什么是相似度
两个事物的相似程度
常见方法
数据是连续、有序的
向量
用向量表示事物,通常有三种方式计算其相似度:
- 距离
- 夹角
- 相关系数
基于距离的相似度计算
- 闵可夫斯基距离(Minkowski Distance)
-
曼哈顿距离(Manhattan Distance)

-
欧氏距离(Euclidean Distance)

-
切比雪夫距离(Chebyshev Distance)
-
缺点:
- 将各个分量的量纲 (scale),也就是“单位”
- 没有考虑各分量的分布(期望、方差等)
- 马氏距离(Mahalanobis Distance)
有M个样本向量~
,协方差矩阵记为S,均值记为向量μ。
欧氏距离(Euclidean Distance),协方差矩阵是单位矩阵(各个样本向量之间独立同分布)
标准化欧氏距离(Standardized Euclidean distance),协方差矩阵是对角矩阵
- 兰氏距离(Lance Williams Distance)
基于夹角的相似度计算
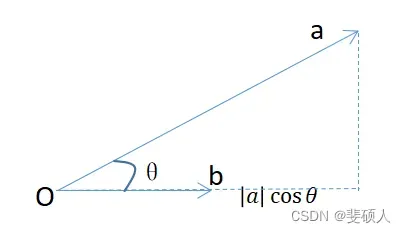
- 点积(投影)
可以反映一个向量在另一个向量上投影的长度(标量)
- 余弦相似度(Cosine Similarity)
两个向量之间的夹角大小
- Tanimoto系数 (Tanimoto Coefficient)(广义Jaccard相似系数)
基于相关系数的相似度计算
- 皮尔逊相关系数 (Pearson Correlation Coefficient)
消除量纲的影响
当两个向量均值都为0时,皮尔逊相对系数等于余弦相似性。
数据是离散、无序的
集合
事物使用集合表示时,用
交并补计算其相似度
-
汉明距离(Hamming Distance)(信号距离)
将其中一个字符串变为另外一个字符串所需要的最小替换次数。 -
杰卡德相似系数 (Jaccard similarity coefficient)
两个集合的交集元素在并集中所占的比例
-
杰卡德距离(Jaccard distance)
用两个集合中不同元素占所有元素的比例,杰卡德相似系数的补。
分布
- KL散度(Kullback-Leibler Divergence)
相对熵,表示两个随机分布之间的相似性。
KL散度大于等于0,当p=q时等于0;KL散度不满足对称性。
适用场景
- 数据是离散无序的、还是连续有序的
- 数据量纲影响大小,大的话使用皮尔逊相关系数
- 数据密集程度,数据密集、类似聚类问题使用距离类方法,数据稀疏使用角度类方法
相关文章:
文章出处登录后可见!
已经登录?立即刷新