv.org/pdf/2004.01803.pdf
(3)文章代码:https://github.com/chenfengxu714/SqueezeSegV3
3.2 算法特点
高精准度
3.3 算法摘要
LiDAR 点云分割是许多应用中的一个重要问题。对于大规模点云分割,实际的方法是投影一个3D点云,得到一个2D LiDAR 图像,并使用卷积进行处理。尽管常规 RGB 图像和 LiDAR 图像之间存在相似性,但我们发现,在不同的图像位置,LiDAR 图像的特征分布会发生剧烈变化。使用标准卷积来处理这样的 LiDAR 图像是有问题的,因为卷积滤波器会拾取仅在图像中特定区域中活动的局部特征。因此,网络的能力没有得到充分利用,分割性能下降。为了解决这个问题,我们提出了空间自适应卷积(SAC),根据输入图像的不同位置采用不同的滤波器。SAC 可以高效地计算,因为它可以实现为一系列元素级乘法、im2col 和标准卷积。这是一个总体框架,因此之前的几种方法可以被视为 SAC 的特例。使用 SAC,我们构建了用于 LiDAR 点云分割的 SqueezeSegV3,并在 SemanticKITTI 基准上以相当的推理速度比所有先前发布的方法至少高出 3.7% 的 mIoU。
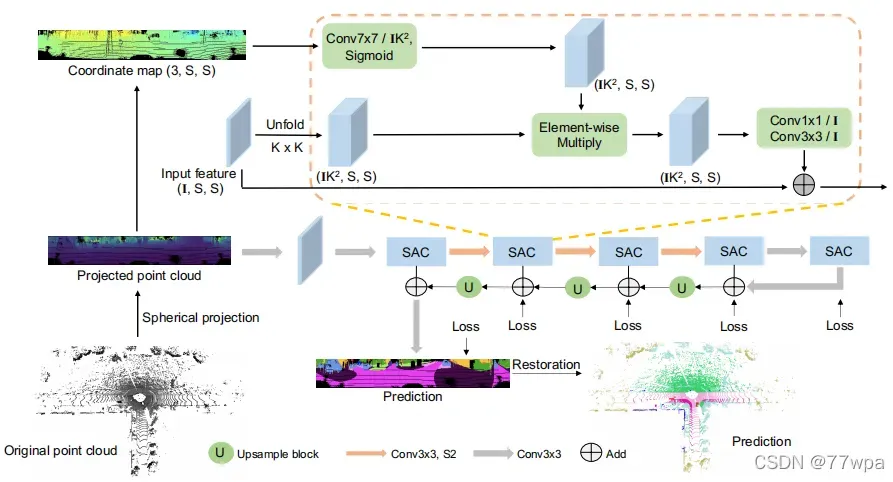
版权声明:本文为博主77wpa原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/i6101206007/article/details/123380620