前言
这篇主要是介绍下CRNN+CTC的原理和主要代码。
有两个难点:
- 双向LSTM原理
- CTC Loss原理
一、文本识别背景
文本识别是OCR的一个子任务,主要是识别一个固定区域(一般为文本检测后的结果)的文本内容,将图像信息转换为文字信息。
一般分为规则文本识别和不规则文本识别。
- 规则文本识别如:印刷字体、扫描文本等。
- 不规则文本识别一般出现在自然场景中,出现文本弯曲、形变、遮挡、模型等问题的本文识别任务。
数据集:
- 规则文本识别:IIIT5K(5000张)、SVT、IC13
- 不规则文本识别:IC15、SVTP(350张 多样性 高清)、CUTE
算法:
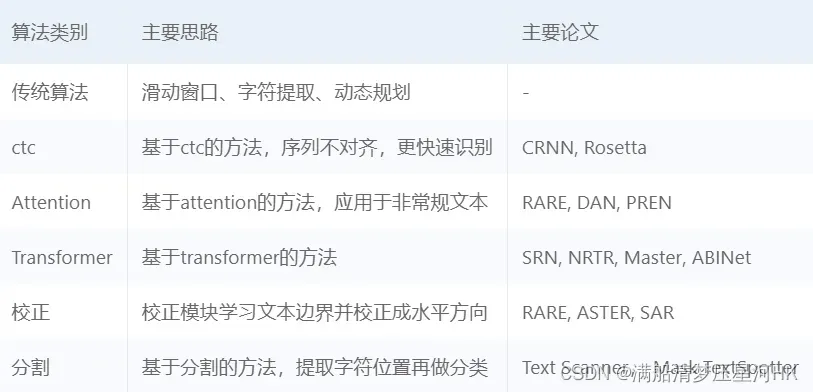
这里主要是先入个门,所以主要是研究最经典的文本识别算法(地位相当于Faster R-CNN):CRNN+CTC类型算法。
二、CRNN+CTC算法概述
基于CTC的最经典算法是CRNN(Convolutional Recurrent Neural Network)。它主要分为三个部分:图像特征提取模块CNN、图像上下文信息提取模型RNN(双向LSTM)、解码模块CTC。论文地址:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition(2015年)
架构图如下:
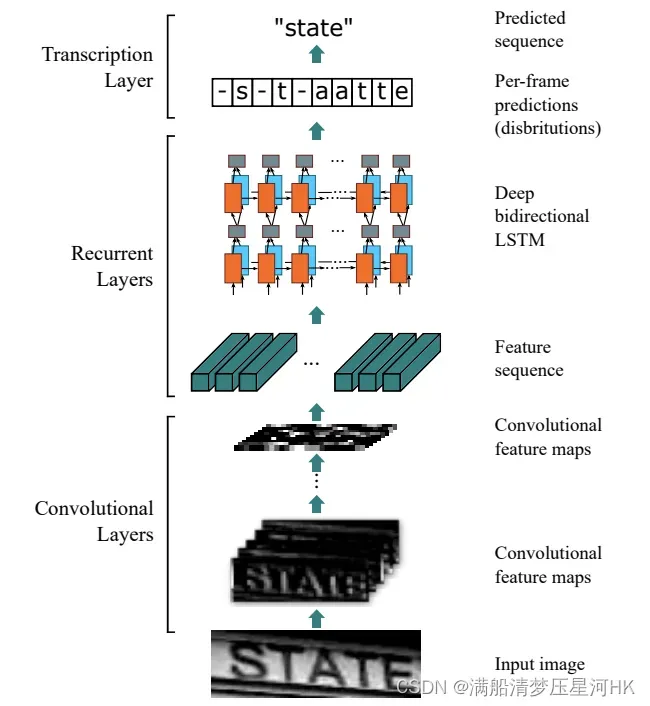
- 图像特征提取模块一般使用主流的卷积网络,如ResNet、MobileNet等。
- 由于文本图像的特殊性,输入数据中存在大量的上下文信息,而卷积神经网络特性使其更关注局部特征,缺乏长依赖的建模能力,因此使用卷积网络很难挖掘到文本之间的上下文关系。为了解决这个问题,CRNN引入双向LSTM(Long Short-Term Memory)可以有效的提取图片中的上下文信息。
- LSTM输出的特征序列输入到CTC模块代替softmax,可直接解码序列结果。
这种基于CTC的识别主要用来识别规则文本,速度较快,而且可以检测任意长度的字符,不会受序列长度不等的影响。所以CRNN+CTC的架构虽然出来了这么多年,依然还是主流的文本识别方法。
三、CRNN+CTC整体算法
传统的文本检测算法需要将字符一个个分割出来再扔到CNN里去分类,这种算法一般速度比较慢。
CRNN+CTC是一个end-to-end的文本识别算法,我们不需要将检测到的数字划分为单字符,无论你检测的数字长度多长,尺寸多宽,直接从头到尾给你识别出来。这样一来,我们就将单个字符的识别问题转化为序列的识别问题。
这个算法的难点在于:
- 使用LSTM解决序列化问题
- 使用CTC解决不定长序列对齐问题
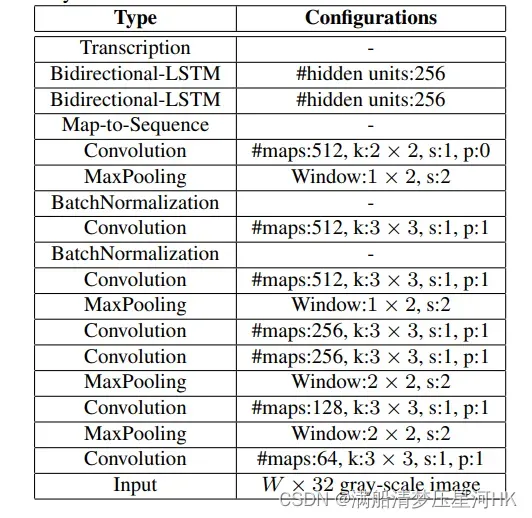
3.1、backbone:CNN
输入图像统一resize到bsx1x32x100,CNN后输出bsx512x1x26,再将其切成26xbsx512,形成一个特征序列,每一个都能得到对应原图的一块感受区域。
这部分比较简单,就是一个普通的CNN网络对图片进行局部特征提取。原论文使用的是若干的卷积+maxpool堆叠的cnn模块,如下图:
代码:
# 前6个卷积层 卷积前后的feature map大小不变
ks = [3, 3, 3, 3, 3, 3, 2] # 卷积层卷积尺寸3表示3x3,2表示2x2
ps = [1, 1, 1, 1, 1, 1, 0] # padding大小
ss = [1, 1, 1, 1, 1, 1, 1] # stride大小
nm = [64, 128, 256, 256, 512, 512, 512] # 卷积核个数
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1] # 确定输入channel维度
nOut = nm[i] # 确定输出channel维度
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i])) # 添加卷积层
# BN层
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
# Relu激活层
if leakyRelu:
cnn.add_module('relu{0}'.format(i), nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0) # [1,1,32,100] -> [1,64,32,100]
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # [1,64,32,100] -> [1,64,16,50]
convRelu(1) # [1,64,16,50] -> [1,128,16,50]
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # [1,128,16,50] -> [1,128,8,25]
convRelu(2, True) # [1,256,8,25]
convRelu(3) # [1,256,8,25]
cnn.add_module('pooling{0}'.format(2), nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # [1,256,8,25] -> [1,256,4,26]
convRelu(4, True) # [1,256,4,26] -> [1,512,4,26]
convRelu(5) # [1,512,4,26]
cnn.add_module('pooling{0}'.format(3), nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # [1,512,4,26] -> [1,512,2,27]
convRelu(6, True) # [1,512,2,27] -> [1,512,1,26]
self.cnn = cnn # cnn 原图:[1,1,32,100] -> [1,512,1,26] b,c,h,w
3.2、neck:LSTM
关于RNN和LSTM不是很熟的可以看下这篇博客: 【RCNN重要背景知识】RNN和LSTM的原理
两层双向LSTM结构。
假设我最终要预测一个字符的最大长度为26,所有字符是a~z这26个字符。
将CNN输出的26xbsx512的特征序列输入双向LSTM中,每个时刻对应一个bsx512,共26个时刻。送入双向LSTM,最终输出26xbsx37(1+字典长度)的特征向量。每一列存放当前字符属于-、a~z的概率分布,总概率相加为1。
双向LSTM:
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut) # *2因为使用双向LSTM,两个方向隐层单元拼在一起
def forward(self, input):
# input: [w,bs,h]=[26,1,512]
recurrent, _ = self.rnn(input) # [26,1,512] -> [26,1,512]
T, b, h = recurrent.size() # 26 1 512
t_rec = recurrent.view(T * b, h) # [26, 512]
output = self.embedding(t_rec) # [T * b, nOut] [26,256]
output = output.view(T, b, -1) # [26,1,256]
return output
定义两个双向LSTM
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
rcnn forward:
def forward(self, input):
# conv features input [b,c,h,w]=[bs,c,32,100]
conv = self.cnn(input) # [bs,512,1,26]
print(conv.size())
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2) # [bs,512,1,26] -> [bs,512,26]
conv = conv.permute(2, 0, 1) # [w, b, c] [26, bs, 512]
# rnn features
output = self.rnn(conv) # [26, bs, 512] -> [26,1,37]
return output
3.3、head:CTC测试时解码
原始的softmax解码,会求每一列的softmax,然后取最大的那个最为当前列的预测字符(这里就默认了当前字符串就是26个字符的),但是如果当前字符串长度不固定呢,那么相邻两个原素可能就会预测成一样的字符(重复了)。
难题:如何处理不定长序列对齐问题?
【测试时 很简单】
rcnn得到一个26x1x37的向量,26是时间步长(最多能识别26个字符),1是bs,37是每个字符属于(空格+字典长度)的概率分布,先softmax找找到最大概率的字符对应的下标,这样就找到了所有时间序列的预测字符index,再将预测字符进行解码。
with torch.no_grad():
model.eval()
preds = model(image) # pred (w c nclass) (26, 1, 37) 26为ctc生成路径长度也是传入rnn的时间步长,1是batchsize,37是字符类别数
_, preds = preds.max(2) # 取可能性最大的indecis size (26, 1)
preds = preds.transpose(1, 0).contiguous().view(-1) # 转成以为索引列表 [26, 1] -> [1,26] -> [26]
# 转成字符序列
preds_size = torch.IntTensor([preds.size(0)]) # 26
raw_pred = converter.decode(preds.data, preds_size.data, raw=True)
sim_pred = converter.decode(preds.data, preds_size.data, raw=False)
解码规则:idx=0,空字符,相邻时间预测的idx相同就删掉最后一个。
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(),
length)
# 带有空白符的原始预测结果
if raw:
# 预测的索引编号-1找到字母表中的字符,其中算法预测出0为空白符,减1后为-1恰好为最后一个
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
# 遇到编号为0和两个相连是相同字母且为后一个字母的不用转换
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
3.4、CTC Loss
【背景/为什么提出CTC?】
从前面的学习我们知道,CRNN最终可以得到一个26×37的矩阵,假设bs=1,其中26表示时间序列长度,37表示1个空白字符和36个字典字符的概率,也就得到了每个序列对每个字符的概率分布。
同样对应gt来说,我们可以知道这段序列中真实字符的标签。
举个例子(字典总共是h、e、l、o四个字符+一个空白字符):

看出问题在哪了吧?我们得到的预测序列长度和真实gt的序列是不一样长的,对应不上啊,那怎么知道预测值和真实值的差异?怎么计算损失呢???
所以,CTC Loss在干什么也就知道了吧。CTC Loss的本质:在给定预测序列(也就是知道每个时刻对所以有类别的概率分布)的情况下,找到最终能得到gt序列的总概率。这个概率越大,说明网络的效果越好,损失就越小;这个概率越小,说明网络的效果越差,损失就越大。
那这个最大概率怎么求的?如果刷题刷的比较多的朋友,肯定就一眼看出来了,这不就是一个动态规划的网格类问题嘛。
具体做法:将gt每个字符之间加一个空白符,作为dp的行,dp的列为各个序列,如下图
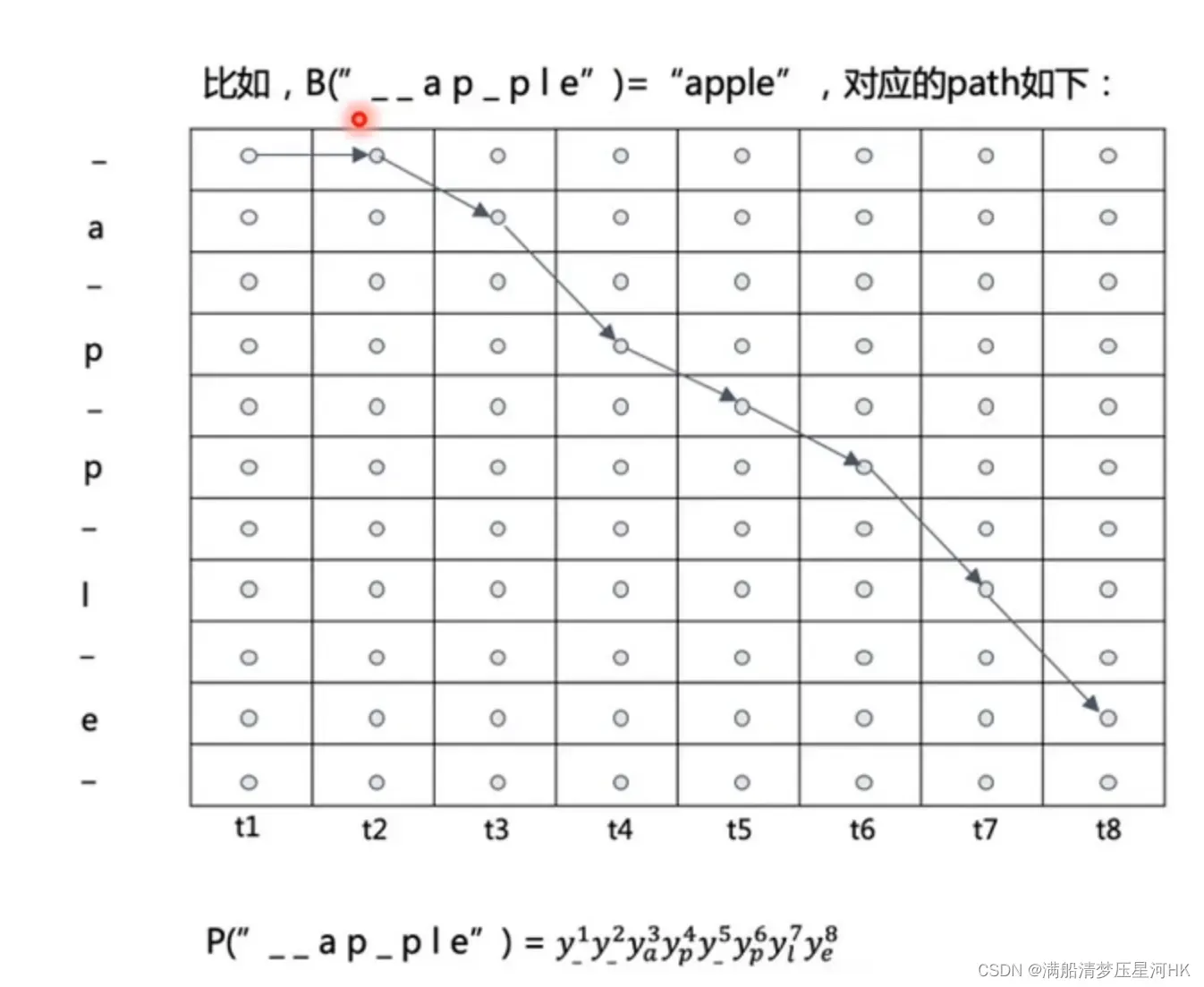
我们只需要定义规则和状态转移方程,每步相乘,即可求出每个可以得到apple的字符概率,再相加求到总概率。
每个方格代表走到这一步的概率

将网格的最后一列的最后两个概率相加,就得到了gt这个标签的概率和。再对这个概率和求交叉熵损失,即得到CTC Loss。
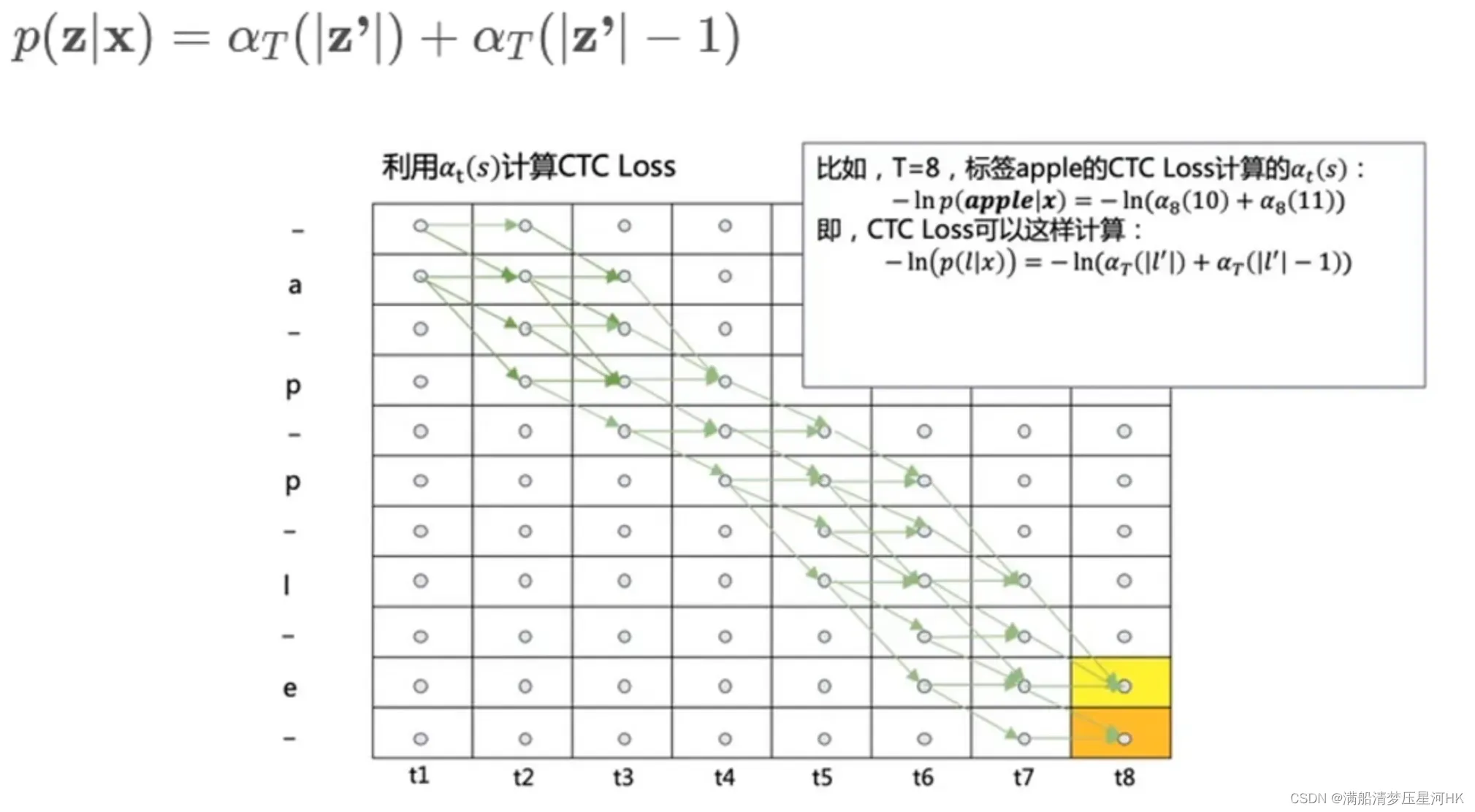
pytorch调用非常简单:
# CTCLoss
criterion = torch.nn.CTCLoss()'
preds = crnn(image) # [26,bs,37]
preds_size = torch.IntTensor([preds.size(0)] * batch_size) # 26xbs
loss = criterion(preds, text, preds_size, length) # text: gt_len
Reference
bilibili: 【论文复现代码数据集见评论区】7小时精读CRNN,全网最细讲解,带你吃透OCR最常用的识别网络
bilibili: 【文字识别方法之CRNN】
bilibili: 【直觉理解 CTC Loss 动态规划算法】
文章出处登录后可见!